
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Построение индекса, отражающего степень трансформации натуральных льгот в регионе
Анализ реформирования системы льгот затрудняется отсутствием однозначно интерпретируемого показателя, отражающего степень трансформации льгот (их отмены, сохранения или перевода в денежные выплаты) и позволяющего при этом проводить сравнения как между регионами, так и в динамике. Поясним эту проблему на следующем примере. Допустим, регион А решил монетизировать только одну из льгот и только для ветеранов труда, а регион B – две льготы для репрессированных. Как нам сравнить степень монетизации в этих регионах? Естественным выходом из этой ситуации стало бы присвоение каждой льготе определенного веса. Но как определить эти веса, не располагая информацией о реальной численности пользователей той или иной льготы, о распределении средств, выделяемых на финансирование льгот? Задача состоит в том, чтобы избежать присвоения весов экспертным способом, который характеризуется высокой чувствительностью результатов к мнениям экспертов и их составу. Авторы данного исследования предлагают алгоритм определения весов для каждой льготы, который позволяет сконструировать показатель, условно названный «индексом монетизации».
Для трех основных категорий региональных льготников (ветеранов труда, тружеников тыла и репрессированных) мы рассматриваем льготы, решение о переводе которых в денежный вид принимается субъектами Российской Федерации. Список соответствующих льгот приведён в таблице 1.
Таблица 1. Виды рассматриваемых льгот
Категория льготников | Ветераны труда | Труженики тыла | Репрессированные |
Виды льгот | 1. Зубопротезирование 2. Проезд на городском, пригородном и междугороднем транспорте 3. Проезд на железнодорожном и водном транспорте пригородного сообщения. 4. Жилищно-коммунальные услуги 5. Абонентная плата за телефон 6. Оплата радиоточки 7. Оплата коллективной телеантенны 8. Обеспечение твердым топливом | 1. Зубопротезирование 2. Проезд на городском, пригородном и междугороднем транспорте 3. Проезд на железнодорожном и водном транспорте пригородного сообщения 4. Лекарственное обеспечение | 1. Санаторно-курортное лечение 2. Лекарственное обеспечение 3. Зубопротезирование 4. Проезд на железнодорожном транспорте 5. Проезд на городском и пригородном транспорте 6. Жилищно-коммунальные услуги 7. Установка телефона 8. Обеспечение твердым топливом |
Как видно из таблицы, с учётом всех трёх категорий граждан, регион может монетизировать до 20 видов льгот. Нас интересует, насколько распространенным стало желание монетизировать ту или иную льготу для той или иной группы, поскольку самые трудные для субъектов Федерации решения становятся и самыми редкими. Для учёта «редкости» принятия регионами решения о монетизации той или иной льготы вводятся веса, отражающие наблюдаемую частоту решения о переводе в денежную форму каждой из рассматриваемых льгот.
Обозначим через Ik искомый показатель - индекс монетизации льгот регионом k. Введём переменную pjk, соответствующую решению региона k монетизировать льготу j. Пусть
![]()
Обозначим через wj вес льготы j, с которым она входит в индекс монетизации. Тогда, индекс монетизации региона k равен:
![]() (1)
(1)
Веса wj в предлагаемой модели вводились следующим образом. Для каждой из 20 возможных льгот была определена частота, с которой регионы принимали решение о её замене денежным пособием. Частота монетизации льготы j равна отношению числа Nj регионов, принявших решение о переводе в денежный вид соответствующей льготы к общему количеству субъектов Российской Федерации в нашей выборке N:
![]() (2)
(2)
В случае если все регионы приняли решение о монетизации некоторой льготы, то искомая частота равна единице, если половина субъектов Российской Федерации перевела данную льготу в денежную форму, то частота монетизации равна ½, если таковая льгота не была монетизирована ни одним рассматриваемым регионом, то частота равна нулю[1].
Напомним, что наше исходное предположение при построении системы весов состоит в том, что чем меньше частота монетизации некоторой льготы, тем сложнее субъекту Российской Федерации было принять соответствующее решение, и тем больше должен быть вес данной льготы в индексе монетизации. Исходя из данного предположения, определим вес льготы j как величину, обратно пропорциональную частоте данной льготы:
![]() , (3)
, (3)
где С – нормировочный коэффициент. Потребуем дополнительно, чтобы сумма весов всех льгот была равна единице. Сложив обе части равенства (3) с учётом требования нормировки весов получим:
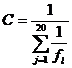 (4)
(4)
Тогда, с учётом (3) и (4) вес льготы j равен:
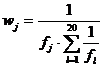 (5)
(5)
Равенство (5) определяет вес льготы j в индексе монетизации, вычисляемом по формуле (1) для каждого региона из выборки.
Пример
Допустим, что существует только 3 вида льгот: по оплате ЖКУ для ветеранов труда, по зубопротезированию для ветеранов труда и по проезду на общественном транспорте для репрессированных. Допустим также, что 10 процентов регионов решили заменить скидку по оплате ЖКУ для ветеранов труда на денежную выплату (частота 1 = 0,1), 90% заменяют выплатой зубопротезирование (частота 2 = 0,9) и половина – проезд (частота 3 = 0,5).
Соответствующие данным частотам веса будут:
1/ 0.1 = 10,
1/ 0.9 = 1,1
1/0.5 = 2
А сумма всех весов = 10+1,1+2=13,1
Нормировочные коэффициенты, составят, соответственно:
Для льготы по ЖКУ = 10/13,1
Для льготы по зубопротезированию = 1,1/13,1
Для льготы по проезду = 2/13,1
В этом случае, если регион А решил заменить все три льготы деньгами (то есть значения переменной Р составляют 1 1 и 1), то индекс монетизации региона А будет равен 1.
Если регион Б монетизирует только зубопротезирование (значения р составят 1 0 и 1), то индекс будет равен [1* 10/13,1] + 0 + [1* 2/13,1]=12/13,1=0.91
Если регион В монетизирует тоько льготу по проезду (0 0 и 1), то его индекс будет равен:
0 + 0 + [1 * 2/13,1] = 0.15
[1] При практическом применении данного алгоритма льгота, частота монетизации которой равна 0, исключается из рассмотрения, иначе в дальнейшем возникает проблема деления на 0. В нашем случае все льготы имели строго положительную частоту монетизации.
