
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 519.86; 519.87; 37.001.5
Универсальная модель текста для создания средств диагностики качества обучения
, д. филос. н, профессор
Омский государственный университет им.
Аннотация: Предлагается новая концепция измерений качества обучения, которая основывается на признании того, что качество обучения – это преодоленная трудность содержания учебно-методического обеспечения образовательного процесса. Для измерения трудности содержания средств обеспечения образования необходимо иметь инструментарий высокой валидности и надежности, а также шкалы высокого разрешения. В данной статье предлагаются подходы к исчислению трудности учебников и учебных пособий, задач и упражнений, тестовых заданий и их композиций по математическим, естественнонаучным, техническим и гуманитарным дисциплинам для всех форм и уровней образования.
Ключевые слова: качество обучения, трудность содержания, трудность понимания текста, трудность тестов.
Для текста и, соответственно, текстовых средств диагностики качества обучения существуют две характеристики: сложность и трудность. Обычно сложность содержания текстовых средств рассматривается как суперпозиция элементов структурных схем, представляющих содержание. Вполне очевидно, что таких схем и суперпозиций для одного и того же текста можно составить несколько. Поэтому следует использовать концепцию , согласно которой сложность рассчитывается через длину алгоритма понимания текста, решения задачи [1, с. 253]. Он же предлагает оценивать трудность формальной системы посредством введения факторов трудности, зависящих от особенностей обработки информации человеком [1, с. 222]. Его энтропийная концепция сложности и трудности ориентирует исследователей на минимальную длину алгоритма, задаваемую тем или иным формализмом. Такие алгоритмы будем называть экспертными. Концепцию сложности и трудности поддерживают и другие исследователи: [2] и [3].
Учебный текст в дидактическом плане интересен также с точки зрения его понимания. Однако проблема исчисления трудности понимания текста исследователями не решалась по причине отсутствия у них «инновационного потенциала». Мы же решаем эту проблему, исходя из того факта, что трудность понимания текста определяется трудностью не пройденных шагов, не раскрытых концептов, не решенных подзадач.
Трудность понимания текста индивидом является скрытым параметром и поэтому напрямую измерена быть не может. Однако трудность в решении той или иной мыслительной задачи может быть определена через неуспешность в решении задачи. Например, чем больше задач из какого либо задания не решил учащийся, тем труднее для него оказалось это задание. Аналогично, чем меньше действий в решении задачи мог совершить учащийся, тем труднее для него эта задача. Понимание текста также сводится к решению ряда мыслительных задач по раскрытию содержания текста. Раскрыть содержание текста в таком «задачном» подходе – значит, в первую очередь, раскрыть содержание понятий, фигурирующих в тексте. Понятия (концепты, категории) имеют сложную иерархическую структуру, которая часто описывается в лингвистике на языке субъект-предикатного подхода к содержанию текста [4].
В соответствии с субъект-предикатным подходом, текст выражает иерархическую систему текстовых субъектов и предикатов. Предикат также может быть представлен системой субъектов. Таким образом, текст представляется иерархией субъектов, когда раскрытие главного текстового субъекта – предмета высказывания – происходит посредством его замещения (модификации) иерархической системой субъектов нижележащих рангов. При этом каждый последующий субъект является модификатом предыдущего. Некоторые текстовые субъекты не имеют модификаций и являются конечными (терминальными). Таким образом, система субъектов текста оказывается системой модификации начального (главного) субъекта.
Согласно нашей концепции, следует различать трудность содержания текста и трудность его понимания. Наиболее просто расчет трудности содержания текста может быть проведен следующим образом. На основании структурной схемы (графа) выделяются линии модификации, для каждой из которых определяется трудность как сумма трудностей (трудностей определений) учитываемых субъектов. Трудность определения субъекта равна произведению исходной трудности, величина которой может быть принята равной единице для всех субъектов, на ряд коэффициентов, зависящих от места субъекта в их последовательности, типа непосредственной модификации данного субъекта и других характеристик. Затем суммируются показатели трудности для всех линий модификации, входящих в задачу определения трудности содержания соответствующего фрагмента текста.
Таким же образом определяется трудность содержания узлов структурной сети, в качестве которых фигурируют текстовые субъекты. Данная модель трудности содержания текста позволяет оценивать трудность содержания всего комплекса средств диагностики качества образования, в том числе тестов по самым различным дисциплинам. В отличие от введенного нами концепта «трудность содержания», трудность понимания текста определяется суммарной трудностью нераскрытых текстовых субъектов, которую легко вычислить, составив таблицу параметров текстовых субъектов.
В качестве примера рассмотрим утверждение: величина тока прямо пропорциональна величине напряжения. Речь идет о формулировке закона Ома для однородного участка цепи. Разумеется, формулировка не идеальна, но это всего лишь пример. Запишем предикат в символьной форме: I = gU, где g – электропроводность, равная 1/R. R – сопротивление участка.
Построим граф для данного утверждения (рис. 1).

Рис. 1. S0 – главный (начальный) текстовый субъект, в качестве которого выступает «закон Ома».
Определим уровни раскрытия выбранного нами утверждения. Для этой цели раскроем содержание всех субъектов, входящих в предикат. На рисунке 2 показана одна из возможностей раскрытия субъектов I, U, g.
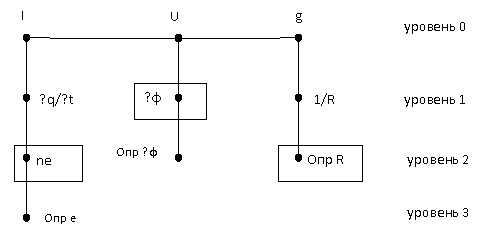 |
Рис. 2. ∆φ – модуль разности потенциалов, «опр» – определение соответствующей величины.
Оценим трудность содержания текста на нулевом уровне раскрытия субъектов I, U, g. Для этой цели воспользуемся таблицей 1.
Таблица 1
Коэффициенты и величины трудности определений субъектов (см. рис. 1)
Субъекты | ki | km | Тi |
I | 3 | 2 | 6 |
U | 2 | 2 | 4 |
g | 1 | 1 | 1 |
Суммируя величины в последнем столбце таблицы, увидим, что трудность определений субъектов I, U, g по линии модификации, показанной на рис. 1 без учета раскрытия субъектов равна 11.
Трудность текста на первом уровне раскрытия субъектов будет равна полученной трудности плюс трудность субъектов q/t, ∆φ, 1/R и т. д.
Трудности определений субъектов, участвующих в раскрытии субъектов I, U, g, вычислим следующим образом. Прежде всего, отметим, что для каждой ветви раскрытия величин I, U, g определения величин («опр») являются терминальными субъектами, для которых трудность определения равна единице. Отметим, что мы имеем дело с экспертным анализом, а для эксперта определения величин являются тривиальными.
Составим таблицу для субъектов «раскрытия» (таблица 2).
Таблица 2
Величины характеристик модификатов, показанных на рис. 2.
Субъекты | ki | km | Тi |
q/t | 3 | 2 | 6 |
∆φ | 2 | 2 | 4 |
1/R | 2 | 2 | 4 |
ne | 2 | 2 | 4 |
Опр ∆φ | 1 | 1 | 1 |
Опр R | 1 | 1 | 1 |
Опр е | 1 | 1 | 1 |
Для трудности содержания нашего текста на первом уровне раскрытия субъектов необходимо к трудности на нулевом уровне раскрытия прибавить трудности определений субъектов первого уровня раскрытия (q/t, ∆φ, 1/R). В итоге получаем: Т = 11+14 = 25. Для сложности текста на втором уровне раскрытия к полученному результату следует прибавить сложности субъектов второго уровня. 25 + 6 = 31. Для сложности текста на третьем уровне к 31 следует прибавить сложность оставшегося терминального субъекта. В итоге получим 32. Таким образом, мы показали на данном примере, как можно эффективно оценивать трудность текста с учетом содержания текстовых субъектов.
Трудность понимания текста пропорциональна трудности нераскрытых субъектов. Предположим, что в процессе восприятия текста реципиент не способен раскрыть текстовые субъекты, обведенные на рисунке 2 рамками. Если не раскрыты те или иные субъекты, то не раскрыты и их модификаты. К нераскрытым субъектам и их модификатам относятся следующие субъекты (рис. 2): ∆φ, Опр ∆φ, ne, Опр е, Опр R. Их суммарная трудность равна 11. Эта величина и представляет собой трудность понимания текста данным учащимся.
Метод исчисления трудности текста, предложенный в данной статье, может быть легко адаптирован для тестов по самым различным дисциплинам для всех уровней образования.
Библиографический список
1. Теория информации и теория алгоритмов / . – М.: Наука, 1987.– 304 с.
2. Измерение трудности учебных упражнений посредством моделирования процесса их выполнения: Дис. … канд. пед. Наук . – Казань, 1987. – 156 с.
3. Методика формирования обобщенных умений на основе моделирования задач физики и математики / // Омский Научный Вестник. – 2004. – № 3 (28). – С. 225-229.
4. Смысловая структура учебного текста и проблемы его понимания / . – М.: Педагогика, 1982. – 176 с.
