
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
разпознавание двумерных образов на основе инвариантных вейвлет- моментов
,
Ярославский государственный университет им.
150000, Россия, Ярославль, ул. Советская, 14. Тел. (0852) 79-77-75. E-mail: [email protected]
Использование инвариантных моментов в качестве признаков при распознавании двумерных образов привлекло огромное внимание [1]. В данной работе предлагается использование инвариантных вейвлет-моментов для сбора общей и локальной информации из объекта и метод выбора отличительных признаков, основываясь на наборе отличительных критериев, вычисленных для этих признаков.
Пусть ![]() представляет двумерный двоичный объект изображения (в полярных координатах
представляет двумерный двоичный объект изображения (в полярных координатах![]() ). Предполагается, что вычисленные признаки должны быть инвариантными к сдвигам, масштабированию и поворотам.
). Предполагается, что вычисленные признаки должны быть инвариантными к сдвигам, масштабированию и поворотам.
Для решения проблемы инвариантности к сдвигу и получения нормированной формы сделаем преобразование координат: ![]() S – предполагаемый размер объекта,
S – предполагаемый размер объекта, ![]() - двумерный момент порядка p,q. Следует заметить, что при отсутствии шума
- двумерный момент порядка p,q. Следует заметить, что при отсутствии шума ![]() будет равна 1, т.к. S будет равна
будет равна 1, т.к. S будет равна ![]() .
.
Для получения момента инвариантного к поворотам используется следующее выражение
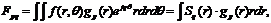 (1), где
(1), где ![]() - момент порядка p,q,
- момент порядка p,q, ![]() - функция радиальной переменной r, p,q – целочисленные параметры, а
- функция радиальной переменной r, p,q – целочисленные параметры, а ![]() . Легко доказать, что
. Легко доказать, что ![]() инвариантна к поворотам. Основываясь на выражении (1), можно показать, что моменты Хью, Ли и Зерника являются частными случаями этого выражения и полученные на их основе признаки являются глобальными:
инвариантна к поворотам. Основываясь на выражении (1), можно показать, что моменты Хью, Ли и Зерника являются частными случаями этого выражения и полученные на их основе признаки являются глобальными:
- при 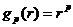 и некоторых ограничениях на p и q могут быть получены моменты Ли и Хью,
и некоторых ограничениях на p и q могут быть получены моменты Ли и Хью,
- при 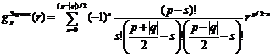 и некоторых ограничениях на p и q могут быть получены моменты Зерника.
и некоторых ограничениях на p и q могут быть получены моменты Зерника.
Следует отметить, что вычисление моментов Ли, Хью и Зерника происходит по всему пространству изображения и они являются чувствительными к шуму, т. о., не легко правильно классифицировать изображения похожих объектов, опираясь на вычисления этих моментов.
Рассмотрим в качестве ![]() в уравнении (1) семейство базисных вейвлет-функций [2, 3]
в уравнении (1) семейство базисных вейвлет-функций [2, 3]
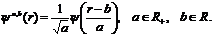 Параметры a и b дискретизируются следующим образом
Параметры a и b дискретизируются следующим образом
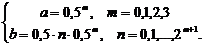
В работе использовался B-сплайновый вейвлет [4, 5], который оптимально локализован и близок по форме к полиномиальным моментам Ли и Зерника, и в аппроксимированной гауссовской форме [4] может быть записан следующим образом 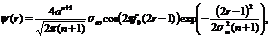 где
где ![]() ,
, 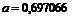 ,
, 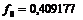 и
и 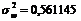 . Таким образом, инвариантный вейвлет-момент определяется следующим образом
. Таким образом, инвариантный вейвлет-момент определяется следующим образом 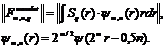
Для выбора отличительных признаков в работе используется стандартный дисперсионный метод разделения [5]. Таким образом, происходит ранжирование признаков в соответствии с их отличительными критериями и выбирается лучший набор признаков для классификации объекта.
Среднее значение каждого инвариантного признака ![]() для образа
для образа ![]() ,
, ![]() , и стандартное отклонение
, и стандартное отклонение ![]() может быть оценено из достаточного количества изображений образа
может быть оценено из достаточного количества изображений образа ![]() . В экспериментах бралось 30 обучающих изображений для каждого образа. На рис. 1а приведены примеры обучающих изображений для образов “1” и “|”.
. В экспериментах бралось 30 обучающих изображений для каждого образа. На рис. 1а приведены примеры обучающих изображений для образов “1” и “|”.
В работе используется следующий отличительный критерий, который оценивает эффективность использования признака ![]() для различения образов
для различения образов ![]() и
и ![]() :
: 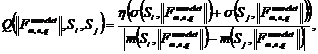 где
где ![]() . Причина выбора
. Причина выбора ![]() заключается в том, что вероятность распределения условной гауссовской переменной в интервале
заключается в том, что вероятность распределения условной гауссовской переменной в интервале ![]() приблизительно равна 99,8%. Таким образом, чем меньше значение отличительного критерия
приблизительно равна 99,8%. Таким образом, чем меньше значение отличительного критерия ![]() , тем лучше признак
, тем лучше признак ![]() различает образы
различает образы ![]() и
и ![]() . Если
. Если ![]() меньше единицы, то признак
меньше единицы, то признак ![]() гарантирует возможность различения образов
гарантирует возможность различения образов ![]() и
и ![]() .
.
Предположим, что существует ![]() классов во множестве образов, которые необходимо различить. С целью выбора отличительных признаков, вычислим отличительные критерии для каждого признака
классов во множестве образов, которые необходимо различить. С целью выбора отличительных признаков, вычислим отличительные критерии для каждого признака 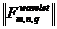 и выберем множество
и выберем множество ![]() , значения, которых не превышают единицы. Найдём число значений, удовлетворяющих этому условию, которое отражает возможность попарного классового разделения
, значения, которых не превышают единицы. Найдём число значений, удовлетворяющих этому условию, которое отражает возможность попарного классового разделения 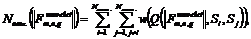 где
где 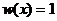 при
при ![]() и
и 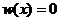 в других случаях. Для каждого признака
в других случаях. Для каждого признака ![]() определим наихудшую из всех отличительную характеристику
определим наихудшую из всех отличительную характеристику 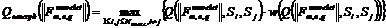 из множества
из множества ![]() .
.
Процедура выбора отличительных признаков:
1. В соответствии с ![]() и
и ![]() упорядочиваем все инвариантные вейвлет моменты
упорядочиваем все инвариантные вейвлет моменты ![]() для
для ![]() и
и ![]() . Упорядочивание происходит в соответствии с убыванием
. Упорядочивание происходит в соответствии с убыванием 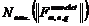 .Для признаков с одинаковым числом
.Для признаков с одинаковым числом ![]() упорядочивание происходит в соответствии с возрастанием чисел
упорядочивание происходит в соответствии с возрастанием чисел 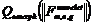 .
.
2. Выбираем последние ![]() признаков из упорядоченного списка признаков.
признаков из упорядоченного списка признаков.
Во всех экспериментах оценка выбранных отличительных характеристик происходила в соответствии с правилом классификации по минимальному отклонению. Через 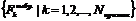 обозначим выбранные признаки в соответствии с предложенным методом выбора. Пусть
обозначим выбранные признаки в соответствии с предложенным методом выбора. Пусть 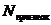 - число выбранных признаков,
- число выбранных признаков, ![]() - число классов и
- число классов и ![]() - число образцов каждого класса. Более того, через
- число образцов каждого класса. Более того, через 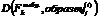 обозначим k-й выбранный признак j-го образца i-го класса. Далее, для каждого класса образцов можно получить среднее значение (
обозначим k-й выбранный признак j-го образца i-го класса. Далее, для каждого класса образцов можно получить среднее значение (![]() ) и отклонение
) и отклонение ![]() каждого выбранного признака.
каждого выбранного признака.
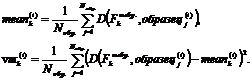
Далее каждый класс представляется вектором средних признаков образа ![]() . При классификации неизвестного объекта с вектором признаков
. При классификации неизвестного объекта с вектором признаков ![]() ему приписывается класс ближайшего вектора средних признаков образа при рассмотрении всех
ему приписывается класс ближайшего вектора средних признаков образа при рассмотрении всех ![]() векторов. Отклонение вектора
векторов. Отклонение вектора ![]() от вектора средних признаков образа i-го класса определяется следующим образом
от вектора средних признаков образа i-го класса определяется следующим образом
![]() Объект
Объект ![]() приписывают к классу
приписывают к классу ![]() , если
, если
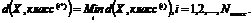
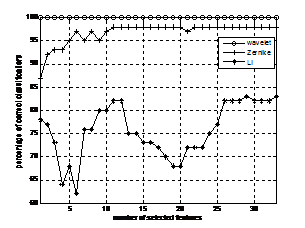
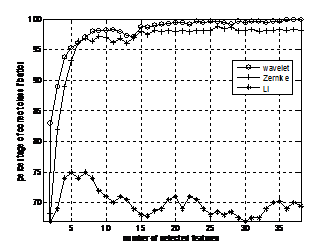
Оценка классификаций при использовании различных чисел выбранных признаков, определёнными тремя различными способами, используя предложенный метод выделения отличительных признаков, для двух образов “1” и “|” представлена на рис. 1б. Результаты получены при использовании 50 тестовых изображений каждого образа. На графике, представленном на рис. 1б по горизонтальной оси число выбранных признаков , а по вертикальной – процент правильной классификации. Из рисунка видно, что вейвлет моменты лучше моментов Зерника и гораздо лучше моментов Ли при классификации этих двух на вид одинаковых образов, но имеющих небольшие отличия.
Эксперимент проводился для заглавных букв английского алфавита (26 букв). Для обучения и тестирования генерировались случайным образом по 30 образов каждой буквы. Несколько сгенерированных образов представлены на рис. 2а. Оценка результатов представлена на рис. 2б. Таким образом, можно сказать, что инвариантные вейвлет-моменты являются лучшими признаками из трёх представленных инвариантных моментов.
В работе представлены инвариантные вейвлет-моменты для сбора как общей, так и локальной информации об объекте, которые сравнивались с инвариантными моментами Ли и Зерника. Инвариантные вейвлет-моменты предоставляют больше отличительных признаков для различных образов даже если они похожи и при наличии шума в изображении. Также предложен метод выбора отличительных признаков, основывающийся на отличительном критерии каждого признака. Используя метод классификации по минимальному отклонению, показано, что инвариантные вейвлет-моменты дают выигрыш с точки зрения процента правильных классификаций и подходят для классификации объектов различных форм, даже когда они похожи.
Литература
1. Prokop R.J., Reeves A.P. A survey of moment-based techniques for unoccluded object representation and recognition // CVGIP: Graphical Models Image Process. 1992. V. 54, № 5. P. 438-460.
2. Десять лекций по вейвлетам: Пер. с англ. – М.: НИЦ «Регулярная и хаотическая динамика», 2004.
3. Chui C.K. An Introduction to Wavelets. Academic Press, New York, 1992.
4. Unser M., Aldroubi A., Eden M. On the asymptotic convergence of B-spline wavelets to Gabor functions // IEEE Trans. Inform. Theory. 1992. V. 38, P. 864-872.
5. Unser M. A practical guide to the implementation of the wavelet transform / In: A. Aldroubi, M. Unser, (Eds.) Wavelets in Medicine and Biology. CRC Press, Boca Raton, FL, 1996. P. 37-73.
а) |
б) |
|
Рис. 1. Распознавание тестовых изображений: а) примеры образов “1” и “|”; б) процент правильной классификации образов “1” и “|” 100 различных тестовых изображений в зависимости от числа выбранных признаков
| ||
а) |
б) |
|
Рис. 2. Распознавание случайно сгенерированных изображений: а) примеры изображений образа “A”; б) процент правильной классификации в зависимости от числа выбранных признаков для случая 26 заглавных букв английского алфавита
|
¾¾¾¾¾¨¾¾¾¾¾
Recognition of 2-D patterns on the base of invariant wavelet moments
Smolyakov A., Novosyelov S.
Yaroslavl State University
150000, Russia, Yaroslavl, Sovetskaya st., 14. Phone. (4852) 79-77-75. E-mail: [email protected]
Appearance of the fist works devoted to the use of moments for identification received much attention [1]. These works found wide application and there are a lot of issues relate to this topic today. However, the majority part of suggested new techniques uses moments and new moments for pattern recognition have some drawbacks, such as high computational complexity and nonorthogonality of the functions leads to moments uses these functions for computation contain much redundant information about an object’s shape.
The geometrical moments of an image are integrals of the image function over space, and the image can be uniquely determined by its geometrical moments of all orders. Standard (global) moments (Li’s moments and Zernike moments) are calculated on the global image space. Also they are sensitive to noise. Thus it is not easy to correctly classify similar image objects based on such global moment invariants.
In this work invariant wavelet moments for capturing global and local information from the object and a method of selecting discriminative features (moments), based on a set of discriminative measures evaluated for these features are proposed. These measures are a probabilistic separability measures, if we consider the feature distribution as a Gaussian function.
Invariant wavelet moment defines as follows ![]() , where
, where 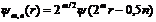 - wavelet function,
- wavelet function, ![]() - image function in the polar coordinate.
- image function in the polar coordinate.
Classifications of the patterns are produced by minimum distance of selected discriminative features (invariant wavelet moments). Compared introduced invariant wavelet moments with invariant Zernike’s moments and invariant Li’s moments, wavelet moments can provide more discriminative features for a variety of shapes even when they are seemingly similar and in the presence of noise.
Experiments are provided for the patterns “1” and “|”, where 30 patterns were randomly generated for training and 50 for test for each form and for the images of upper English letters (26 letters), where 30 patterns were randomly generated for training and for test for each parative estimation in depends of number of selected discriminative features (invariant moments) is provided by calculating the percentage of correct classification of the objects. Method of selecting of the features for Li’s moments and for Zernike’s moments is similar to suggested method.
Using method of classifying by minimum distance, it had been shown that invariant wavelet moments gave the highest classification gain from the percentage of correct classification point of view and is suited to classifying many types of object shapes, particularly, when they are seemingly similar.
References
1. Prokop R.J., Reeves A.P. A survey of moment-based techniques for unoccluded object representation and recognition // CVGIP: Graphical Models Image Process. 1992. V. 54, № 5. P. 438-460.
¾¾¾¾¾¨¾¾¾¾¾
СИСТЕМА СЖАТИЯ И ВИЗУАЛИЗАЦИИ ТРЁХМЕРНЫХ СИГНАЛОВ
,
Московский энергетический институт (ту)
Данная работа включает в себя исследование и реализацию некоторых методов обработки изображений в трёхмерном пространстве. Пока трёхмерные (3D) изображения не проникли в повседневную жизнь людей, но часто используются во многих областях, таких как медицина, геология, астрономия, и т.д..
Объёмная визуализация необходима для полного понимания сложной структуры трёхмерных данных. Эти данные могут быть разными, начиная с моделирования и оценки сопротивления ветра вдоль поверхности машины, также включая сканирование тела с помощью компьютерной томографии или отображением данных магнитного резонанса.
В методах кодирования изображений с помощью преобразований, изображение «проецируется» на определённый набор базисных функций, и далее кодируется результирующий набор коэффициентов. Для обеспечения эффективного кодирования необходимо, чтобы применяемое преобразование компактно представляло энергию сигнала в малом наборе коэффициентов.
Дискретное вейвлет-преобразование (ДВП) может быть применено для многомерных сигналов с помощью использования разделимых фильтров. Сигнал фильтруется и децимируется в каждом измерении. Неразделимые фильтры тоже могут быть использованы с этой целью.
Так как трёхмерные данные могут быть рассмотрены, как последовательность двумерных изображений, то существует возможность обрабатывать и сжимать их двумерными алгоритмами. Но они не используют зависимость значений пикселей по всем трём измерениям. Для лучшего анализа необходимо учитывать эти зависимости и рассматривать этот набор последовательных разрезов как одно целое 3D изображение.
Для сжатия медицинских данных, если следовать схеме алгоритма «без потерь», можно использовать целочисленное вейвлет-преобразование, после которого можно применить адаптивное арифметическое кодирование, основанное на контекстах, например, как это делается в JPEG2000.
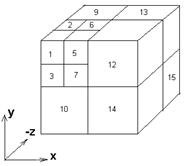
На рис. 1 (слева) показано двухуровневое 3D ДВП с разделимыми фильтрами. Как и в случае с одномерным ДВП, в 3D ДВП коэффициенты занимают такой же объём памяти, как и исходный «куб». На рисунке каждый поддиапазон пронумерован.
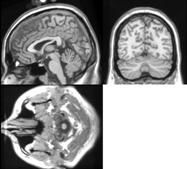
Объёмная визуализация используется для возможности обзора как внутренних, так и наружных поверхностей. Через использование разрезов и 3D моделей эта проблема может быть решена. Разрез – это тонкий слой визуализируемого объекта, который несёт в себе как внешний, так и внутренний вид поверхности. Серия разрезов объекта может помочь понять внутреннюю структуру объекта. Цветность разрезов, обычно, несёт в себе информацию о плотности объекта, но так же может использоваться для идентификации любого другого типа информации об объекте.
Разрезы человеческой головы, которые будут представлены ниже, используют оттенки серого для выражения плотности внутренней структуры. Таким образом, легко выделить глаза, череп, мозг и т.д. основываясь на изменении плотности.
|
|

а. б.
Рис. 1. Двухуровневое трёхмерное вейвлет-разложение: а –по трём осям;
б – одноуровневое трёхмерное вейвлет-преобразование томографического скана.
Для визуализации была использована спецификация OpenGL (Open Graphics Library - открытая графическая библиотека), определяющая независимый от языка программирования кросс-платформенный программный интерфейс для написания приложений, использующих двумерную и трехмерную компьютерную графику. Данный интерфейс включает более 250-ти функций, которые могут использоваться для рисования сложных трехмерных сцен из простых примитивов. OpenGL широко используется при создании видеоигр, САПР, систем виртуальной реальности, визуализации в научных исследованиях. Для независимости от языка программирования, были разработаны различные варианты привязки (binding) функций OpenGL или полностью перенесены на другие языки. Одним из примеров может служить библиотека Java 3D, которая может использовать аппаратное ускорение OpenGL.
1. Текстура – это изображение, которое нужно наложить на какой-либо из полигонов в OpenGL. Наложение текстур позволяет «наклеивать» изображения по примитивам OpenGL. В данном проекте используются текстуры из скана компьютерной томографии, которые наносятся на полигоны для визуализации мозга в трёхмерных координатах. Мозг получается правильной формы без искажений.
2. Наложение текстур гарантирует правильность рендеринга при обработке, изменении масштабов полигонов, вращении и других геометрических действиях.
|
|
|
а) | б) |
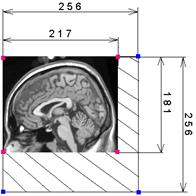
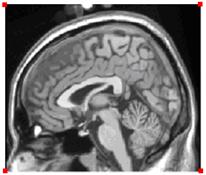
Рис. 2. Процесс наложения текстуры.
На рис. 2 показан пример процесса наложения текстуры. Слева показана целая текстура (прямоугольный массив цветовых данных), а справа показано то, как она может быть наложена на полигон большего размера.
Красные точки показывают границы текстуры, которые были «натянуты» на бóльший по размеру прямоугольник, чем размер самой текстуры. Отметим, что белый регион, который виден на текстуре нигде не используется: по правилам размер исходного изображения для текстуры должен быть кратным 2. Таким образом, при создании текстур мы используем размеры 2, 4, 8, 16, 32, 64, 128, 256 и т.д. И только после их считывания, перед наложением, определяется «текстурные координаты», которые показывают какую пропорцию исходного изображения необходимо «натянуть» на полигон.
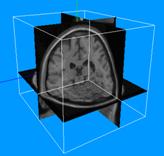
Рис. 3 показывает процесс разреза трёхмерного изображения (а) и сохранения этих разрезов в файл (б). Для лучшей визуализации объекта, разрезы, взятые из структуры объекта, часто собираются в одно трёхмерное изображение. Это можно сделать с помощью алгоритма трассировки лучей.
|
|
а) б)
Рис. 3. (а) Куб со стенками, на которые проецируются данные. (б) Пример записи разрезов в файл.
Трассировка лучей — это один из методов геометрической оптики, в котором отслеживания взаимодействия отдельных лучей с поверхностями. В узком смысле — технология построения изображения трехмерных моделей в компьютерных программах, при которых отслеживается обратная траектория распространения луча (от экрана к источнику).
После рендеринга внутренняя структура объекта может быть «раскрашена» цветовой информацией. Рис. 4 показывает пример представления трёхмерных данных с использованием алгоритма трассировки лучей.
|
|


а. б.
Рис. 4 Визуализация в перспективе: а – исходное изображение; б – с обращёнными цветами:
Литература
[1] OpenGL(R) Programming Guide: The Official Guide to Learning OpenGL, Version 1.2 (3rd Edition), M. Woo, J. Neider, T. Davis, D. Shreiner. OpenGL Architecture Review Board
[2] Schelkens P. Wavelet Coding of Volumetric Medical Datasets. Xavier Giro-Nieto, 2001
[3] Taubman D., Marcellin M. JPEG2000 Image Compression Fundamentals, Standards and Practice. Kluwer Academic Publishers, 2002.
[4] Bilgin A., Zweig G., Marcellin M. Three-dimensional image compression with integer wavelet transforms. Optical Society of America, 2000.
¾¾¾¾¾¨¾¾¾¾¾
THREE-DIMENSIONAL IMAGES COMPRESSION AND VISUALIZATION SYSTEM
Kislov D., Tchobanou M.
Moscow Power Engineering Institute (TU)
This paper introduces a three-dimensional signals compression and visualization system which is being developed at the moment. Three-dimensional images can be classified in many ways and certainly it’s impossible to process and visualize all types of them in one system, so mainly we are talking about medical 3D images, such as CT, MRT.
Modern CT or MRI scanners produce large sets of data, for example a CT scan which dimensions are 512x512x512 requires 128Mb of space. It is a relatively large space just for one image. Thus, compression is required that could save the image so the image could be restored with no loss.
Another important thing is visualization. 3D is much more complex than 2D and it is of high importance to make possible 3D rendering and visualization of the data we have.
¾¾¾¾¾¨¾¾¾¾¾
