

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Стратегия размещения данных
в многопроцессорных системах
с симметричной иерархической архитектурой[†]
Технический отчет OMEGA13
,
В работе предлагается новый подход к размещению данных и балансировке загрузки в многопроцессорных системах реляционных баз данных с иерархической архитектурой. В основе описываемой стратегии лежит модель симметричной многопроцессорной иерархической системы. Стратегия предполагает использование горизонтальной фрагментации отношений и частичного зеркалирования дисков по узлам и уровням многопроцессорной иерархии. При этом каждый фрагмент на логическом уровне разбивается на равномощные сегменты, являющиеся наименьшей единицей репликации данных и балансировки загрузки. Размер реплицируемой части фрагмента на каждом узле задается коэффициентом репликации. Предлагаемые методы размещения данных ориентированы на использование в кластерах и Grid системах.
1.[Л. Б.1] Ведение
В настоящее время все большее распространение получают иерархические архитектуры параллельных систем баз данных [1[Л. Б.2] ]. Это связано с тем, что современные многопроцессорные системы в большинстве случаев организуются по иерархическому принципу. Действительно, большая часть суперкомпьютеров сегодня имеют двухуровневую кластерную архитектуру. В соответствии с данной архитектурой многопроцессорная система строится как набор однородных вычислительных модулей, соединенных высокоскоростной сетью. При этом каждый вычислительный модуль является в свою очередь многопроцессорной системой с разделяемой памятью. Если в системе используются еще и многоядерные процессоры, то мы получаем третий уровень иерархии.
Другим источником многопроцессорных иерархий являются Grid-технологии [2], позволяющие объединять несколько различных суперкомпьютеров в единую вычислительную систему. Подобная Grid-система будет иметь многоуровневую иерархическую структуру. На нижних уровнях иерархии располагаются процессоры отдельных кластерных систем, соединенные высокоскоростной внутренней сетью. На верхних уровнях располагаются вычислительные системы, объединенные корпоративной сетью. Высший уровень иерархии может представлять сеть Интернет.
Проблеме распределения данных и связанной с ней проблеме балансировки загрузки в параллельных системах баз данных без совместного использования ресурсов посвящено большое количество работ (см., например, [3,4,5,6]), однако данная проблематика в контексте иерархических многопроцессорных систем до настоящего времени практически не исследовалась.
Отчет организован следующим образом. В разделе 2 вводится формальное определение симметричной многопроцессорной иерархии. Раздел 3 посвящен описанию механизма фрагментации и балансировки загрузки, основанному на введении понятия сегмента. В разделе 4 описывается механизм репликации данных на основе сегментов. Вводится понятие коэффициента репликации. В пункте 4.2 описывается метод частичного зеркалирования, использующий функцию репликации, сопоставляющую каждому уровню иерархии определенный коэффициент репликации. Доказываются теоремы, дающие оценки для суммарного размера реплик. Пункт 4.3 посвящен проблеме выбора функции репликации. Вводиться понятие регулярной иерархии. Доказываются теоремы, дающие оценки для трудоемкости формирования реплик при отсутствии помех. В разделе 5 суммируются полученные результаты и обсуждаются направления дальнейших исследований.
2. Симметричные иерархии
Иерархические многопроцессорные конфигурации характеризуются большим многообразием архитектур [1]. Архитектура многопроцессорной системы зачастую является определяющим фактором при разработке стратегии размещения данных. В этом разделе мы построим модель иерархической многопроцессорной системы баз данных, которую мы назвали симметричной. Симметричная модель описывает достаточно широкий класс реальных систем и является математическим фундаментом для определения стратегии распределения данных, предлагаемой в настоящей работе.
В основе симметричной модели лежит понятие DM‑дерева, введенное в работе [7]. DM‑дерево является ориентированным деревом, представляющим собой абстракцию иерархической многопроцессорной системы баз данных.
Для произвольного DM–дерева Т мы будем обозначать множество всех его узлов как ![]() , множество всех дуг как
, множество всех дуг как ![]() . Множество узлов (модулей)
. Множество узлов (модулей) ![]() любого DM‑дерева
любого DM‑дерева ![]() делиться на три непересекающихся подмножества, называемые классами:
делиться на три непересекающихся подмножества, называемые классами:
![]() ‑ класс «процессорные модули»;
‑ класс «процессорные модули»;
![]() ‑ класс «дисковые модули»;
‑ класс «дисковые модули»;
![]() ‑ класс «модули сетевых концентраторов».
‑ класс «модули сетевых концентраторов».
С каждым узлом 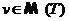 в DM‑дереве T связывается коэффициент трудоемкости
в DM‑дереве T связывается коэффициент трудоемкости ![]() , являющийся вещественным числом, большим либо равным единицы. Коэффициент трудоемкости определяет время, необходимое узлу для обработки некоторой порции данных. В качестве такой порции данных может фигурировать, например, кортеж.
, являющийся вещественным числом, большим либо равным единицы. Коэффициент трудоемкости определяет время, необходимое узлу для обработки некоторой порции данных. В качестве такой порции данных может фигурировать, например, кортеж.
Дадим определение изоморфизма двух DM‑деревьев.
DM‑деревья ![]() и
и ![]() называются изоморфными, если существуют взаимно однозначное отображение
называются изоморфными, если существуют взаимно однозначное отображение ![]() множества
множества ![]() на множество
на множество ![]() и взаимно однозначное отображение
и взаимно однозначное отображение ![]() множества
множества ![]() на множество
на множество ![]() такие, что:
такие, что:
1. 1) узел ![]() является конечным узлом дуги
является конечным узлом дуги ![]() в дереве
в дереве ![]() тогда и только тогда, когда узел
тогда и только тогда, когда узел ![]() является конечным узлом дуги
является конечным узлом дуги ![]() в дереве
в дереве ![]() ;
;
2. 2) узел ![]() является начальным узлом дуги
является начальным узлом дуги ![]() в дереве
в дереве ![]() тогда и только тогда, когда узел
тогда и только тогда, когда узел ![]() является начальным узлом дуги
является начальным узлом дуги ![]() в дереве
в дереве ![]() ;
;
3. 3) ![]() ;
;
4. 4) ![]() ;
;
5. 5) ![]() ;
;
6. 6) ![]() .
.
Упорядоченную пару отображений ![]() будем называть изоморфизмом DM‑дерева
будем называть изоморфизмом DM‑дерева ![]() на DM‑дерево
на DM‑дерево ![]() .
.
Рис.[Л. Б.4] 1[Л. Б.5] . Два DM‑дерева, не являющиеся |

 [Л. Б.3]
[Л. Б.3] Заметим, что условие 2 из определения изоморфизма не является избыточным. Это подтверждается примером, изображенным на Рис. 1[Л. Б.6] . Действительно, используя нумерацию узлов и дуг, указанную на Рис. 1, определим отображения f и g следующим образом:
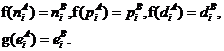
Очевидно, что отображения f и g удовлетворяют всем требованиям изоморфизма, кроме условия 2 (мы полагаем коэффициент трудоемкости для всех узлов равным 1). Однако мы не можем признать ![]() изоморфизмом DM‑дерева
изоморфизмом DM‑дерева ![]() на DM‑дерево
на DM‑дерево ![]() , так как здесь нарушается отношение подчиненности узлов (узел w является подчиненным по отношению к узлу v, если существует дуга, направленная от w к v). Действительно, в DM‑дереве
, так как здесь нарушается отношение подчиненности узлов (узел w является подчиненным по отношению к узлу v, если существует дуга, направленная от w к v). Действительно, в DM‑дереве ![]() узел
узел ![]() подчинен узлу
подчинен узлу ![]() , а в DM‑дереве
, а в DM‑дереве ![]() узел
узел 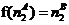 имеет в подчинении узел
имеет в подчинении узел ![]() .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
