

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Предикаты (1) вычисляются для любой числовой таблицы, поэтому важен ответ на вопрос: «Является ли некоторая найденная логическая закономерность класса ![]() (т. е. предикат вида (1)) случайной или нет?».
(т. е. предикат вида (1)) случайной или нет?».
Статистическая значимость найденных предикатов может быть оценена с помощью «перестановочного теста». Выполняется серия из следующих t однотипных расчетов (t – параметр «количество случайных перестановок»). Осуществляется случайная перестановка строк таблицы обучения, после чего, как и ранее, первые ![]() строк новой таблицы
строк новой таблицы ![]() считаются эталонами первого класса, следующие по порядку
считаются эталонами первого класса, следующие по порядку 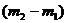 строк - эталонами второго класса, и т. д. (т. е. проводится случайное изменение номеров классов эталонных объектов с сохранением общего числа эталонов класса). Для таблиц
строк - эталонами второго класса, и т. д. (т. е. проводится случайное изменение номеров классов эталонных объектов с сохранением общего числа эталонов класса). Для таблиц ![]() находятся наилучшие закономерности
находятся наилучшие закономерности ![]() для каждого класса
для каждого класса ![]() с соответствующими оценками качества
с соответствующими оценками качества ![]() . Тогда логическая закономерность
. Тогда логическая закономерность ![]() из множества
из множества ![]() ={
={![]() } считается статистически значимой, если из неравенств
} считается статистически значимой, если из неравенств 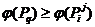 , i=1,2,…,t, выполнено не менее чем 100*g% .
, i=1,2,…,t, выполнено не менее чем 100*g% .
Качество логических закономерностей, полученных в результате перестановочного теста, можно использовать и для оценки значения параметра h.
3. Применение логических закономерностей классов для анализа признаков, объектов и классов.
Пусть по данным обучения для каждого класса ![]() вычислено некоторое множество
вычислено некоторое множество ![]() ={
={![]() } его логических закономерностей.
} его логических закономерностей.
Информационным весом признака назовем величину ![]() , где
, где ![]() - общее число логических закономерностей, в которые входит признак
- общее число логических закономерностей, в которые входит признак ![]() , N – общее число логических закономерностей.
, N – общее число логических закономерностей.
Признак считается информативным, если он входит в описания многих логических закономерностей и неинформативным в обратном случае.
Пусть ![]() -число одновременных вхождений признаков
-число одновременных вхождений признаков ![]() ,
, ![]() в одну закономерность по множеству всех закономерностей. Величину
в одну закономерность по множеству всех закономерностей. Величину 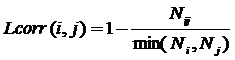 назовем логической корреляцией признаков
назовем логической корреляцией признаков ![]() ,
, ![]() . Данная величина равна нулю, когда во всех закономерностях, куда входит признак
. Данная величина равна нулю, когда во всех закономерностях, куда входит признак ![]() , присутствует
, присутствует ![]() (и наоборот), т. е. признаки "дополняют друг друга"(при min(Ni ,Nj)=0, полагаем
(и наоборот), т. е. признаки "дополняют друг друга"(при min(Ni ,Nj)=0, полагаем ![]() ). Корреляция равна единице, если ни в одну закономерность с признаком
). Корреляция равна единице, если ни в одну закономерность с признаком ![]() не входит
не входит ![]() . В /13/ описан алгоритм минимизации признаковых пространств с использованием введенных выше критериев и методов кластерного анализа: из исходного множества признаков выделяется минимальное число малокоррелированных информативных признаков, обеспечивающих незначительную потерю точности распознавания относительно исходного признакового пространства.
. В /13/ описан алгоритм минимизации признаковых пространств с использованием введенных выше критериев и методов кластерного анализа: из исходного множества признаков выделяется минимальное число малокоррелированных информативных признаков, обеспечивающих незначительную потерю точности распознавания относительно исходного признакового пространства.
Функции 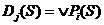 , где дизъюнкции берутся по множествам
, где дизъюнкции берутся по множествам ![]() ={
={![]() } будем называть логическими описаниями классов. Их можно рассматривать как приближения характеристических функций классов
} будем называть логическими описаниями классов. Их можно рассматривать как приближения характеристических функций классов ![]() . Данные функции принимают значение 1 только на эталонах «своего» класса (которые «покрыты» предикатами из
. Данные функции принимают значение 1 только на эталонах «своего» класса (которые «покрыты» предикатами из ![]() ) и 0 на всех эталонах «чужих» классов.
) и 0 на всех эталонах «чужих» классов.
Кратчайшим логическим описанием класса Kj назовем логическую сумму ![]() , суммирование в которой проводится по подмножеству множества
, суммирование в которой проводится по подмножеству множества ![]() , содержащему минимальное число конъюнкций Pt(S), и совпадающей с функцией Dj(S) на эталонных объектах.
, содержащему минимальное число конъюнкций Pt(S), и совпадающей с функцией Dj(S) на эталонных объектах.
Минимальным логическим описанием класса Kj назовем логическую сумму ![]() , суммирование в которой проводится по подмножеству множества
, суммирование в которой проводится по подмножеству множества ![]() , содержащей минимальное общее число символов x1(S),x2(S),...,xn(S) в своей записи, и совпадающей с функцией Dj(S) на эталонных объектах.
, содержащей минимальное общее число символов x1(S),x2(S),...,xn(S) в своей записи, и совпадающей с функцией Dj(S) на эталонных объектах.
Логические (кратчайшие, минимальные) описания классов являются аналогами представлений частичных булевых функций в виде сокращенных дизъюнктивных нормальных форм (кратчайших, минимальных), а геометрические образы логических закономерностей классов - аналогами максимальных интервалов /1, 7/.
Пусть найдено множество ![]() ={ P1(S), P2(S),…, PN(S) } логических закономерностей класса Kj ,
={ P1(S), P2(S),…, PN(S) } логических закономерностей класса Kj , ![]() - подмножество всех элементов из Kj , на которых выполняется хотя бы один предикат из
- подмножество всех элементов из Kj , на которых выполняется хотя бы один предикат из ![]() . Тогда кратчайшее и минимальное логические описания класса находятся как решения следующих задач целочисленного линейного программирования:
. Тогда кратчайшее и минимальное логические описания класса находятся как решения следующих задач целочисленного линейного программирования:
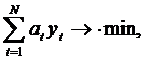 (3)
(3)
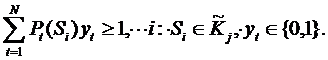 (4)
(4)
Тогда при at =1 единичные компоненты решения задачи (3-4) определяют предикаты кратчайшего логического описания ![]() класса Kj , а при at , равных числу переменных в Pt(S), - предикаты минимального логического описания. Следует отметить, что как мощность
класса Kj , а при at , равных числу переменных в Pt(S), - предикаты минимального логического описания. Следует отметить, что как мощность ![]() , так и минимальные (кратчайшие) логические описания являются важными характеристиками классов. Малая величина отношения
, так и минимальные (кратчайшие) логические описания являются важными характеристиками классов. Малая величина отношения 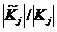 (найденные логические закономерности выполнены на незначительном числе эталонов рассматриваемого класса) говорит о плохой отделимости классов.
(найденные логические закономерности выполнены на незначительном числе эталонов рассматриваемого класса) говорит о плохой отделимости классов.
Вычисленные множества ![]() могут содержать равные или близкие элементы, мощность
могут содержать равные или близкие элементы, мощность ![]() может быть весьма велика (что однако является благоприятным в процедурах распознавания). Данные свойства множеств
может быть весьма велика (что однако является благоприятным в процедурах распознавания). Данные свойства множеств ![]() существенно зависят от длины обучающей выборки и самого алгоритма их поиска. В то же время кратчайшие и минимальные логические описания классов образуют уже неизбыточные подмножества
существенно зависят от длины обучающей выборки и самого алгоритма их поиска. В то же время кратчайшие и минимальные логические описания классов образуют уже неизбыточные подмножества ![]() , выражающие как основные свойства данных множеств, так и свойства самих классов. Поэтому
, выражающие как основные свойства данных множеств, так и свойства самих классов. Поэтому ![]() и
и ![]() могут рассматриваться как наиболее компактные представления о классах, включающие как наиболее представительные знания (предикаты, покрывающие большое число эталонов), так и уникальные или редкие (предикаты, покрывающие малое число эталонов или отдельные из них).
могут рассматриваться как наиболее компактные представления о классах, включающие как наиболее представительные знания (предикаты, покрывающие большое число эталонов), так и уникальные или редкие (предикаты, покрывающие малое число эталонов или отдельные из них).
Логической сложностью (компактностью) классов назовем величины:
1. y1(Kj)=<число конъюнкций в ![]() >;
>;
2. y2(Kj)=<число переменных в ![]() >.
>.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
