

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Нижегородский Государственный Технический Университет
Лабораторная работа №1
«Исследование методов эффективного кодирования»
Нижний Новгород
2003г.
Цель работы
Изучить способы эффективного кодирования информации по методам Шеннона и Хаффмана. Произвести кодирование данных для длин блоков 2,3,4 (по Шеннону) и 2,3 (по Хаффмену). Определить для каждого случая средний размер одного разряда и среднюю длину кодового слова.
Описание алгоритмов кодирования
Алгоритм кодирования методом Хаффмана:
Буквы алфавита сообщений вписываются в основной столбец в порядке убывания вероятностей. Две последние буквы объединяются в одну вспомогательную букву, которой приписывается суммарная вероятность. Вероятности букв, не участвовавших в объединении и полученная суммарная вероятность снова располагаются в порядке убывания в дополнительном столбце, а две последние объединяются. Процесс продолжается до тех пор, пока не получим единственную вспомогательную букву с вероятностью, равной единице.
Для составления кодовой комбинации, соответствующей данному сообщению, необходимо проследить путь перехода сообщения по строкам и столбцам таблицы.
Алгоритм кодирования методом Шеннона:
Буквы алфавита сообщений вписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним 0. Каждая из полученных групп в свою очередь разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Ход работы
Для эффективного кодирования с помощью 1 и 0 выбираем вероятность появления
1 или 0 от 0,2 до 0,4.
Выбираем р=0,24. Тогда q=1-p=0,76.
Энтропия системы: H(x)=-p*log(p)-q*log(q)=0.795
Коэффициент избыточности: r=1-H(x)=0.205
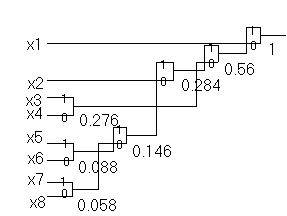
1. Кодирование по Шеннону (Р=0,24 N=4)
N | Pi | l | Pi*l | |||||||||||
0 | 0 | 0 | 0 | 0 | 0,334 | 1 | 1 | 2 | 0,668 | |||||
1 | 0 | 0 | 0 | 1 | 0,105 | 1 | 0 | 1 | 3 | 0,315 | ||||
2 | 0 | 0 | 1 | 0 | 0,105 | 1 | 0 | 0 | 3 | 0,315 | ||||
4 | 0 | 1 | 0 | 0 | 0,105 | 0 | 1 | 1 | 3 | 0,315 | ||||
8 | 1 | 0 | 0 | 0 | 0,105 | 0 | 1 | 0 | 1 | 4 | 0,42 | |||
3 | 0 | 0 | 1 | 1 | 0,033 | 0 | 1 | 0 | 0 | 4 | 0,132 | |||
5 | 0 | 1 | 0 | 1 | 0,033 | 0 | 0 | 1 | 1 | 4 | 0,132 | |||
6 | 0 | 1 | 1 | 0 | 0,033 | 0 | 0 | 1 | 0 | 1 | 5 | 0,165 | ||
9 | 1 | 0 | 0 | 1 | 0,033 | 0 | 0 | 1 | 0 | 0 | 5 | 0,165 | ||
10 | 1 | 0 | 1 | 0 | 0,033 | 0 | 0 | 0 | 1 | 1 | 5 | 0,165 | ||
12 | 1 | 1 | 0 | 0 | 0,033 | 0 | 0 | 0 | 1 | 0 | 5 | 0,165 | ||
7 | 0 | 1 | 1 | 1 | 0,011 | 0 | 0 | 0 | 0 | 1 | 1 | 6 | 0,066 | |
11 | 1 | 0 | 1 | 1 | 0,011 | 0 | 0 | 0 | 0 | 1 | 0 | 6 | 0,066 | |
13 | 1 | 1 | 0 | 1 | 0,011 | 0 | 0 | 0 | 0 | 0 | 1 | 6 | 0,066 | |
14 | 1 | 1 | 1 | 0 | 0,011 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 7 | 0,077 |
15 | 1 | 1 | 1 | 1 | 0,003 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 0,021 |
Средняя длина кодового слова LСР =å li*pi = 3,25
Средний размер одного разряда l = LСР/n = 0,82
2. Кодирование по Шеннону (Р=0,24 N=3)
N | Pi | l | Pi*l | ||||||||
0 | 0 | 0 | 0 | 0,439 | 1 | 1 | 0,439 | ||||
1 | 0 | 0 | 1 | 0,139 | 0 | 1 | 1 | 3 | 0,417 | ||
2 | 0 | 1 | 0 | 0,139 | 0 | 1 | 0 | 3 | 0,417 | ||
4 | 1 | 0 | 0 | 0,139 | 0 | 0 | 1 | 3 | 0,417 | ||
3 | 0 | 1 | 1 | 0,044 | 0 | 0 | 0 | 1 | 1 | 5 | 0,22 |
5 | 1 | 0 | 1 | 0,044 | 0 | 0 | 0 | 0 | 0 | 5 | 0,22 |
6 | 1 | 1 | 0 | 0,044 | 0 | 0 | 0 | 0 | 1 | 5 | 0,22 |
7 | 1 | 1 | 1 | 0,014 | 0 | 0 | 0 | 0 | 0 | 5 | 0,07 |
Средняя длина кодового слова LСР = 2,41
Средний размер одного разряда l = 0,8
3. Кодирование по Шеннону (Р=0,24 N=2)
N | Pi | l | Pi*l | |||||
0 | 0 | 0 | 0,578 | 1 | 1 | 0,578 | ||
1 | 0 | 1 | 0,182 | 0 | 1 | 2 | 0,364 | |
2 | 1 | 0 | 0,182 | 0 | 0 | 1 | 3 | 0,546 |
3 | 1 | 1 | 0,059 | 0 | 0 | 0 | 3 | 0,177 |
Средняя длина кодового слова LСР = 1,66
Средний размер одного разряда l = 0,83
4. Кодирование по Хаффмену (Р=0,24 N=3)
N | Pi | l | Pi*l | ||||||||
0 | 0 | 0 | 0 | 0,439 | 0 | 1 | 0,439 | ||||
1 | 0 | 0 | 1 | 0,139 | 1 | 1 | 0 | 3 | 0,417 | ||
2 | 0 | 1 | 0 | 0,139 | 1 | 0 | 1 | 3 | 0,417 | ||
4 | 1 | 0 | 0 | 0,139 | 1 | 0 | 0 | 3 | 0,417 | ||
3 | 0 | 1 | 1 | 0,044 | 1 | 1 | 1 | 1 | 1 | 5 | 0,22 |
5 | 1 | 0 | 1 | 0,044 | 1 | 1 | 1 | 1 | 0 | 5 | 0,22 |
6 | 1 | 1 | 0 | 0,044 | 1 | 1 | 1 | 0 | 1 | 5 | 0,22 |
7 | 1 | 1 | 1 | 0,014 | 1 | 1 | 1 | 0 | 0 | 5 | 0,07 |
Средняя длина кодового слова LСР = 2,41
Средний размер одного разряда l = 0,80
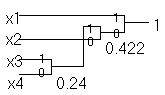
5. Кодирование по Хаффмену (Р=0,24 N=2)
N | Pi | l | Pi*l | |||||
0 | 0 | 0 | 0,578 | 1 | 1 | 0,578 | ||
1 | 0 | 1 | 0,182 | 0 | 0 | 2 | 0,364 | |
2 | 1 | 0 | 0,182 | 1 | 1 | 0 | 3 | 0,546 |
3 | 1 | 1 | 0,059 | 0 | 1 | 0 | 3 | 0,177 |
Средняя длина кодового слова LСР = 1,66
Средний размер одного разряда l = 0,83
Вывод
В ходе работы мы изучили методы эффективного кодирования по Шеннону и Хаффмену.
Из приведённых расчётов видно, что при одинаковой степени сжатия на блоках длинной 2 и 3 бита соответственно, метод Хаффмена наиболее предпочтителен, т. к. он выдаёт префиксный код (его можно выделить из непрерывной последовательности данных).
