
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 7. Основы статистики и исследование данных
Профессиональное использование возможностей программы SPSS предполагает наличие основательных знаний в области статистики. Мы рассмотрим лишь некоторые основные понятия, при том, в сугубо практическом, можно даже сказать – технологическом аспекте. Т. е. какие процедуры следует выполнить и как их провести, прежде чем приступить к собственно анализу данных.
7.1. Предварительные условия для проведения статистического теста
В число этих процедур входит, в первую очередь, предварительные оценки, которые выполняются перед проведением любого статистического теста:
– классификация переменных по статистическим шкалам
– проверка наличия нормального распределения
– выделение независимых и зависимых выборок.
7.1.1. Типы статистических шкал
В эмпирическом исследовании могут встречаться, к примеру, следующие переменные (указано их наиболее вероятное кодирование):
Пол | 1. Мужской. |
2. Женский. | |
Семейное положение | 1. Холост/не замужем. |
2. Женат/замужем. | |
3. Вдовец/вдова. | |
4. Разведен(а). | |
Курение | 1. Некурящий. |
2. Изредка курящий. | |
3. Интенсивно курящий. | |
4. Очень интенсивно курящий. | |
Месячный доход | 1. До 10000 руб. |
2. 10001 ‑ 15000 руб. | |
3. Более 15000 руб. | |
Коэффициент интеллекта (I. Q.) | |
Возраст, лет |
Рассмотрим сначала графу «Пол». Мы видим, что назначение соответствия цифр 1 и 2 обоим полам абсолютно произвольно, их можно было поменять местами или обозначить совершенно случайными кодами.
Из данной кодировки совершенно не следует, что женщины стоят на ступеньку ниже мужчин, или что мужчины значат меньше, чем женщины. Следовательно, отдельным числам не соответствует никакого эмпирического значения. В этом случае говорят о переменных, относящихся к номинальной шкале. В нашем примере рассматривается переменная с номинальной шкалой, имеющая две категории. Такая переменная имеет еще одно название ‑- дихотомическая.
Такая же ситуация и с переменной «Семейное положение». Здесь также соответствие между числами и категориями семейного положения не имеет никакого эмпирического значения. Но в отличии от Пола, эта переменная не является дихотомической ‑ у нее четыре категории вместо двух.
Возможности обработки переменных, относящихся к номинальной шкале очень ограничены. Собственно говоря, можно провести только частотный анализ таких переменных. К примеру, расчет среднего значения для переменной «Семейное положение», совершенно бессмысленен. Переменные, относящиеся к номинальной шкале часто используются для группировки, с помощью которых совокупная выборка разбивается по категориям этих переменных. В частичных выборках проводятся одинаковые статистические тесты, результаты которых затем сравниваются друг с другом.
В качестве следующего примера рассмотрим переменную «Курение». Здесь кодовым цифрам присваивается эмпирическое значение в том порядке, в котором они расположены в списке. Переменная Курение, в итоге, сортирована в порядке значимости снизу вверх: умеренный курильщик курит больше, нежели некурящий, а сильно курящий ‑ больше, чем умеренный курильщик и т. д. Такие переменные, для которых используются численные значения, соответствующие постепенному изменению эмпирической значимости, относятся к порядковой шкале.
Однако эмпирическая значимость этих переменных не зависит от разницы между соседними численными значениями. Так, несмотря на то, что разница между значениями кодовых чисел для некурящего и изредка курящего и изредка курящего и интенсивно курящего в обоих случаях равна единице, нельзя утверждать, что фактическое различие между некурящим и изредка курящим и между изредка курящим и интенсивно курящим одинаково. Для этого данные понятия слишком расплывчаты.
К классическими примерами переменных с порядковой шкалой относятся также переменные, полученные в результате объединения величин в классы, как «Месячный доход» в нашем примере.
Кроме частотного анализа, переменные с порядковой шкалой допускают также вычисление определенных статистических характеристик, таких как медианы. В некоторых случаях возможно вычисление среднего значения. Если должна быть установлена связь (корреляция) с другими переменными такого рода, для этой цели можно использовать коэффициент ранговой корреляции.
Для сравнения различных выборок переменных, относящихся к порядковой шкале, могут применяться непараметрические тесты, формулы которых оперируют рангами.
Рассмотрим теперь коэффициент интеллекта (IQ). Не только его абсолютные значения отображают порядковое отношение между респондентами, но и разница между двумя значениями также имеет эмпирическую значимость. Например, если у респондента «А» IQ равен 80, у респондента «Б» ‑ 120 и у респондента «В» ‑ 160, можно сказать, что респондент «Б» в сравнении с респондентом «А» настолько же интеллектуальнее насколько респондентом «В» в сравнении с респондентом «Б» (а именно ‑ на 40 единиц IQ). Однако, основываясь только на том, что значение IQ у респондента «А» в два раза меньше, чем у респондента «В», исходя из определения IQ нельзя сделать вывод, что последний вдвое умнее первого.
Такие переменные, у которых разность (интервал) между двумя значениями имеет эмпирическую значимость, относятся к интервальной шкале. Они могут обрабатываться любыми статистическим методами без ограничений. Так, к примеру, среднее значение является полноценным статистическим показателем для характеристики таких переменных.
Наконец, мы достигли наивысшей статистической шкалы, на которой эмпирическую значимость приобретает и отношение двух значений. Примером переменной, относящейся к такой шкале является возраст: если респонденту «А» 30 лет, а респонденту «Б» 60, можно сказать, что респондент «Б» вдвое старше респондента «А». Шкала, к которой относятся данные называется шкалой отношений. К этой шкале относятся все интервальные переменные, которые имеют абсолютную нулевую точку. Поэтому переменные, относящиеся к интервальной шкале, как правило, имеют и шкалу отношений.
Подводя итоги, можно сказать, что существует четыре вида статистических шкал, на которых могут сравниваться численные значения:
Статистическая шкала | Эмпирическая значимость |
Номинальная | Нет |
Порядковая | Порядок чисел |
Интервальная | Разность чисел |
Шкала отношений | Отношение чисел |
На практике, в том числе в SPSS, различие между переменными, относящимися к интервальной шкале и шкале отношений обычно несущественно. То есть в дальнейшем практически всегда речь будет идти о переменных, относящихся к интервальной шкале.
Тем не менее, необходимо четко разбираться в видах статистических шкал и при выборе метода обращать внимание на то, чтобы были определены надлежащие виды шкал.
Уже говорилось, что переменные, относящиеся к номинальной шкале допускают весьма ограниченные возможности для проведения анализа. Исключение в некоторых ситуациях составляют дихотомические переменные. Для них можно, по крайней мере, определять ранговую корреляцию. Если, например, обнаруживается корреляция коэффициента интеллекта с полом, то положительный коэффициент корреляции означает, что женщины интеллектуальнее, чем мужчины. Однако если переменные, относящиеся к номинальной шкале не являются дихотомическими, вычисление коэффициентов ранговой корреляции не имеет смысла.
Итак, мы достаточно подробно разобрали типы статистических шкал, а на практике, в примерах, вы практически уже пробовали использовать разные шкалы. Речь идет о номинальной (Nominal), порядковой (Ordinal), интервальной и метрическая (Scale). Отмечали уже, что в большинстве реальных случаев нет необходимости менять тип шкалы с Scale, устанавливаемый по умолчанию, на какой-либо другой тип.
7.1.2. Проверка закона распределения. Нормальное распределение
Займемся рассмотрением другого вопроса, а именно – характера распределения.
Многочисленные методы, с помощью которых обрабатываются переменные, относящиеся к интервальной шкале, исходят из гипотезы, что их значения подчиняются нормальному распределению. При таком распределении большая часть значений группируется около некоторого среднего значения, по обе стороны от которого частота наблюдений равномерно снижается. Например, если измерить рост мужчин и женщин, образующих какое-нибудь достаточно однородное сообщество (например, этнос, нацию…) и вывести среднее значение (для мужчин и женщин – свои средние величины), то окажется что все реальные роста группируются вокруг этого среднего определенным образом.
В качестве примера рассмотрим нормальное распределение возраста.
· Загрузите файл:
hyper. sav
· Выберите в меню команду:
Graphs (Графики)
Interactive (Интерактивные)
Histogram… (Гистограмма)
Откроется диалоговое окно Create Histogram (Построить гистограмму).
· На вертикальной оси оставьте переменную Count, которая установлена по умолчанию
· Перенесите переменную a (возраст) в окно горизонтальной оси
· На закладке Histogram отметьте опцию Normal Curve
· Запустите процедуру построения гистограммы нажатием кнопки OK
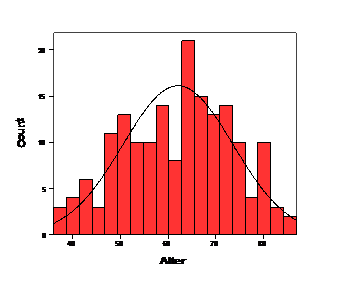
На диаграмме нанесена кривая нормального распределения (т. н. колокол Гаусса). Разумеется, реальное распределение всегда в большей или меньшей степени отклоняется от этой идеальной кривой. Выборки, строго подчиняющиеся нормальному распределению, на практике, как правило, не встречаются. Поэтому почти всегда необходимо выяснить, можно ли реальное распределение считать нормальным и насколько значительно заданное распределение отличается от нормального.
Перед применением любого метода, который предполагает существование нормального распределения, наличие последнего нужно проверять в первую очередь. Поскольку ряд статистических тестов исходят из гипотезы о нормальном распределении. Если же данные не подчиняются нормальному распределению, следует использовать соответствующий непараметрический тест.
Если визуальное сравнение реальной гистограммы с кривой нормального распределения кажется недостаточным, можно применить тест Колмогорова-Смирнова.
· Выберите в меню команду:
Analyze (Анализ)
Nonparametric Tests (Непараметрические тесты)
1-Sample KS (Критерий Колмогорова-Смирнова для одной выборки)
Появится диалоговое окно One Sample Kolomgorov-Smirnov Test (Тест Колмогорова-Смирнова для одной выборки). Предварительно установленной является проверка на нормальное распределение.
· Перенесите переменную a в поле тестируемых переменных.
· Кнопка Options... (Опции) позволяет организовать вывод дополнительных характеристик дескриптивной статистики.
· Щёлкните на кнопке ОК.
В окне просмотра появятся следующие результаты:
Одновыборочный критерий Колмогорова-Смирнова
Alter | ||
N | 174 | |
Нормальные параметры(a, b) | Среднее | 62,11 |
| Стд. отклонение | 11,548 | |
Разности экстремумов | Модуль | ,059 |
| Положительные | ,055 | |
| Отрицательные | -,059 | |
Статистика Z Колмогорова-Смирнова | ,785 | |
Асимпт. знч. (двухсторонняя) | ,569 |
a Сравнение с нормальным распределением.
b Оценивается по данным.
В полученной таблице нас интересует, прежде всего, значимость. Обратите внимание на её величину: 0,569.
Параметр Sig./Знч. (Значимость) – вероятность того, что наблюдаемые различия случайны. Различия между чем? В нашем конкретным случае – различие между исследуемым и нормальным распределением. Величина p < 0.05 (вероятность ошибки) свидетельствует о высокой статистической значимости различий (поскольку чем выше вероятность ошибки, тем меньше значимость).
Итак, отклонение от нормального распределения считается существенным при значении p < 0.05; в этом случае для соответствующих переменных следует применять непараметрические тесты. В нашем примере для переменной a (возраст) значение p = 0,569, и это значит, что вероятность ошибки является высокой, т. е. отклонения нашего распределения от нормального носят случайный характер. Другими словами – отклонение является незначимым. На этом основании мы можем сделать вывод, что значения переменной a хорошо подчиняются нормальному распределению (достоверного различия нет).
Вероятность ошибки, p-уровень, значимость, достоверность отличий – это важная тема, постоянно присутствующая в большинстве методов анализа данных. Поэтому вам необходимо в ней разобраться досконально. Такую возможность дает базовый курс социологии. Мы к ней тоже вернемся чуть позже.
7.1.3. Зависимость и независимость выборок
В ходе анализа данных всегда важно знать являются ли изучаемые выборки зависимыми или независимыми. Что такое зависимость выборок?
Две выборки зависят друг от друга, если каждому значению одной выборки можно закономерным и однозначным способом поставить в соответствие ровно одно значение другой выборки. Аналогично определяется зависимость нескольких выборок.
Чаще всего зависимые выборки возникают, когда проводятся повторные измерения одного и того же параметра, или измерение для нескольких моментов времени. В этом случае зависимые выборки образуются значениями параметров изучаемого процесса, соответствующими различным моментам времени.
Зависимым (также связанным, спаренным) выборкам соответствуют разные переменные, которые могут сопоставляются друг с другом в соответствующем тесте на одной и той же совокупности наблюдений.
Если закономерное и однозначное соответствие между выборками невозможно, эти выборки являются независимыми. Независимые выборки содержат разные наблюдения (например, относящиеся к различным респондентам), которые обычно различаются с помощью групповой переменной, относящейся к номинальной шкале.
7.2. Вероятность ошибки р
Большинство аналитических методов направлено на обнаружение и выявление статистических различий сравниваемых выборок. При этом, одновременно с вычислением величины этих отличий, решается не менее важный вопрос – является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет. Т. е., если, условно говоря, обнаружилось, что а > b, и даже насколько именно a больше b (величина отличия), то тут же надо попытаться объективно оценить достоверность этого вывода, насколько этот вывод отражает действительное различие, а не случайное соотношение.
Например, если сравниваются средние значения для двух выборок, то можно сформулировать две предварительных гипотезы:
· Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений
· Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями
В аналитической статистике разработаны методы вычисления так называемой вероятности ошибки. Это вероятность равна проценту ошибки, которую можно допустить, отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической социологии, в статистике она почему-то часто выражается в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятность ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения, тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности. Высказывания, имеющие вероятность ошибки р <= 0.5, называются значимыми; высказывания с вероятностью ошибки р <= 0.01 – очень значимыми, а высказывания с вероятностью ошибки р <= 0.001 – максимально значимыми или сверхзначимыми. В литературе такие ситуации обозначают одной, двумя или тремя звездочками.
Вероятность ошибки | Значимость | Обозначение |
р > 0.05 | Не значимая | ns |
р <= 0.05 | Значимая | * |
р <= 0.01 | Очень значимая | ** |
р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях.
В связи с выбором той или иной гипотезы связаны соответствующие ошибки. Когда нулевая гипотеза отвергается (хотя она верна), говорят об ошибке первого рода. Когда нулевая гипотеза принимается, хотя она ложна, приводит к ошибке второго рода.
Вероятность ошибки первого рода прямо пропорциональна вероятности ошибки р, точнее – они равны. Вероятность ошибки второго рода, наоборот, обратно пропорциональна вероятности p и тем меньше, чем больше вероятность ошибки р. В математике это выражается следующим соотношением:
1 – р
С учётом всего сказанного про значимость, вернемся к примеру с проверкой распределения и его сравнения с нормальным распределением.
7.3. Статистические методы
В целом, как мы уже говорили, исследование имеет свою логику, свою последовательность действий. Часть из них мы уже рассмотрели и попробовали практически. Поскольку нас интересуют обработка уже полученных данных, постольку этапы разработки программы исследования, инструментария, опроса и всего, связанного с полевым этапом, мы просто оставляем без внимания.
Мы с вами выделили такой этап, как структурирование, ввод и проверка данных. Это блок вопросов, связанных с определением переменных, выбором шкал для переменных, кодированием, составлением матрицы БД, вводом данных, проверкой качества данных и их ввода, чисткой массива первичных данных, наконец – ремонтом БД.
После этого уже можно тестировать данные. И первой, что мы делаем – проверяем характер распределения для тех переменных, которые хотим анализировать.
Следующий этап – собственно статистическая обработка введенных данных. Для выполнения этой работы в SPSS существует набор методов описательного (или дескриптивный) анализа.
И наконец – аналитическая статистика. То, ради чего все затевалось (не считая, конечно, конкретные потребности реального заказчика и исследовательский замысел).
Что же такое статистическая обработка и анализ данных? Сейчас немного чуть более подробно, а все детали и технология – в ходе изучения конкретных методов.
7.3.1. Описательный (дескриптивный) анализ
Этот вид анализа включает описательное представление отдельных переменных. К нему относятся:
– создание частотной таблицы,
– вычисление статистических характеристик,
– или графическое представление.
Основные инструменты дескриптивного анализа SPSS сосредоточены в меню Analyze (Анализ) / Descriptive Statistics (Дескриптивные статистики). Откройте его, чтобы посмотреть, что там есть.
Частотные таблицы строятся для номинальных и порядковых переменных. Почему для них? Потому что они имеют ограниченное и притом – не очень большое число категорий. Если какая-либо переменная метрического типа тоже имеет не слишком много значений, то частотный анализ вполне применим и для этой переменной. Иначе, при большом количестве значений этой переменной частотный анализ теряет смысл. Например – возраст респондентов. Или рост. В этих случаях оригинальных значений может быть бесконечное число (в зависимости от точности измерений). Но если мы опрашиваем респондентов в узком диапазоне возможных значений (например, при выяснении потребления инъекционных наркотиков целевой аудиторией являлись подростки от 13 до 18 лет) частотное распределение имеет смысл (в моем примере – всего 6 возрастов – от 13 до 18; это вполне обозримо и к тому же каждая группа будет статистически значима, даже если они все наберут одинаковые веса – примерно по 16%). Попробуйте, например, вывести таблицу частотного распределения возрастов (переменная a) в открытом файле hyper. Что мы получили? Порядка 50 возрастов-категорий, каждая из которых набрала (max) 5,2%. Что с этой величиной делать? Она на уровне статистической ошибки самого исследования в целом. И потом, чем отличается, например 36 лет от 37? Какой глубинной биологический, психологический или социальный смысл стоит за разницей в 1 год? Именно поэтому переходят к возрастным группам – укрупненные категории, относительно однородные внутри и различающиеся между собой. Посчитайте теперь линейное распределение для переменной ak (возрастные группы). Всего четыре группы, с которыми удобно работать в ходе анализа и набравшие статистически значимые веса (min = 13.8%). Кроме того, это разбиение, конечно, должно быть как-то обоснованно идеологически.
Однако, для переменных, относящихся к номинальной шкале, нельзя вычислить никаких значимых статистических характеристик.
Для порядковых переменных чаще всего вычисляют средние значения, медианы, стандартное отклонение или стандартную ошибку.
Характеристики, вычисляемые для переменных, относящихся к интервальной шкале, зависят от характера распределения. В дальнейшем изучении возможностей SPSS мы поймем и увидим – какие это характеристики.
Что же касается графиков (диаграмм, гистограмм), то их можно строить в большом разнообразии и количестве для переменных, относящихся ко всем статистическим шкалам.
7.3.2. Аналитическая статистика
Практически любой статистический анализ наряду с чисто описательными операциями включает те или иные аналитические методы (или тесты значимости), при применении которых в конечном счете определяется вероятности ошибки р (та самая).
Большая группа тестов служит для выяснения того, различаются ли две или более различных выборки по своим средним значениям или медианам. При этом учитывается разница между независимыми выборками (разные наблюдения) и зависимыми выборками (разные переменные).
В зависимости количества выборок (две или более), от того, зависимы ли выборки или нет, относятся ли переменные к интервальной или порядковой шкале, подчиняются ли нормальному распределению – применяются специализированные тесты.
Очень часто встречается ситуация, когда сравниваются различные группы наблюдений или значений переменных, относящихся к номинальной шкале. В этом случае строятся таблицы сопряженности.
Другая группа тестов касается исследования связей между двумя переменными, то есть выявления корреляций и восстановления регрессий.
Кроме этих довольно простых статистических методов существуют также более сложные методы многомерного анализа, в которых обычно одновременно используется очень много переменных. Если требуется свести большое количество переменных к меньшему количеству "пучков переменных", называемых факторами, то проводится факторный анализ. Если же необходимо некоторым образом объединить имеющиеся наблюдения, образовав из них кластеры, то применяется кластерный анализ.
В определенной группе многомерных тестов вводится различие между зависимой переменной, называемой также целевой и несколькими независимыми переменными (переменными влияния или прогнозирования).
Кроме упомянутых, существует еще достаточно много других методов анализа.
