

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
3.3.2.3. Организация МОС МПВС по принципу симметричной обработки.
Это наиболее эффективный, но и наиболее сложный способ организации МОС. В нем наиболее полно соблюдается принцип независимости между программистами и процессорами. Широко используется механизм множества приоритетных очередей к ресурсам, в том числе и к процессорам на выполнение счета. Все процессоры равноправны и нет жесткого закрепления одного из модулей ОП за ведущим процессором. Каждой из программ при загрузке в общую ОП присваивается требуемый уровень приоритета, а системные программы МОС всегда привилегированы, т. е. имеют высший уровень приоритета. Они всегда выталкивают из любого процессора прикладные программы, начиная со свободных процессоров и процессоров, обрабатывающих в данный момент программы наиболее низкого уровня приоритетов. В критические периоды интенсивной работы МОС, когда со стороны прикладных программ возникает одновременно несколько вызовов системы, например прерываний по вводу-выводу, МОС, вытесняя прикладные программы, может одновременно занять несколько процессоров. Тем самым появляется возможность параллельной обработки системных программ МОС и значительного снижения потерь машинного времени на выполнение внутрисистемных служебных функций. Тем самым решается одна из наиболее сложных задач МОС: поддержание высокой (максимально возможной) загрузки процессоров с учетом непостоянства их количества, связанного с выбыванием неисправных и пополнения их числа после восстановления отказавших.
Один из эффективных способов функциональной организации МОС при симметричной обработке называется метод динамического распределения и перераспределения программ (ДРПП) между наличными исправными процессорами. В МОС вводится специальный программный модуль «Диспетчер», вызываемый при загрузке в общую ОП новой прикладной программы, любом прерывании по инициативе любой из обрабатываемых программ, по признаку окончания обработки любой из программ. В некритические интервалы, когда нет необходимости обрабатывать названные обращения к системе, программа «Диспетчер», захватив как привилегированная любой из процессоров, постоянно обрабатывает содержимое памяти своих данных с единственной целью – выделение из всех имеющихся занятых процессоров, если нет свободных, одного кандидата на прерывание обрабатываемой в нем программы, если её приоритет самый низкий из всех обрабатываемых в данный момент времени программ. Для этого в области своих данных программа «Диспетчер» создает динамически изменяемую системную таблицу физических номеров наличных процессоров и уровней приоритетов обрабатываемых в ней программ. Метод ДРПП основан на многоочередной дисциплине обслуживания, а очереди идентификаторов программ, ожидающих доступа на процессорную обработку, хранятся и динамически изменяются в другой таблице в области данных программы «Диспетчер». Для наглядности изучения метода ДРПП отобразим его механизм графически в виде схемы взаимодействия двух названных системных таблиц.
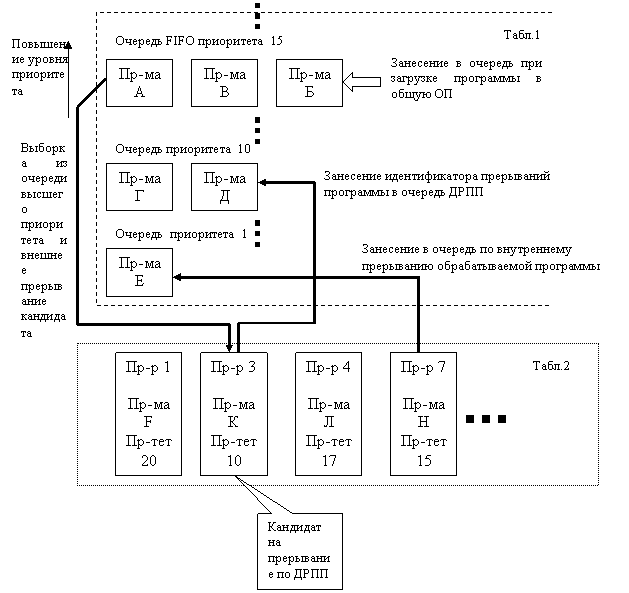
Программа «Диспетчер», просмотрев первую и вторую таблицы, находит непустую очередь высшего приоритета или ещё более приоритетную привилегированную программу МОС, ожидающую процессорной обработки, а также кандидата на прерывание в виде физического номера процессора (3) и идентификатора его наименее приоритетной программы (к), и затем передает управление супервизору МОС. Последний выполняет, вызывая вспомогательные утилиты МОС, всю работу по прерыванию, организует заполнение ССП прерываний программы и заносит в процессор (3) ССП новой программы и передает ей управление в процессоре (3). Идентификатор прерванной программы модуль «Диспетчер» заносит для ожидания дообслуживания в очередь соответствующего приоритета своей табл.1.
Если прерывание происходит по инициативе любой обрабатывающей программы, выполняется такая же работа по замене её в соответствующем процессе на самую приоритетную из табл.1 или на привилегированную программу МОС, вызываемую для обработки этого внутреннего прерывания.
Метод ДРПП хорошо совмещается с известным методом динамических приоритетов, который кроме этого обычно применяется для поддержания времени ответа (времени пребывания программы в системе до выдачи её результатов) на допустимом уровне при сильно отличающихся вычислительных сложностях обрабатываемых программ.
За время пребывания в системе приоритет программы может измениться несколько раз, и она в табл.1 «Диспетчера» перемещается из одной очереди в другую. Так, если время обработки в процессоре для высокоприоритетной программы недопустимо затягивается tобр>tдоп.1, то она также становится кандидатом на прерывание, но после внешнего прерывания её идентификатор заносится в табл.1 в низлежащую очередь с приоритетом на единицу меньшем. Если после повторного выхода на процессорную обработку вновь будет tобр>tдоп.1, уровень приоритета ещё снижается на единицу и так далее. Тем самым процессоры освобождаются для первоочередной обработки коротких программ, так как их пользователи ожидают их быстрого выполнения.
Для того, чтобы любая программа была обработана за конечное допустимое время, осуществляется также встречный поток постепенного повышения уровней приоритетов. если суммарное время пребываний какой-либо программы в системе:
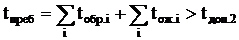
где i – номер шага обработки до очередного прерывания;
tдоп.2>>tдоп.1, например tдоп.1=1с, а tдоп.2=100с; тогда её идентификатор в очередной фазе ожидания «Диспетчер» переписывает в вышележащую очередь табл.1 с приоритетом на единицу выше.
Обработка прерванной программы после того, как подойдет её очередь, продолжается на любом из процессоров, и чаще всего не на том, на котором она прервана. Проблем с продолжением счета никаких, так как в загружаемом в процессор её ССП для возобновления обработки содержится глобальный адрес первой команды в общей ОП (N модуля ОП+N ячейки в модуле), с которой возобновляется счет. Поэтому процессор автоматически находит и закрепляет за собой нужный модуль общей ОП, если он не занят другим процессором. Но тогда к одному и тому же модулю общей ОП может возникнуть очередь запросов на обращение от нескольких процессоров. Выборка запросов на обслуживание из неё всегда осуществляется по дисциплине обслуживания с относительными приоритетами, в том числе и по отношению к привилегированным программам МОС. Она состоит в том, что при поступлении в очередь к модулю ОП запроса высшего приоритета по сравнению с приоритетами ожидающих в очереди и обслуживаемого в данный момент запроса процесс обращения в модуль ОП последнего не прерывается до его завершения, и только после его окончания программа высшего приоритета начинает обращение в данный модуль ОП, а последняя обслуживавшаяся программа прерывается и становится в очередь на ожидание дообслуживания. Этими процедурами, как известно, занимается супервизор общей ОП. Последний в контакте с «Диспетчером» исключает простой процессоров из-за ожидания доступа на обращение к памяти, аналогично реакции механизма ДРПП на внутреннее прерывание обрабатываемой программы, направляя идентификаторы соответствующих прерванных из-за этого программ в табл.1 очередей на ожидание процессорной обработки. Тогда задача ожидает доступа к памяти, но не процессоре, а в табл.1 ДРПП. Процессор же переключается на другую задачу, более приоритетную по доступу к ОП. Тем самым в процессорах на обработке всегда находятся только те программы, которые получили доступ на обращение к требуемым модулям общей ОП, и процессоры не простаивают из-за ожидания программами разрешения на обращение в ОП. В этом состоит основной механизм управления общей ОП. В этих же очередях запросов на обращение к модулям общей ОП находятся и запросы процессоров ввода-вывода, но с ними труднее реализовать описанный принцип независимости программ, процессоров и модулей общей ОП, так как они уже инициализированы начальной установочной информацией прямого доступа какой-то конкретной программы, и для смены обслуживаемой программы требуется сравнительно длительное повторное начальное перепрограммирование. Поэтому ПВВ могут простаивать из-за занятости модуля ОП. Однако при этом требования на ввод-вывод, например обращения к ВЗУ, системных программ МОС всегда будут обслужены любым модулем ОП в первую очередь.
3.3.3. Синхронизация параллельных асинхронных вычислительных процессов.
Метод семафоров.
В определенные интервалы времени несколько параллельных процессов могут одновременно затребовать один и тот же общий ресурс: процессоры, модуль общей ОП, почтовый ящик в общей ОП для обмена информацией; общую область модифицируемых данных в памяти, какой-либо программный модуль ОС и т. п.. Такие интервалы времени называются критическими интервалами. Большинство конфликтов разрешаются с помощью приоритетных очередей. Однако некоторые типы конфликтов механизм очередей не способен разрешить, например очереди могут задать оношения предшествования в совокупности процессов, т. е. не могут выдержать требуемой фиксированной последовательности их доступа к общему ресурсу, тогда как её нарушение может привести к искажению данных. Например, может быть установлена строго фиксированная последовательность доступа разных процессов к общей области данных при их модификации.
Второй характерный пример – неготовность входных операндов для некоторых процессов, которые в очереди к ресурсу занимают первые места. Их нужно задержать до появления входных операндов и пропустить вперед другие процессы с готовыми операндами. Известно, что этот тип конфликта автоматически разрешается при потоковой организации и потоковом программировании, например с помощью тегирования данных и механизма ссылок в объектах данных. В системах фон Неймана такой возможности нет.
Третий пример, присущий сетям ЭВМ и матричным транспьютерным сетям, – неготовность запрашиваемых параллельных процессов к взаимодействию с инициатором взаимодействия. Программа-инициатор достигла команды, когда ей необходимо взаимодействие, например передача кому-то или запрос у кого-то блока данных, а программа-ответчик не готова к взаимодействию либо потому, что она занята другой обработкой и ещё не подготовила буферы, требумые для обмена данными, либо потому, что память занята другими буферами обмена. Программу-инициатор следует приостановить до выполнения всех условий взаимодействия.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
