
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Каскадные процедуры снижения размерности
1, 2, 2, 3, 1
1Институт системного анализа РАН; 2Институт проблем передачи информации РАН; 3Центральный Аэрогидродинамический Институт им. проф.
Аннотация. В докладе описана задача снижения размерности, возникающая в процессе создания интеллектуальных компьютерных систем проектирования и поддержки принятия решений. Приведен краткий обзор основных используемых подходов и методов и предложен общий подход к построению каскадных процедур снижения размерности.
1. Постановка задачи снижения размерности
Интеллектуальные компьютерные системы проектирования и поддержки принятия решений включают в себя решение различных расчетных и оптимизационных задач, использующих цифровые описания объектов в качестве входных данных. Размерность цифрового описания объектов может достигать десятков тысяч чисел, поэтому при решении указанных задач необходимо в качестве первого шага решать задачу снижения размерности описания объекта, в том числе размерности геометрического описания [1].
В докладе мы будем придерживаться определений, введенных в работах [1 - 4], адаптированных к рассматриваемой в докладе задаче. Пусть
D = {X = X(b), b Î B} Ì RN (1)
множество цифровых описаний X(b) объектов b из рассматриваемого класса B.
Задача снижения размерности S = {m, Km, ![]() } состоит из размерности m, до которой сжимается цифровое описание объекта, и двух преобразований: сжатия:
} состоит из размерности m, до которой сжимается цифровое описание объекта, и двух преобразований: сжатия:
Km: D ® Lm = {l = Km(X), X Î D Ì RN} Ì Rm, (2)
преобразующего вектор X в m-мерный сжатый вектор l, и восстановления:
![]() : Lm ® Dm(L) = {
: Lm ® Dm(L) = {![]() (l), l Î Lm Ì Rm} Ì D Ì RN, (3)
(l), l Î Lm Ì Rm} Ì D Ì RN, (3)
преобразующего m-мерный сжатый вектор l в «полноразмерный» вектор X(l) Î D.
Качество процедуры снижения размерности S примененной к конкретному вектору X, будем характеризовать мерой близости
r(X) = ||X - ![]() (K(X))||1/2. (4)
(K(X))||1/2. (4)
между исходным вектором X и восстановленным вектором X* = ![]() (K(X)).
(K(X)).
В приложениях, как правило, класс объектов B и, как следствие, класс цифровых описаний D (1) формально не заданы и представляют собой нечетко заданные множества. Предполагается, что вся информация о множестве D содержится в конечной выборке:
Dn = {X1, X2, … , Xn} Ì D (5)
объема n, являющейся достаточно «репрезентативной» и содержит цифровые описания X(b) достаточного числа типичных представителей b из класса всех объектов B.
Результат усреднения
Rn = Rn(S|Dn) = 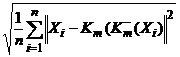 . (6)
. (6)
величин r по множеству Dn рассматривается как интегральная характеристика качества процедуры. Задача снижения размерности состоит в выборе минимального числа m и преобразований {Km, ![]() } таких, что величина Rn не превосходит заданного значения e.
} таких, что величина Rn не превосходит заданного значения e.
Без дополнительных предположений или ограничений сформулированная задача не имеет содержательного смысла, и можно построить «идеальную» процедуру S*, сжимающую цифровые описания до размерности m = 1 с нулевой ошибкой восстановления (6). Например [5], рассмотрим преобразование сжатия K1(X) = j Î R1, если X = Xj, j = 1, 2, … , n, и K1(X) = 0 в противном случае (предполагается, что все элементы множества Dn различны). Введем преобразование восстановления ![]() (l) = Xj при l = j Î {1, 2, … , n}, и
(l) = Xj при l = j Î {1, 2, … , n}, и ![]() (l) = 0 Î RN для остальных значений l. Очевидно, что Rn(S*|Dn) = 0, хотя процедура S* является бессмысленной.
(l) = 0 Î RN для остальных значений l. Очевидно, что Rn(S*|Dn) = 0, хотя процедура S* является бессмысленной.
Для придания смысла задаче мы ограничим себя выбранным классом преобразований, в котором ищутся наилучшие процедуры снижения размерности. Известны наилучшие процедуры в классе линейных преобразований (2), (3), например, Метод Главных Компонент и его обобщение в Методах Целенаправленного Проецирования [7 - 9]. Построены нелинейные процедуры в классе суперпозиций сигмоидальных функций [10, 11], радиальных базисных функций [12, 13], и др.
2. Ортогональные оснащенные нелинейные многообразия
Рассмотрим геометрическую интерпретацию задачи снижения размерности, описанную в работах [2, 3]. Преобразование восстановления ![]() (3) определяет в пространстве RN m-мерное параметрическое многообразие
(3) определяет в пространстве RN m-мерное параметрическое многообразие
Dm(Lm) = {![]() (l), l Î Lm Ì Rm} Ì RN, (7)
(l), l Î Lm Ì Rm} Ì RN, (7)
точки которого параметризованы с помощью m-мерного параметра l Î Lm, компоненты которого можно считать внутренними координатами точек на многообразии (7). Отсюда следует [3], что преобразование сжатия Km определяет вектор внутренних координат l(X), соответствующий проекции X* = ![]() (l(X)) вектора X на многообразие Dm(Lm). Ошибка процедуры снижения размерности равна расстоянию между векторами X и X*.
(l(X)) вектора X на многообразие Dm(Lm). Ошибка процедуры снижения размерности равна расстоянию между векторами X и X*.
Пусть при фиксированном преобразовании восстановления ![]() , для произвольного вектора X точка
, для произвольного вектора X точка ![]() является ближайшей к X точкой на многообразии Dm(Lm), имеющей вектор внутренних координат l*(X):
является ближайшей к X точкой на многообразии Dm(Lm), имеющей вектор внутренних координат l*(X):
l*(X) = arg minlr(X, ![]() (l)) Î Lm,
(l)) Î Lm, ![]() (X) =
(X) = ![]() (l*(X)) Î Dm(Lm). (8)
(l*(X)) Î Dm(Lm). (8)
Рассмотрим [3] новое преобразование сжатия ![]() :
:
![]() (X) = l*(X) Î Lm, (9)
(X) = l*(X) Î Lm, (9)
и соответствующую процедуру снижения размерности S* = {m, ![]() ,
, ![]() }, для которой всегда имеет место неравенство R(m,
}, для которой всегда имеет место неравенство R(m, ![]() ,
, ![]() ) £ R(m, Km,
) £ R(m, Km, ![]() ).
).
Отсюда следует, что при фиксированной размерности m достаточно построить многообразие проектирования Dm(Lm), определяемое преобразованием восстановления ![]() , а преобразование сжатия определить затем по формулам (8), (9). Обозначим:
, а преобразование сжатия определить затем по формулам (8), (9). Обозначим:
Fm(Q) = {F(l, q) = (F1(l, q), F2(l, q), … , Fm(l, q)), q Î Q} (10)
выбранный класс N-мерных гладких вектор-функций от m-мерного аргумента l, индексированных параметром q (в общем случае, бесконечномерным). Задача построения наилучшей процедуры снижения размерности сводится к минимизации функционала
S = S(q, Dn) = 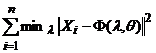 . (11)
. (11)
При среднеквадратичной метрике (4) в классе линейных функций (11) решение задачи минимизации дает Метод Главных Компонент.
Пусть в результате минимизации (12) выбрана вектор-функция F(l) Î Fm(Q). Наилучшее преобразование сжатия ![]() (9) для произвольного вектора X Î D определяет остаток D(X) = X -
(9) для произвольного вектора X Î D определяет остаток D(X) = X - ![]() (X) Î RN, который ортогонален m векторам
(X) Î RN, который ортогонален m векторам
et(l*(X)) = (et1(l*(X)), et2(l*(X)), … , etN(l*(X))) Î RN, t = 1, 2, … , m, (12)
где
etr(l) = ![]() , t = 1, 2, … , m, r = 1, 2, … , N.
, t = 1, 2, … , m, r = 1, 2, … , N.
Для каждого значения l Î Lm рассмотрим (N – m)-мерное аффинное линейное подпространство L(l), проходящее через точку ![]() (l) Î Dm(Lm), ортогональное N-мерным векторам et(l), t = 1, 2, … , m, (12). В соответствии с определением в [14], многообразие проектирования является гладким оснащенным многообразием, и для вектора X Î D остаток D(X) принадлежит аффинному подпространству L(l*(X)).
(l) Î Dm(Lm), ортогональное N-мерным векторам et(l), t = 1, 2, … , m, (12). В соответствии с определением в [14], многообразие проектирования является гладким оснащенным многообразием, и для вектора X Î D остаток D(X) принадлежит аффинному подпространству L(l*(X)).
В работе [3] предложена итеративная процедура построения оснащенных многообразий проектирования Dm(Lm) в виде произведения семейств одномерных ортогональных подпространств проектирования. На основании методов работы [3], в [4] предложена обобщенная процедура снижения размерности цифрового описания при наличии частных параметрических моделей.
3. Каскадные процедуры снижения размерности
В докладе рассматривается класс каскадных процедур снижения размерности, состоящих в последовательном применении трех процедур снижения размерности:
- обобщенной процедуры снижения размерности S(M) при наличии частных параметрических моделей M [4]; весовом методе главных компонент S(PCA) с итеративным выбором весов [15]; методе построения оснащенных многообразий проектирования [3] на базе класса Обобщенных Автоассоциативных искусственных нейронных сетей S(ANN) [11].
Каскадная процедура последовательно строит дерево процедур снижения размерности. Каждому ребру дерева приписана некоторая процедура снижения размерности данных, находящихся в вершине, из которого выходит ребро, а результат записывается в вершину, которой заканчивается ребро.
Корневая вершина V0 содержит исходную выборку Dn (5). Пусть в рассматриваемой задаче известны d частные параметрические модели M1, M2, … , Md (случай d = 0 не исключается). Тогда из вершины V0 выходит d ребер E01, E02, … , E0d, соответствующих этим моделям, и несколько ребер, соответствующих весовому методу главных компонент с итеративным выбором весов [15].
Вершины первого уровня. Ребру E0s при s £ d приписывается обобщенная процедура снижения размерности, соответствующая частной модели Ms, s = 1, 2, … , d, состоящая в следующем. Модель Ms определяет в пространстве RN k(s)-мерное многообразие
Fs = {fs(gs), gs Î Gs Ì Rk(s)} Ì RN, (13)
порожденную непрерывно дифференцируемой вектор-функцией
fs(gs) = (fs1(gs), fs2(gs), … , fsN(gs))
от k(s)-мерного аргумента gs = (gs1, gs2, … , gs, k(s)). Определим соответствующую процедуру снижения размерности S(Ms) = {k(s), Cs, ![]() }, состоящую из наилучшего преобразования сжатия Cs(X) = gs(X) = arg mingr(X, fs(g)), получающегося путем проектирования вектора X на многообразие Ds(Gs) (13), и преобразования восстановления
}, состоящую из наилучшего преобразования сжатия Cs(X) = gs(X) = arg mingr(X, fs(g)), получающегося путем проектирования вектора X на многообразие Ds(Gs) (13), и преобразования восстановления ![]() (gs) = fs(gs).
(gs) = fs(gs).
Построим (N – k(s))-мерное аффинное подпространство Ls(gs), проходящее через точку fs(gs) Î Fs и ортогональную k(s) N-мерным векторам est(gs), t = 1, 2, … , k(s), состоящих из частных производных
estr(gs) = 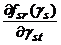 , t = 1, 2, … , k(s), r = 1, 2, … , N.
, t = 1, 2, … , k(s), r = 1, 2, … , N.
Обозначим Ysi = Xi - fs(gs(Xi)), i = 1, 2, … , n, остатки после применения преобразований сжатия/восстановления к выборке Dn (5).
При s > d рассмотрим процедуру построения главных компонент по множеству данных Dn (5), основанную на итеративном алгоритме [15]. Ребру E0s приписывается процедура, использующая первые k(s) = s - d главных компонент. Обозначим Ls подпространство размерности (N – k(s)), ортогональное к ним.
Пусть fs(gs(X)), s > d, есть проекция вектора X на первые k(s) главных компонент, и gs(X) есть вектор координат разложения fs(gs(X)) по ортогональному базису из главных компонент. Очевидно, что векторы остатков Ys(X) = X - fs(gs(X)) лежат в подпространстве Ls, и пусть Ysi = Ysi(Xi), i = 1, 2, … , n.
Поместим в вершину V1s данные Ysn = {Ys1, Ys2, … , Ysn}, и вычислим величины Rns = 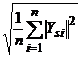 . Каждой вершине V1s припишем индекс (k(s); Rns). Обозначим
. Каждой вершине V1s припишем индекс (k(s); Rns). Обозначим
k1(e) = min{k(s): Rns £ e}, (14)
V(1) = {V1s: k(s) = k1(e)}; V(1-) = {V1s: k(s) ³ k1(e), Rns > e}; (15)
V(1+) = {V1s: k(s) < k1(e), s £ d}; V(1++) = {V1s: k(s) < k1(e), s > d}.
Из вершин из множеств (15) далее не выходят ребра (они являются висячими вершинами).
Вершины второго уровня. Рассмотрим вершину V1s Î V(1+). Пусть PCAsk – линейное подпространство, натянутое на первые k главных компоненты, k £ k1(e) - k(s), построенных по множеству Ysn с помощью метода [15]. Для вектора gs Î Gs обозначим PCAsk(gs) проекцию подпространства PCAsk на Ls(gs), и пусть в аффинном подпространстве PCAsk(gs) размерности k построен базис Esk(gs) = (esk1(gs), esk2(gs), … , eskk(gs)).
Для произвольного вектора Y построим его проекцию gsk(bsk(Y|gs)) на подпространство PCAsk(gs) с координатами bsk(Y|gs) в базисе Esk(gs). Определим процедуру снижения размерности S(PCAsk|gs) = {k, Psk( |gs), ![]() }, cостоящую из преобразования сжатия Psk(Y|gs) = bsk(Y|gs) и преобразования восстановления
}, cостоящую из преобразования сжатия Psk(Y|gs) = bsk(Y|gs) и преобразования восстановления ![]() (bsk|gs) = gsk(bsk|gs), определяющего вектор, имеющий координаты bsk в базисе Esk(g). Обозначим Lsk(gs) подпространство в Ls(gs), ортогональное PCAsk(gs), и пусть
(bsk|gs) = gsk(bsk|gs), определяющего вектор, имеющий координаты bsk в базисе Esk(g). Обозначим Lsk(gs) подпространство в Ls(gs), ортогональное PCAsk(gs), и пусть
Zsk(X) = Ys(X) – gsk(bsk(Ys(X)|gs(X))|gs(X)), Zski = Zsk(Xi), i = 1, 2, … , n.
При s £ d обозначим E1sk ребро, выходящее из вершины V1s, которому приписана процедура снижения размерности S(PCAsk|gs), которое ведет в вершину V2sk.
Рассмотрим теперь произвольную вершину V1s Î V(1++). По выборке Ysn с использованием метода [3] построим Автоассоциативные искусственные нейронные сети [11], в которой в «перетяжках» находятся k узлов, k = 1, 2, … , k1(e) - k(s). Пусть при s > d k-мерный вектор bsk равен значению аргумента в узлах перетяжки, тогда «восстанавливающая» компонента нейронной сети определяет отображение вектора bsk в вектор gsk(bsk) Î Ls размерности (N – k(s)), которое, в свою очередь, порождает оснащенное многообразие Gsk = {gsk(bsk)} Ì RN-k(s). Определим при s > d процедуру снижения размерности S(ANNsk) = {k, Qsk, ![]() }, cостоящую из преобразования сжатия Qsk(Y) = bsk(Y) = arg minbr(Y, gsk(b)) и преобразования восстановления
}, cостоящую из преобразования сжатия Qsk(Y) = bsk(Y) = arg minbr(Y, gsk(b)) и преобразования восстановления ![]() (bsk) = gsk(bsk).
(bsk) = gsk(bsk).
Обозначим Zsk(X) = Ys(X) – gsk(bsk(Ys(X));Zski = Zsk(Xi), i = 1, 2, … , n.
Замечание. Векторы bsk(Y) при s > d от параметра gs не зависят. Однако нам удобно будет записывать их в виде bsk(Y|gs), понимая, что они при s > d от параметра gs не зависят.
При s > d обозначим E1sk ребро, выходящее из вершины V1s, которому приписана процедура снижения размерности S(ANNsk), которое ведет в вершину V2sk.
Обозначим Zskn = {Zsk1, Zsk2, … , Zskn} множество остатков, и вычислим величины Rnsk = 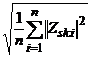 . Каждой вершине V2sk припишем индекс (k(s) + k; Rnsk) и обозначим
. Каждой вершине V2sk припишем индекс (k(s) + k; Rnsk) и обозначим
k2(e) = min{k(s) + k: Rnsk £ e}, V(2+) = {V2sk: k(s) + k < min(k1(e), k2(e)),s £ d}.
Если множество V(2+) пустое, то вершины третьего уровня не строятся, и выбирается наилучшая процедура снижения размерности.
Вершины третьего уровня. Для каждой вершины V2sk Î V(2+) по выборке Zskn с использованием метода построения оснащенных многообразий проектирования [3] построим Автоассоциативные искусственные нейронные сети [11], в которой в «перетяжках» находятся j узлов, j = 1, 2, … , (min(k1(e), k2(e)) – (k(s) + k)). Пусть j-мерный вектор hskj равен значению аргумента в узлах перетяжки, тогда «восстанавливающая» компонента нейронной сети определяет отображение вектора hskj в вектор Hskj(bskj) размерности N, которое, в свою очередь, порождает оснащенное многообразие Gskj, состоящее из значений векторов Hskj(hskj). Пусть Gskj(gs) обозначает проекцию многообразия Gskj на подпространство Lsk(gs), соответствующее проекции Hskj(hskj|gs) вектор-функции Hskj(hskj) на Lsk(gs). Определим процедуру снижения размерности S(ANNskj|gs) = {j, Qskj( |gs), 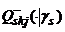 }, cостоящую из преобразования сжатия
}, cостоящую из преобразования сжатия
Qskj(Z|gs) = hskj(Z|gs) = arg minhr(Z, Hskj(h|gs));
и преобразования восстановления ![]() (hskj|gs)) = Hskj(hskj|gs).
(hskj|gs)) = Hskj(hskj|gs).
Обозначим E2skj ребро, выходящее из вершины V2sk ведущее в вершину V3skj, которому приписана процедура снижения размерности S(ANNskj). Обозначим
Uskj(X) = Zsk(X) - Hskj(hskj(Zsk(X)|gs(X))|gs(X)),
Uskji = Uskj(Xi), i = 1, 2, … , n, Rnskj = 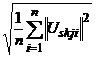 .
.
и каждой вершине V3skj припишем индекс (k(s) + k + j; Rnskj).
Наилучшая каскадная процедура снижения размерности. Обозначим
k3(e) = min{k(s) + k + j: Rnskj £ e}, k0(e) = min(k1(e), k2(e), k3(e)),
и пусть V(e) = {V3skj: k(s) + k + j = k0(e); (s, k, j) Î S}, где
S = {(s, k, j): 1 £ s £ d + n0(e); 0 £ k £ k1(e) - k(s); 0 £ j £ min(k1(e), k2(e)) – (k(s) + k))},
и, по определению, V3sk0 = V2sk; V2s0 = V1sj.
Каждая вершина V3skj Î V(e) определяет последовательность ребер (E0sk, E1sk, E2skj), ведущих из корневой вершины в вершину V3skj. Полагая по определению Rnsk0 = Rnsk, Rns0 = Rns, выберем из множества V(e) ту вершину V3skj, для которой величина Rnskj минимальна. Если таких вершин несколько, выберем ту из них, при которой суммарная вычислительная сложность процедур снижения, приписанных последовательности ребер, ведущих из корневой вершины в выбранную вершину, минимальна.
Последовательность ребер, соответствующая выбранной вершине V3skj, определяет каскадную процедуру снижения размерности Sskj, состоящую из преобразования сжатия
Tskj(X) = askj(X) = (gs(X), bsk(Ys(X)|gs(X)), hskj(Zsk(X)|gs(X)));
и преобразования восстановления: для askj = (gs, bsk, hskj)
![]() (askj) = fs(gs) + gsk(bsk|gs) - Hskj(hskj|gs).
(askj) = fs(gs) + gsk(bsk|gs) - Hskj(hskj|gs).
Выбранная каскадная процедура Sskj удовлетворяет заданным требованиям по точности и имеет минимальную размерность k(s) + k + j = k0(e) (44) сжатого вектора askj.
Литература
1. Кулешов технологии в основанных на данных адаптивных моделях сложных объектов. Информационные технологии и вычислительные системы, 2008, № 1, с. 95 - 106.
2. , . Когнитивные технологии в проблеме снижения размерности описания геометрических объектов. Информационные технологии и вычислительные системы, 2008, № 2.
3. , Кулешов ортогональных нелинейных многообразий в задачах снижения размерности. Тезисы докладов VII Международной школы-семинара «Многомерный статистический анализ и эконометрика» (Цахкадзор, 2008).
4. , . Снижение размерности сложных геометрических объектов при наличии частных параметрических моделей. Информационные технологии и вычислительные системы, 2008, № 3.
5. . Пример «идеальной» процедуры снижения размерности. Частное сообщение, 2008.
6. Т. Андерсон. Введение в многомерный статистический анализ. М., Физматгиз, 1963.
7. , , . Классификация и снижение размерности. Москва, Финансы и статистика, 1989.
8. J. H.Friedman, J. W. Tukey. A projection pursuit algorithm for exploratary data analysis. IEEE puters, C-23: 881-889, 1974.
9. P. J. Huber. Projection pursuit. Annals of Statistics, 13(2): 435-475, May 1985.
10. G. Cybenko Approximation by Superpositions of a Sigmoidal Function. Mathematical Control Signals Systems, 1989, 2.
11. M. A. Kramer. Nonlinear Principal Component Analysis Using Autoassociative Neural Networks. Jopurnal of the American institute of Chemical Engineers (AIChE). V. 1, No 2, p. 233 – 242, February 1991.
12. A. R. Webb. An approach to non-linear principal component analysis using radially symmetric kernel functions. Statistics and Computing, 1996, 6, 159 – 168.
13. D. J.H. Wilson, G. W. Irwin, G. Lightbody. RBF principal manifolds for process monitoring. IEEE Transactions on Neural Networks, 1999, 10(6), 1424 – 1434.
14. . Гладкие многообразия и их применение в теории гомотопий. Труды МИАН, т. 45, М., изд-во АН СССР, 1955.
15. , . Об итеративном алгоритме подсчета взвешенных главных компонент. Информационные процессы (электронный журнал http://www. jip. ru/Contents. htm). 2008, т. 8, № 2, с. 1 – 9.
