
В OpenMP переменные в параллельных областях программы разделяются на два основных класса:
* SHARED (общие; под именем A все нити видят одну переменную)
* PRIVATE (приватные; под именем A каждая нить видит свою переменную).
Отдельные правила определяют поведение переменных при входе и выходе из параллельной области или параллельного цикла: REDUCTION, FIRSTPRIVATE, LASTPRIVATE, COPYIN.
По умолчанию, все COMMON-блоки, а также переменные, порожденные вне параллельной области, при входе в эту область остаются общими (SHARED). Исключение составляют переменные - счетчики итераций в цикле, по очевидным причинам. Переменные, порожденные внутри параллельной области, являются приватными (PRIVATE). Явно назначить класс переменных по умолчанию можно с помощью клаузы DEFAULT.
SHARED
Применяется к переменным, которые необходимо сделать общими.
PRIVATE
Применяется к переменным, которые необходимо сделать приватными. При входе в параллельную область для каждой нити создается отдельный экземпляр переменной, который не имеет никакой связи с оригинальной переменной вне параллельной области.
THREADPRIVATE
Применяется к COMMON-блокам, которые необходимо сделать приватными. Директива должна применяться после каждой декларации COMMON-блока.
FIRSTPRIVATE
Приватные копии переменной при входе в параллельную область инициализируются значением оригинальной переменной.
LASTPRIVATE
По окончании параллельно цикла или блока параллельных секций, нить, которая выполнила последнюю итерацию цикла или последнюю секцию блока, обновляет значение оригинальной переменной.
REDUCTION(+:A)
Обозначает переменную, с которой в цикле производится reduction-операция (например, суммирование). При выходе из цикла, данная операция производится над копиями переменной во всех нитях, и результат присваивается оригинальной переменной.
COPYIN
Применяется к COMMON-блокам, которые помечены как THREADPRIVATE. При входе в параллельную область приватные копии этих данных инициализируются оригинальными значениями.
9)Способы синхронизации работы параллельных потоков.
Именованные и неименованные секции синхронизации.
Атомарные операции.
Виды секций исполняемых в одном потоке.
При одновременном выполнении нескольких потоков часто возникает необходимость их синхронизации. OpenMP поддерживает несколько типов синхронизации, помогающих во многих ситуациях.
Один из типов — неявная барьерная синхронизация, которая выполняется в конце каждого параллельного региона для всех сопоставленных с ним потоков. Механизм барьерной синхронизации таков, что, пока все потоки не достигнут конца параллельного региона, ни один поток не сможет перейти его границу.
Неявная барьерная синхронизация выполняется также в конце каждого блока #pragma omp for, #pragma omp single и #pragma omp sections. Чтобы отключить неявную барьерную синхронизацию в каком-либо из этих трех блоков разделения работы, укажите раздел nowait:
#pragma omp parallel
{
#pragma omp for nowait
for(int i = 1; i < size; ++i)
x[i] = (y[i-1] + y[i+1])/2;
}
Как видите, этот раздел директивы распараллеливания говорит о том, что синхронизировать потоки в конце цикла for не надо, хотя в конце параллельного региона они все же будут синхронизированы.
Второй тип — явная барьерная синхронизация. В некоторых ситуациях ее целесообразно выполнять наряду с неявной. Для этого включите в код директиву #pragma omp barrier.
В качестве барьеров можно использовать критические секции. В Win32 API для входа в критическую секцию и выхода из нее служат функции EnterCriticalSection и LeaveCriticalSection. В OpenMP для этого применяется директива #pragma omp critical [имя]. Она имеет такую же семантику, что и критическая секция Win32, и опирается на EnterCriticalSection. Вы можете использовать именованную критическую секцию, и тогда доступ к блоку кода является взаимоисключающим только для других критических секций с тем же именем (это справедливо для всего процесса). Если имя не указано, директива ставится в соответствие некоему имени, выбираемому системой. Доступ ко всем неименованным критическим секциям является взаимоисключающим.
В параллельных регионах часто встречаются блоки кода, доступ к которым желательно предоставлять только одному потоку, — например, блоки кода, отвечающие за запись данных в файл. Во многих таких ситуациях не имеет значения, какой поток выполнит код, важно лишь, чтобы этот поток был единственным. Для этого в OpenMP служит директива #pragma omp single.
Иногда возможностей директивы single недостаточно. В ряде случаев требуется, чтобы блок кода был выполнен основным потоком, — например, если этот поток отвечает за обработку GUI и вам нужно, чтобы какую-то задачу выполнил именно он. Тогда применяется директива #pragma omp master. В отличие от директивы single при входе в блок master и выходе из него нет никакого неявного барьера.
Чтобы завершить все незавершенные операции над памятью перед началом следующей операции, используйте директиву #pragma omp flush, которая эквивалентна внутренней функции компилятора _ReadWriteBarrier.
Учтите, что OpenMP-директивы pragma должны обрабатываться всеми потоками из группы в одном порядке (или вообще не обрабатываться никакими потоками). Таким образом, следующий пример кода некорректен, а предсказать результаты его выполнения нельзя (вероятные варианты — сбой или зависание системы):
#pragma omp parallel
{
if(omp_get_thread_num() > 3)
{
#pragma omp single // код, доступный не всем потокам
x++;
}
}
Директивы синхронизации
#pragma omp master
{
.
}
MASTER... END MASTER
Определяет блок кода, который будет выполнен только master-ом (нулевой нитью).
Вход/выход из критического интервала запрещены.
#pragma omp critical[name]
{
.
}
CRITICAL... END CRITICAL
Определяет критическую секцию, то есть блок кода, который не должен выполняться одновременно двумя или более нитями.
name – имя критического интервала. Имя – глобальный идентификатор. Различные критические интервала с одним именем обрабатываются как одна и таже область (критический интервал).
Вход/выход из критического интервала запрещены.
#pragma omp barrier
BARRIER
Определяет точку барьерной синхронизации, в которой каждая нить дожидается всех остальных. Наименьшая инструкция, которая содержит barrier должна быть структурным блоком. barrier не может быть в for и sections.
Неверно:
for(x ==0)
#pragma omp barrier
Верно:
for(x ==0)
{ #pragma omp barrier
}
#pragma omp atomic
x binop = exper;
x++
++x
x--
--x
binop - +,*,-,/,&,^,\,>>,<<,or;
exper – скалярное выражение.
ATOMIC
Определяет переменную в левой части оператора "атомарного" присваивания, которая должна корректно обновляться несколькими нитями.
#pragma omp ordered
ORDERED... END ORDERED
Определяет блок внутри тела цикла, который должен выполняться в том порядке, в котором итерации идут в последовательном цикле. Может использоваться для упорядочения вывода от параллельных нитей.
#pragma omp flush(list)
FLUSH
Явно определяет точку, в которой реализация должна обеспечить одинаковый вид памяти для всех нитей. Неявно FLUSH присутствует в следующих директивах: BARRIER, CRITICAL, END CRITICAL, DO, END DO, PARALLEL, END PARALLEL, SECTIONS, END SECTIONS, SINGLE, END SINGLE, ORDERED, END ORDERED. В целях синхронизации можно также пользоваться механизмом замков (locks).
Процедуры для синхронизации на базе замков
В качестве замков используются общие переменные типа INTEGER (размер должен быть достаточным для хранения адреса). Данные переменные должны использоваться только как параметры примитивов синхронизации.
OMP_INIT_LOCK(var) / OMP_DESTROY_LOCK(var)
Инициализирует замок, связанный с переменной var.
OMP_SET_LOCK
Заставляет вызвавшую нить дождаться освобождения замка, а затем захватывает его.
OMP_UNSET_LOCK
Освобождает замок, если он был захвачен вызвавшей нитью.
OMP_TEST_LOCK
Пробует захватить указанный замок. Если это невозможно, возвращает. FALSE.
10) Основные параметры запуска параллельной программы: количество параллельных ветвей, ускорение, эффективность. Закон Амдала.
Параллелизм независимых ветвей – количество независимых частей (участков, ветвей) задачи, которые при наличии в ВС соответствующих средств могут выполняться параллельно (одновременно одна с другой). Ускорением параллельного алгоритма (Sp) называют отношение времени выполнения алгоритма на одном процессоре (t1) ко времени выполнения на системе из процессоров (tn). Эффективностью параллельного алгоритма называют отношение его ускорения к числу процессоров, на котором это ускорение получено.
Эффективность выполнения параллельных программ на многопроцессорных ЭВМ с распределенной памятью определяется следующими основными факторами:
* степенью распараллеливания программы - долей параллельных вычислений в общем объеме вычислений;
* равномерностью загрузки процессоров во время выполнения параллельных вычислений;
* временем, необходимым для выполнения межпроцессорных обменов;
* степенью совмещения межпроцессорных обменов с вычислениями.
главную характеристику эффективности параллельного выполнения - коэффициент эффективности, равный отношению полезного времени к общему времени использования процессоров, которое в свою очередь равно произведению времени выполнения программы на многопроцессорной ЭВМ (максимальное значение среди времен выполнения программы на всех используемых ею процессорах) на число используемых процессоров. Предположим, что в вашей программе доля операций, которые нужно выполнять последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в значениях f соответствуют полностью параллельным (f=0) и полностью последовательным (f=1) программам. Так вот, для того, чтобы оценить, какое ускорение S может быть получено на компьютере из 'p' процессоров при данном значении f, можно воспользоваться законом Амдала:
S<=1/(f+(1-f)/p)
Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно вне зависимости от качества реализации параллельной части кода и числа используемых процессоров (ясно, что 10 получается только в том случае, когда время исполнения параллельной части равно 0).
11) Использование комбинации технологии MPI и OpenMP. Преимущества. Порядок работы параллельного приложения. Возможные варианты вложенности параллельных технологий
Характеристики программной модели
Комбинированное программирование может быть полезным и на отдельной SMP системе, используя преимущества обеих моделей. Эта секция кратко резюмирует две данные парадигмы и рассматривает их потенциальные преимущества и недостатки.
MPI
Модель программирования с передачей сообщений является моделью с распределённой памятью с внешним контролем параллелизма. MPI [17] совместим как с распределённой, так и с общей структурой памяти, и позволяет статическое планирование задач. Внешний параллелизм часто обеспечивает большую эффективность, и количество оптимизированных коллективных процедур коммуникации доступно для оптимальной эффективности. Проблемы с размещением данных наблюдаются редко, и синхронизация происходит неявно с вызовами подпрограмм и, следовательно, естественно минимизированы. Однако MPI имеет некоторые недостатки. Декомпозиция, разработка и отладка приложений могут потребовать значительных временных затрат, и существенные изменения в коде часто необходимы. Коммуникации могут потребовать дополнительных расходов, и кодовая степень детализации часто должна быть большой, чтобы минимизировать время ожидания. Наконец, глобальные операции могут быть очень дорогими.
OpenMP
OpenMP – промышленный стандарт [19] для программирования общей памяти. Основанный на комбинации директив компилятора, библиотечных процедур и переменных окружающей среды это используется, чтобы определить параллелизм на машинах совместно используемой памяти. Коммуникация неявна, и OpenMP приложения относительно легки в имплементации. Теоретически, OpenMP лучше использует архитектуру общей памяти. Программирование времени исполнения возможно, и потому эффективен как мелкозернистый, так и крупнозернистый параллелизм. Коды OpenMP, однако, будут исполняться только на машинах с общей памятью, и политика размещения данных может стать причиной проблем. Для крупнозернистого параллелизма часто требуется стратегия параллелизации, подобная стратегии MPI, а также внешняя синхронизация.
Комбинированное программирование
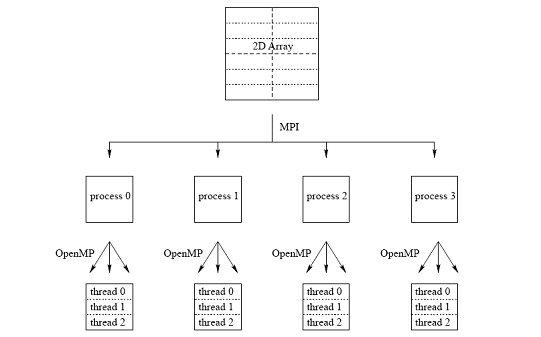
Применяя комбинированную модель программирования, мы должны использовать в своих интересах выгоды обеих моделей. Например, комбинированная программа может позволить политике размещения данных MPI применяться одновременно с мелкозернистым параллелизмом OpenMP. Большинство комбинированных приложений реализуют иерархическую модель; параллелизация MPI находится на высшем уровне, и параллелизация OpenMP располагается ниже. Например, на рис. 1 показана двухмерная сетка, которая геометрически разделена между четырьмя процессами MPI. Эти подмассивы были дополнительно разделены между тремя процессами OpenMP. Данная модель близко отображается на архитектуру SMP кластера, параллелизация MPI происходит между узлами SMP, и параллелизация OpenMP – внутри узлов. В то время, как большинство комбинированных программ реализуют этот тип модели, множество авторов описывают неиерархические модели (см. секцию 2). Например, пересылка сообщений может использоваться в пределах кода, когда это относительно просто осуществить, и параллелизм общей памяти там, где пересылка сообщений трудноосуществима [8].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
