

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
- общий домен (а) явные внешние ключи (б)
Если остающиеся внешние ключи все в одном домене, т. е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей; все эти столбцы могут содержать неопределенные значения.
Общий домен | Явные внешние ключи |
Преимущества | |
Нужно только два столбца | Условия соединения - явные |
Недостатки | |
Оба дополнительных атрибута должны использоваться в соединениях | Слишком много столбцов |
Альтернативные модели сущностей:
Вариант 1 (плохой)

Вариант 2 (существенно лучше, если подтипы действительно существуют) 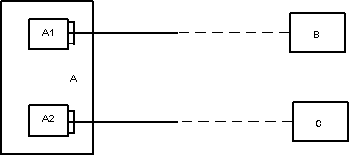
Вариант 3 (годится при наличии осмысленного супертипа D).
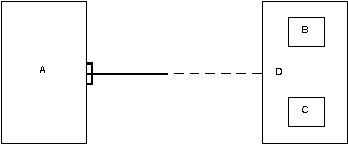
Две классические экспериментальные системы
Лекция 7. System R: общая организация системы, основы языка SQL
Система управления реляционными базами данных System R разрабатывалась в исследовательской лаборатории фирмы IBM в 1975-1979 г. г. Эта работа оказала революционизирующее влияние на развитие теории и практики реляционных систем во всем мире. Именно System R практически доказала жизнеспособность реляционного подхода к управлению базами данных.
После успешного завершения работ по созданию этой системы и получения экспериментальных результатов ее использования был разработан целый ряд коммерчески доступных реляционных систем, в том числе и на основе непосредственного развития System R (возможности одной из коммерчески доступных реляционных систем - DB2 - описываются в переведенной на русский язык книге К. Дейта "Руководство по реляционной СУБД DB2). Исключительно важен опыт, приобретенный при разработке этой системы. Практически во всех более поздних реляционных СУБД в той или иной степени используются методы, примененные в System R.
После завершения разработки System R фирма IBM активно продолжала работы по реляционным СУБД, причем в нескольких направлениях. Первое направление мы уже отмечали - разработка коммерческих реляционных СУБД. Второе направление - построение распределенной реляционной СУБД на основе идей System R. Экспериментальный вариант такой системы, System R*, был успешно разработан в IBM. Эта работа также существенно обогатила опыт исследователей и разработчиков распределенных СУБД. Наконец, третье направление - исследование и разработка реляционных систем, предназначенных для нетрадиционных приложений.
Организации СУБД System R посвящена обширная библиография. Для информации мы приводим ее в конце этой лекции. Хотя официально разработка этой системы началась в 1975 г., первые публикации, связанные с этой системой, появились еще в 1974 г. В частности, в одной из первых публикаций была предложена основа базового языка System R SQL (тогда этот язык назывался SEQUEL, и до сих пор многие называют его именно так; кстати, разработчики System R (а теперь и компания Oracle) рекомендуют произносить название SQL именно как SEQUEL). Поскольку публикации появлялись по ходу практической реализации системы, каждая из них отражает состояние дел (идейное и практическое) именно на том этапе работы, когда была написана соответствующая статья. Некоторые идеи и представления, естественно, изменялись по ходу работы. Сравнительно законченное представление о системе в целом дают только заключительные публикации. С другой стороны, многие интересные моменты совершенно не отражены в этих последних статьях, и мы постараемся привести более полный обзор идей и методов, примененных в System R. При этом мы будем останавливаться и на некоторых возможных альтернативных решениях, которые были найдены разработчиками System R, но практически не были использованы.
7.1. Используемая терминология
Что касается общей терминологии реляционного подхода, мы будем активно пользоваться соответствующими терминами. К таким терминам относятся названия реляционных операций - селекция, проекция, соединение; названия теоретико-множественных операций - объединение, пересечение, разность и т. д.
В тех случаях, когда традиционная терминология System R расходится с общепринятой, мы будем отдавать предпочтение терминологии System R. В частности, это касается использования термина "поле отношения" вместо "атрибут отношения".
В самой System R при переходе к коммерческим системам также произошла некоторая смена терминологии. В частности, в некоторых последних публикациях появилась тенденция к употреблению более привычных в среде пользователей IBM терминов: файл, запись и т. д. Мы будем использовать термины System R, более близкие реляционным системам. Далее мы опишем некоторые основные термины System R, исходя при этом в основном не из теоретических соображений, а стремясь отразить практические аспекты соответствующих понятий.
Базовым понятием System R является понятие таблицы (приближенный к реализации эквивалент основного понятия реляционного подхода отношение; иногда, в зависимости от контекста, мы будем использовать и этот термин). Таблица - это некоторая регулярная структура, состоящая из конечного набора однотипных записей - кортежей. Каждый кортеж одного отношения состоит из конечного (и одинакового) числа полей кортежа, причем i-тое поле каждого кортежа одного отношения может содержать данные только одного типа, и набор допустимых типов данных в System R предопределен и фиксирован. В силу регулярности структуры отношения понятие поля кортежа расширяется до понятия поля таблицы. I-тое поле таблицы можно трактовать как набор одноместных кортежей, полученных выборкой i-тых полей из каждого кортежа этой таблицы, т. е. в общепринятой терминологии как проекцию отношения на i-тый атрибут. В терминологию System R не входит понятие домена, оно заменяется здесь понятием типа поля, т. е. типом данных, хранение которых в данном поле допускается (это не вполне эквивалентная замена, но такова реальность System R).
Таблицы, составляющие базу данных System R, могут физически храниться в одном или нескольких сегментах, которые проще всего понимать как файлы внешней памяти (и это вполне соответствует действительности). Сегменты разбиваются на страницы, в которых располагаются кортежи отношений и вспомогательные служебные структуры данных индексы. Соответственно, каждый сегмент содержит две группы страниц - страницы данных и страницы индексной информации. Страницы каждой группы имеют фиксированный размер, но страницы с индексной информацией меньше по размеру, чем страницы данных. В страницах данных могут располагаться кортежи более, чем одного отношения (это очень важное свойство физической организации баз данных System R; следующие из этой организации преимущества разъясним позже).
Этим, конечно, не исчерпывается набор понятий System R, но остальные термины мы будем пояснять по ходу изложения, поскольку для этого требуется соответствующий понятийный контекст.
7.2. Основные цели System R и их связь с архитектурой системы
Основными целями разработчиков System R являлись следующие:
обеспечить ненавигационный интерфейс высокого уровня пользователя с системой, позволяющий достичь независимости данных и дать возможность пользователям работать максимально эффективно; обеспечить многообразие допустимых способов использования СУБД, включая программируемые транзакции, диалоговые транзакции и генерацию отчетов; поддерживать динамически изменяемую среду баз данных, в которой отношения, индексы, представления, транзакции и другие объекты могут легко добавляться и уничтожаться без приостановки нормального функционирования системы; обеспечить возможность параллельной работы с одной базой данных многих пользователей с допущением параллельной модификации объектов базы данных при наличии необходимых средств защиты целостности базы данных; обеспечить средства восстановления согласованного состояния баз данных после разного рода сбоев аппаратуры или программного обеспечения; обеспечить гибкий механизм, позволяющий определять различные представления хранимых данных и ограничивать этими представлениями доступ пользователей к базе данных по выборке и модификации на основе механизма авторизации; обеспечить производительность системы при выполнении упомянутых функций, сопоставимую с производительностью существующих СУБД низкого уровня.Прежде всего отметим, что в основном поставленные цели при разработке System R были достигнуты. Рассмотрим теперь, какими средствами были достигнуты эти цели, и как более точно можно интерпретировать их в контексте System R.
Основой System R является реляционный язык SQL. Иногда его называют языком запросов или языком манипулирования данными, но на самом деле его возможности гораздо шире. Средствами SQL (с соответствующей системной поддержкой) решаются многие из поставленных целей. Язык SQL включает средства динамической компиляции запросов, на основе чего возможно построение диалоговых систем обработки запросов. Допускается динамическая параметризация статически откомпилированных запросов, в результате чего возможно построение эффективных (не требующих динамической компиляции) диалоговых систем со стандартными наборами (параметризуемых) запросов.
Средствами SQL определяются все доступные пользователю объекты баз данных: таблицы, индексы, представления. Имеются средства уничтожения любого такого объекта. Соответствующие операторы языка могут выполняться в любой момент, и возможность выполнения операции данным пользователем зависит от ранее предоставленных ему прав.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
