


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Глава 3. ПРОГНОЗИРОВАНИЕ МЕЖГОДОВОЙ
ИЗМЕНЧИВОСТИ СУММАРНОГО ПРИТОКА
В ОЗЕРО БАЙКАЛ
Задача предсказания временного хода природных, экономических или социальных процессов всегда привлекала внимание, как ученых, политиков, бизнесменов, так и широкие слои населения. Экономический эффект от вложения средств в прогностические исследования, как правило, оказывается значительным. В некоторых областях знания, например, в астрономии или механике, прогнозы подобного рода могут быть получены с большой точностью и заблаговременностью. В других областях, таких как экология, гидрометеорология, социология, предсказания значительно менее точны и надежны.
Интерес к задачам моделирования и долгосрочного прогнозирования стока рек и уровня водоемов постоянно поддерживается практическими потребностями в этой информации [Афанасьев, 1967; Раткович, 1976; Сванидзе, 1977; Музылев, Привальский, Раткович, 1982; Шелутко, 1984; Коваленко и др.,1992; Мещерская и др., 1999; Peter, 1999; Basilashvili, 2000]. В Байкальском регионе этот интерес связан, в первую очередь, с проблемами оценки гидроресурсов, обеспечивающих работу каскада ангарских ГЭС [Дружинин, Хамьянова, Лобановская, 1977; Бережных, Резников, 1996; Абасов и др., 2000]. Прежде, чем приступить к разработке необходимых моделей и составлению предсказаний стока в озеро Байкал, рассмотрим общие методические особенности этой задачи в контексте информационного подхода к моделированию.
§ 3.1. МЕТОДЫ И ПРОГРАММНЫЕ СРЕДСТВА СОВМЕСТНОГО ПРОГНОЗИРОВАНИЯ ВРЕМЕННЫХ РЯДОВ
Существуют различные подходы к построению прогнозных оценок, базирующиеся на данных наблюдений прогнозируемых параметров в прошлом, на фундаментальных законах природы, на мнениях экспертов и т. д. В рамках данного параграфа будут рассмотрены некоторые концепции и прогностические алгоритмы, опирающиеся на данные прямых или косвенных измерений некоторых характеристик в прошлом как на информационную основу для оценки их поведения в будущем.
Основываясь на материалах наблюдений за какой-либо переменной в прошлом можно выделить два основных подхода к задаче ее прогнозирования.
Первый из них предполагает, что рассматриваемая величина является функцией времени и задана некоторым набором ее значений на интервале наблюдений. Если эта функция детерминированная, то задача нахождения прогностического алгоритма заключается в нахождении ее явного математического вида. Искомая функция должна с точностью до ошибок измерений описывать наблюдавшиеся значения динамического ряда в прошлом и в будущем. Что касается прошлого, то существует бесконечное множество функций, которые могут аппроксимировать конечное число значений временного ряда с требуемой точностью. Но не существует ни одного обоснованного критерия, по которому из этого множества можно было бы выбрать именно ту, которая была бы справедливой и для будущего времени. По этой причине данный алгоритм не является конструктивным.
Рассмотрение временного ряда как суммы детерминированной и случайной функций не меняет картину принципиально, так как случайная составляющая формально выглядит как повышенная ошибка измерения со специфическим распределением. Но особенностью такого рассмотрения является то, что уменьшение доли изменчивости ряда за счет детерминированной составляющей позволяет аппроксимировать последнюю сравнительно простыми математическим структурами (линейные тренды, циклы и т. д.). Для таких структур кажется естественным плавно экстраполировать в будущее тренд или продолжить синусоиду цикла. Однако такая естественность обманчива, так как обоснованность этих аппроксимаций не больше, чем любых других, поведение которых на области прогнозирования совсем иное.
Прогноз случайной составляющей временного ряда основывается на предположении ее стационарности и эргодичности и строится как эмпирическая оценка ее распределения вероятностей по материалам наблюдений в прошлом.
В рамках второго подхода временной ряд рассматривается как реализация случайного процесса «с памятью». Это означает, что последующие значения ряда в той или иной мере могут зависеть от предыдущих. Для выявления такой зависимости применяются методы автокорреляции и авторегрессии. Эти методы требуют задания динамического ряда с постоянным шагом по времени. Авторегрессионные соотношения затем применяются для прогностических вычислений. При совместном анализе и прогнозе временных рядов появляется возможность использовать и взаимнорегрессионные соотношения. В математической структуре регрессионных формул, в отличие от аппроксимации рядов детерминированными функциями времени, время в явном виде отсутствует. Это, вроде бы, дает право считать их справедливыми и для будущих его значений. Однако такое утверждение справедливо лишь с некоторой долей вероятности.
В современных статистических пакетах [Брандт, 2003; Старков, 2002; Боровиков, 2003] наиболее часто встречаются процедуры экстраполяции временных рядов, основанные на линейных регрессионных моделях [Бокс, Дженкинс, 1974]. В практике решения таких задач автору также приходилось использовать эти методы [Игнатов, 1982]. Известны приемы прогнозирования, основанные на генерации различных моделей и выборе из них наилучших по некоторым критериям [Ивахненко, 1975; Кендалл, Стьюарт, 1976; Герцекович, Луцик, 1982; Резников, 1982; Абасов, Резников, 1997; Стряпчий, 2000; Кузьмин, 2001]. В последнее время интенсивно развивается подход к предсказанию динамических рядов, использующий технологию искусственных нейронных сетей [Masters, 1995; Красногорская, Ганцева, 2001; Solomatine, Dual, 2003].
Рассматриваемая в данной работе и описанная в предыдущей главе технология вероятностного задания значений переменных и анализа взаимосвязей между ними, позволяет предложить еще один прием прогнозирования, основывающийся на использовании соотношения (2.1.3.1), но с учетом особенностей его приложения к временным рядам. Практика применения этого приема позволяет говорить о его конкурентоспособности по отношению к вышеперечисленным методам. Изложим кратко основные положения предлагаемого алгоритма.
3.1.1. Достоверность и информативность прогнозных оценок
Любое предсказание во времени основывается на предположении о том, что некоторые закономерности, установленные в прошлом, остаются справедливыми и в будущем. Вероятность истинности такого предположения является одной из главных составляющих, определяющих достоверность прогноза. В общем случае эта вероятность неизвестна, и её величина также должна оцениваться в рамках некоторых допущений.
Достоверность результатов прогнозирования является очень важным свойством модели. Этот параметр довольно жестко связан с точностью модельных расчетов. Однако, формальное завышение точности или информативности предсказаний (как правило, за счет игнорирования или занижения нормативных ошибок прогноза) приводит к резкому снижению их достоверности. В прикладных задачах требования к выходным результатам часто оказываются завышенными по сравнению с реальными возможностями по информационному обеспечению модели. При использовании для построения модели одного и того же количества исходной информации, которая содержится в используемых временных рядах об их поведении в будущем, чем точнее или подробнее представляются прогностические результаты моделирования - тем они менее достоверны. Понятно, что существует разумный конструктивный компромисс - приемлемая точность результатов модельных оценок при их достаточной достоверности. Повышение точности (или подробности) результатов, при сохранении уровня их достоверности, возможно только за счет привлечения дополнительной информации и соответствующего усложнения модели.
Наиболее достоверным прогнозом, с практически 100%-й вероятностью истинности, является утверждение о том, что предсказываемая характеристика будет иметь значение, лежащее в пределах области ее теоретически возможной изменчивости. Однако такой прогноз совершенно неинформативен. Более информативный прогноз предсказываемой величины по материалам наблюдений ее изменчивости в прошлом может быть построен с использованием одного из методов, обсуждавшихся в предыдущем пункте. Достоверность такого предсказания определяется вероятностью того, что используемая для прогноза зависимость действительно существует и будет сохраняться в будущем.
Оценка и использование достоверности предсказаний – важный и необходимый элемент прогностических процедур. В зависимости от конкретной ситуации могут быть предложены различные способы вычисления соответствующих вероятностей. Там, где это не удается сделать, можно применять экспертные оценки. В среднем достоверность прогностической модели тем выше, чем в большем числе независимых испытаний оправдывались ее предсказания на ретроспективных данных. Игнорирование или необоснованное завышение достоверности прогнозов чаще всего приводит к отрицательным результатам при их некритическом использовании.
Существует множество предсказывающих алгоритмов, способных в той или иной мере решать прогностические задачи. Могут быть разработаны и новые (по отношению к известным) алгоритмы, опирающиеся на те же исходные данные. Однако независимо от применяемых методов имеют место ограничения достоверности и точности предсказаний, определяемые тем количеством информации о будущих значениях переменных, которое содержится в исходных данных, использованных для построения прогностических оценок.
3.1.2. Подготовка временных рядов для поиска в них прогностических закономерностей
Закономерности динамики рядов, на основе которых строятся прогностические модели, чаще всего ищутся в виде независимых от времени соотношений между значениями изменяющихся во времени переменных. Для того, чтобы можно было выявлять такие закономерности, данные о поведении прогнозируемых переменных в прошлом должны быть соответствующим образом подготовлены.
Полностью сформированная для анализа и прогноза таблица данных о динамике временных рядов в прошлом должна представлять собой последовательность оценок значений всех выбранных переменных, заданных с постоянным шагом по времени. Причем, начало, конец и временной шаг должны совпадать у всех рассматриваемых рядов. Однако в практике часто имеют место пропуски измерений или их несогласованность во времени. Кроме того, временной шаг задания исходных данных может не соответствовать тому временному разрешению, при котором предполагается исследовать динамические процессы. Поэтому в качестве подготовительной операции должна быть выполнена регуляризация временных рядов, то есть приведение всех их к стандартному шагу на общей временной шкале. Алгоритм регуляризации не должен вносить ложной информации в исходные материалы о динамике рядов. Выполнить это условие помогает вероятностное описание данных [Игнатов, 2000].
Анализ закономерностей изменчивости временных рядов практически не отличается от анализа таблицы совместных реализаций многомерного вектора. Единственное, что предварительно требуется – это сформировать из исходных временных рядов матрицу совместных реализаций, соответствующую проверяемой гипотезе. Рассмотрим эту операцию на примере одного динамического ряда, предварительно регуляризированного на интервале ![]() с разрешением Δt. Выберем максимальный сдвиг m шагов по времени между значениями предикторов и предиктанта. Отсчитаем от начала или конца ряда (m+1) значений и будем полагать их первой совместной реализацией (m+1) переменных. Вторая и последующие реализации получаются путем сдвига этого шаблона длиной (m+1) значений на один шаг Δt, соответственно вперед или назад, по времени. Таким образом, из одного временного ряда с числом членов
с разрешением Δt. Выберем максимальный сдвиг m шагов по времени между значениями предикторов и предиктанта. Отсчитаем от начала или конца ряда (m+1) значений и будем полагать их первой совместной реализацией (m+1) переменных. Вторая и последующие реализации получаются путем сдвига этого шаблона длиной (m+1) значений на один шаг Δt, соответственно вперед или назад, по времени. Таким образом, из одного временного ряда с числом членов 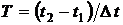 , при выбранной длине шаблона (m+1), получается матрица размером (m+1) переменных на (T-m) совместных реализаций. Естественно, если число исходных временных рядов равно k, то число переменных увеличивается в k раз и размер матрицы становится равным k*(m+1) переменных на (T-m) реализаций.
, при выбранной длине шаблона (m+1), получается матрица размером (m+1) переменных на (T-m) совместных реализаций. Естественно, если число исходных временных рядов равно k, то число переменных увеличивается в k раз и размер матрицы становится равным k*(m+1) переменных на (T-m) реализаций.
3.1.3. Алгоритмы экстраполяции временных рядов с помощью вероятностных моделей
Прогнозирование временных рядов на один шаг по времени. Для построения прогноза на один шаг (интервал) Δt по времени используются последние m интервалов регуляризированной системы временных рядов, по которым задаются фактические оценки значения предикторов (обозначим их для краткости ![]() ) прогнозируемой переменной y. Далее, на основании оценки совместного, полученного по данным прошлых наблюдений, распределения
) прогнозируемой переменной y. Далее, на основании оценки совместного, полученного по данным прошлых наблюдений, распределения ![]() строится условное распределение
строится условное распределение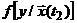 , оценивающее значение прогнозируемой переменной y на интервале (t2, t2+Dt). Достоверность этого прогноза определяется вероятностью сохранения установленного на отрезке наблюдений вида названного распределения также и на интервале прогнозирования.
, оценивающее значение прогнозируемой переменной y на интервале (t2, t2+Dt). Достоверность этого прогноза определяется вероятностью сохранения установленного на отрезке наблюдений вида названного распределения также и на интервале прогнозирования.
Прогнозирование динамики временных рядов на несколько шагов вперед с помощью моделей с различным запаздыванием предикторов. Другой способ составления прогноза временной динамики исследуемых переменных позволяет предсказать их значения на несколько шагов вперед. Он основывается на применении предсказательного алгоритма, заключающегося в подборе и использовании специальной группы моделей. В каждой из них значения предикторов смещены назад по времени по отношению к значениям предиктантов на разное количество шагов. Это дает возможность делать условные оценки предсказываемой переменной с различной заблаговременностью. Объединение результатов предсказания по каждой из таких моделей позволяет сделать прогностическую оценку динамики исследуемых временных рядов на некоторое количество (скажем на l) временных интервалов вперед. Причем для упреждения менее чем l интервалов можно построить две и более прогнозных оценок по разным моделям, что позволяет ставить вопрос об их объединении. Если бы эти оценки были независимы, то можно было бы объединить их по схеме «И» [Игнатов, 2000] и уточнить результаты прогноза. Однако это не так, поэтому можно выбрать из всех оценок наиболее информативную или объединить их по схеме «ИЛИ» и получить одно, но более достоверное, хотя и менее точное, предсказание. Последняя операция является более предпочтительной, так не исключено, что прогнозные оценки по различным моделям могут быть противоречивы. В этой ситуации отдание предпочтения одной из моделей по признаку, который сам по себе является случайной статистической оценкой, может оказаться ошибочным, что в результате приведет к уменьшению достоверности и, соответственно, ухудшению качества прогноза.
Итерационное прогнозирование временных рядов. При прогнозировании на один шаг значения зависимых переменных в прогностической модели предсказываются по известным значениям их аргументов. Эти значения находятся в таблице регуляризированных рядов в пределах сдвига на m шагов (максимальное запаздывание аргументов от функции) от их конца по времени.
Если есть необходимость предсказать значения группы временных рядов более чем на один шаг по времени, то операция прогнозирования может быть представлена в виде итерационного процесса. Для этого шаблон значений аргументов сдвигается на один шаг вперед, в результате чего значения функций, предсказанные на предыдущем (первом) шаге, становятся частью значений аргументов на текущем (втором). Затем делается предсказание на второй шаг. Для третьего и последующих шагов выполняются операции аналогичные проделанным на втором. При правильно построенном прогностическом алгоритме, информативность предсказаний, в среднем, не возрастает с увеличением их заблаговременности. Уменьшение информативности выражается в уменьшении достоверности прогноза или в увеличении его ошибки со временем.
3.1.4. Исследование свойств итерационного прогностического алгоритма на тестовом примере
Алгоритм совместного прогнозирования временных рядов количественных переменных, задаваемых интервальными оценками их значений, основанный на изложенных выше принципах и примененный впоследствии для прогнозирования притока в Байкал, впервые был написан автором для ЭВМ типа «БЭСМ-6» и «Эльбрус» на языке программирования «АЛГОЛ-ГДР». Свойства этого алгоритма перед применением к реальным данным исследовались на ряде тестовых примеров. Один из них приводится здесь и иллюстрирует реализацию постулата о существования модели оптимальной сложности, соответствующей количеству информации, содержащейся в используемой для ее построения выборке данных.
В рассматриваемом примере был взят периодический процесс, описываемый двумя переменными x(t) и y(t), подчиняющийся закону, формулируемому математической моделью вида:
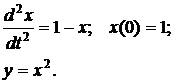 (3.1.2.1)
(3.1.2.1)
На временном отрезке (участке наблюдений) продолжительностью несколько менее пяти периодов с равномерным шагом генерировалось 30 значений временного ряда. Эти данные использовались для построения эмпирической прогностической модели и экстраполяции с ее использованием временного ряда еще на 20 шагов вперед.
Для решения задачи был выбран метод итерационного прогнозирования. Сложность модели определялась числом и точностью задания рассматриваемых переменных. В список аргументов прогнозируемой переменной x включались значения x и y на 4-х предшествующих временных интервалах. Для y в качестве аргумента задавалось только текущее значение x. Для расчетов использовалась формула типа (2.1.4.1). Интерполяции поверхности зависимости предсказываемой переменной от своих предикторов, при возникновении неопределенности типа «0/0», по ближайшим значениям функции не производилось. В ситуации такой неопределенности в качестве прогностической оценки выбиралось интервальное значение функции, соответствующее размаху ее изменчивости на участке наблюдений. Результаты тестового прогнозирования периодического процесса по моделям различной сложности приведены на рис.3.1.1. Показано только поведение функции x(t). Функция y(t) ведет себя похожим образом.
Модель (а). Точность определения переменных 0.01 от амплитуды изменения, число аргументов функции x(t) – 8. Модель чрезмерно сложная, ее информационная емкость неоправданно завышена. Исходных данных явно недостаточно для описания гиперповерхности связи. Информативные прогнозные оценки построить не удается.
Модель (б). Точность определения переменных 0.1 от амплитуды изменения, число аргументов функции x(t) – 6. Сложность модели избыточна. Прогноз неустойчивый. Возможны как достаточно точные, так и совершенно неопределенные предсказания. В результате случайной комбинации значений аргументов, после первого шага прогноза, произошло огрубление модели до близкого к оптимальному уровню сложности, и у модели появилась способность дальнейшего прогнозирования процесса.
Модель (в). Точность определения переменных 0.3 от амплитуды изменения, число аргументов функции x(t) – 6. Сложность модели близка к оптимальной. Прогноз устойчивый с медленным нарастанием ошибки предсказания по мере увеличения его заблаговременности.
Модель (г). Точность определения переменных составляет 0.5 от амплитуды изменения. Заданное число аргументов функции x(t) равняется шести. Сложность модели недостаточна для полного использования прогностической информации, содержащейся в исходных данных. Ошибка предсказания заметно возрастает уже при небольшой заблаговременности прогноза.
Модель (д). Точность определения переменных 0.5 от амплитуды изменения, число аргументов функции x(t) – 2. Модель слишком груба и не может в достаточной мере использовать прогностическую информацию, содержащуюся в исходных данных. Ошибка предсказания быстро возрастает и достигает максимального значения с увеличением заблаговременности прогноза.
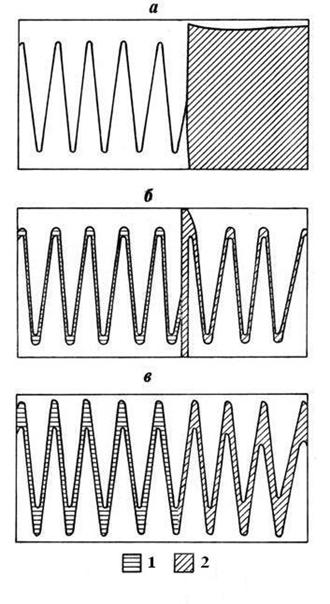
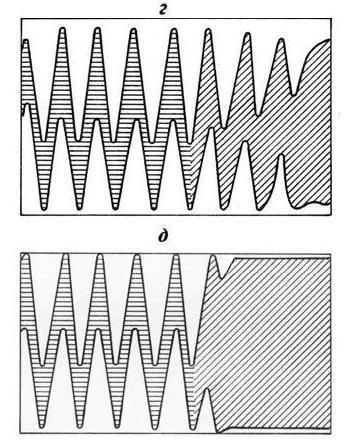
Рис. 3.1.1. Прогнозирование периодического процесса по моделям различной сложности (пояснения см. в тексте).
1 – интервал задания функции табличными данными,
2 – интервал предсказания функции по модели.
Интерпретируя результаты проведенного тестового эксперимента можно сказать, что модели (а) и (б), несмотря на их потенциальную способность давать отдельные высоко точные предсказания, являются недостаточно надежными, так как не позволяют построить информативные прогнозные оценки для любой возможной комбинации значений предикторов. В моделях (г) и (д) за счет чрезмерного повышения надежности прогноза, в большей или меньшей степени, потеряна его точность. Конструктивный компромисс сложности модели достигнут в варианте (в).
3.1.5. Программные средства для моделирования и прогнозирования временных рядов
Описываемые в данном пункте программные средства представляют собой новый, более современный вариант алгоритма, предназначенного для анализа, моделирования и прогноза временных рядов. Они входят в состав более обширного программно-информационного пакета, имеющего название «Система территориального мониторинга» [Игнатов, Кравченко, 2002]. Информацию об этой работе можно найти на странице Интернет [www. geogr. isu. ru/ig/index, 2002], которая была создана при участии автора совместно с и . Пакет программ сформирован с помощью среды программирования Delphi 5 [Архангельский, 2000; Фаронов, 2000]. Часть этого пакета, которая разрабатывалась, в основном, соискателем, носит название имитационной системы.
Имитационные системы являются дальнейшим этапом [Павловский, 2000] развития имитационного моделирования. Их главное отличие от имитационных моделей состоит в том, что они является средством более высокого уровня, реализующими процедуры поддержки накопления информации об объектах и построения на ее основе самых разнообразных моделей. В нашем случае для решения этих задач были разработаны:
· специфические форматы записи и хранения данных, дающие возможность накапливать в информационных базах системы различные сведения о значениях переменных и взаимосвязях между ними;
· база частных моделей, позволяющая записывать теоретические сведения и экспертные оценки в виде оригинальных алгоритмов оценки условных значений любой из контролируемых переменных;
· средства формирования прогностической задачи, помогающие скомпоновать уникальную для каждой решаемой задачи прогностическую модель;
· программные средства формулировки и проверки гипотез, дающие возможность исследовать закономерности совместной динамики переменных и строить модели на основе эмпирической информации.
Формирование прогностической задачи.
Одной из важнейших прикладных функций имитационной системы является возможность получать прогнозные оценки интересующих пользователя переменных.
Данные, накапливаемые в информационных базах имитационной системы, и ее программные средства позволяют формировать и решать два типа прогностических задач. В рамках задач первого типа оценивается поведение выбранного списка переменных в будущем в зависимости от их наблюдавшихся значений в прошлом. При решении прогностических задач второго типа - от ряда переменных, значения которых задаются пользователем. Управление формированием прогностической задачи осуществляется с помощью специального программного модуля, большинство функций которого разработано совместно . С помощью этого модуля производится:
· выбор и редакция переменных для параметризации воздействия и задание необходимых значений этих переменных;
· формирование и редакция списка переменных, поведение которых интересует пользователя;
· проверка наличия описаний необходимых прогностических связей в базе частных моделей и в базе описаний переменных;
· оценка недостающих прогностических связей на основе информации о временной динамике контролируемых переменных в прошлом;
· задание желаемого периода заблаговременности прогноза;
· просмотр исходных данных для прогностических расчетов (прогностические модели, воздействия и начальные условия, список прогнозируемых переменных).
Прогностические расчеты и визуализация их результатов.
После того как параметры воздействия и список обязательных для прогноза характеристик сформированы, пользователь может вызвать процедуру выполнения прогностических расчетов. Эта процедура выполняет следующие операции:
· по заданному списку воздействий и характеристик для прогноза анализирует имеющиеся в базе описаний переменных модели их взаимосвязи,
· формирует список совместно прогнозируемых параметров,
· синтезирует прогностическую модель из частных моделей,
· считывает из базы значений перемененных необходимые начальные условия,
· выполняет прогностические расчеты,
· формирует файл прогноза и заполняет его начальными условиями, заданными воздействиями и рассчитанными на основе моделей прогнозируемыми значениями переменных,
· открывает окно просмотра результатов прогноза.
Чтобы для произвольно выбранной переменной можно было бы, пусть с минимальной информативностью, оценить ее значения на интервале прогноза нужно, чтобы в базе описаний переменных или базе частных моделей была необходимая для этого информация. Это значит, что для каждой из прогнозируемых переменных должна существовать оценка зависимости ее предсказываемого значения от начальных условий или от задаваемых значений воздействия. При отсутствии информации о таких зависимостях программа выдает соответствующее предупреждение. Используемый математический аппарат приближенных оценок значений переменных с учетом их достоверности и вероятностного описания взаимосвязей между ними, конечно, позволяет произвести формальные прогностические расчеты для таких переменных, но их прогноз будет недостаточно информативен. При получении названного предупреждения пользователь может выбрать одну из альтернатив:
· проигнорировать предупреждение программы и продолжить расчеты, несмотря на полную или слишком большую неопределенность в оценках отдельных переменных;
· попытаться предварительно оценить и смоделировать недостающие прогностические связи, используя эмпирические данные, содержащиеся в базе значений переменных.
Выполнение прогностических расчетов осуществляется по итерационной схеме, описанной в пункте 3.1.3. После выполнения всех расчетов на очередном шаге прогноза, его результаты записываются типизированный файл, имеющий ту же структуру записей, что и база значений переменных. Работа прогнозирующей процедуры прекращается при достижении текущим временем (датой) прогноза конца указанного пользователем периода его заблаговременности. Результаты прогнозирования выдаются в табличной или графической форме. Пример см. на рис. 3.1.2. В левой части рисунка в виде графика показывается временной ход наиболее вероятного значения соответствующей характеристики. В правой части – гистограмма ее условного распределения в выбранный интервал времени.
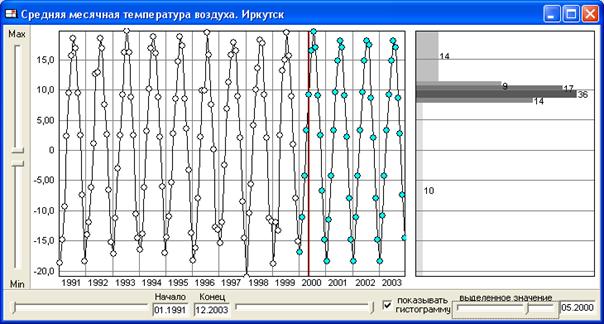
Рис.3.1.2. Окно графического вывода данных о значениях переменной в прошлом и результатов ее прогнозирования.
Построение прогностических моделей по данным о динамике переменных в прошлом.
Как уже говорилось ранее, при формировании конкретной прогностической задачи вполне может сложиться ситуация, когда для выполнения требуемых прогностических расчетов в базе моделей не находится необходимых связей между задаваемыми и рассчитываемыми характеристиками. В этом случае можно попытаться использовать информацию, содержащуюся в базе значений переменных и построить недостающие прогностические модели.
Для решения этой задачи разработана специальная программа, предназначенная для формулировки гипотетических моделей (гипотез о взаимосвязи переменных) и проверки их предсказательной способности по материалам о совместных значениях предполагаемых функций и их аргументов, содержащимся в базе значений переменных системы мониторинга. Главное и вспомогательные окна этой программы показаны на рис. 3.1.3.
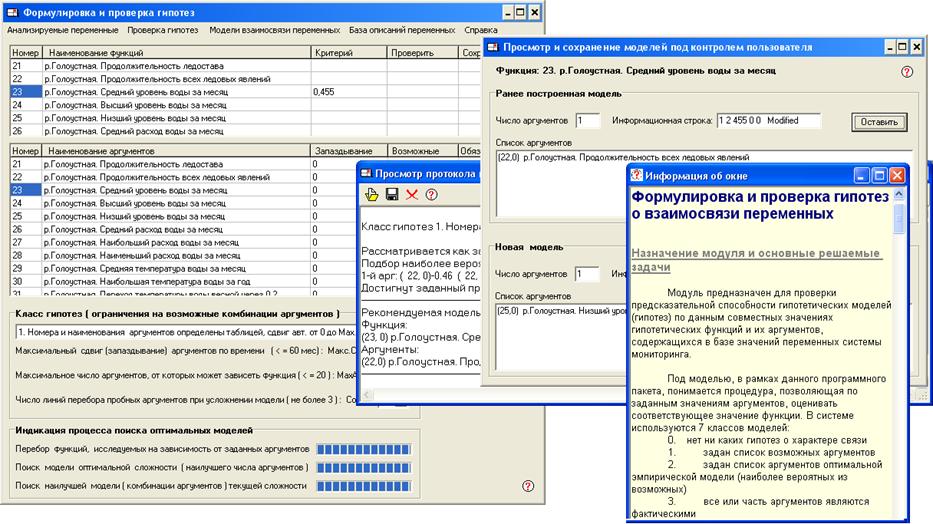
Рис. .3.1.1. Окна модуля, предназначенного для исследования закономерностей динамики временных рядов.
Главное окно – крайнее слева.
Данный модуль позволяет формировать списки переменных в таблицы функций и аргументов, добавлять и исключать переменные из этих таблиц, формулировать классы гипотез, включающие в себя различное количество гипотетических моделей. В процессе проверки гипотез можно оценивать и сравнивать между собой различные модели по их предсказательной способности. Программа сначала формирует модели из заданного класса и проверяет их предсказательную способность.
Проверка гипотез выполняется в порядке усложнения моделей от функций одного аргумента к функциям многих аргументов, числом вплоть до максимального заданного значения. Остановка процесса усложнения модели производится по окончанию тестирования всех проверяемых гипотез или при устойчивом ухудшении предсказательной способности моделей по мере их усложнения. Параметры наилучшей, из всех проверенных в рамках сформулированного класса гипотез запоминаются, и эта модель рекомендуется для использования в прогностических задачах.
Использование базы частных моделей
В заключение заметим, что прогностическая модель, построение которой базируется на информации о наблюдавшейся в прошлом изменчивости временных рядов, не могут (и не должны) давать предсказания, выходящие за пределы этой изменчивости. Для того, чтобы модель смогла преодолеть это ограничение, в нее должна закладываться дополнительные данные о закономерностях поведения прогнозируемых характеристик за пределами наблюдавшейся их изменчивости. Хорошо, если требуемые закономерности могут быть обоснованы теоретически, но обычно такая информация высказывается в виде предположений и носит гипотетический характер. Поэтому за возрастание прогностических возможностей модели, приходится платить снижением достоверности результатов прогнозирования.
В рамках рассматриваемого пакета техническим средством, предназначенным для внесения теоретических или гипотетических сведений в модель, служит база частных моделей. Внесение информации в эту базу осуществляется путем описания взаимосвязей между переменными с помощью специальных процедур. Перед использованием для решения прогностических задач отредактированная база моделей должна быть заново перекомпилирована.
