Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Прогнозирование непрерывных столбцов
Когда алгоритм дерева принятия решений (Майкрософт) строит дерево, основанное на непрерывном прогнозируемом столбце, каждый узел содержит регрессионную формулу. Разбиение осуществляется в точке нелинейности в этой регрессионной формуле. Например, рассмотрим следующую диаграмму.
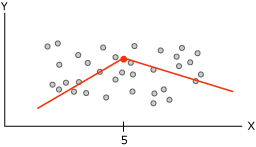
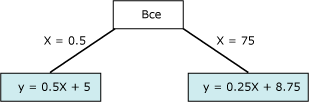
Диаграмма содержит данные, которые можно моделировать либо используя одиночную линию, либо используя две соединенные линии. Однако одиночная линия не обеспечит надлежащего представления данных. Вместо этого при использовании двух линий модель обеспечит гораздо более точное приближение данных. Точка соединения этих двух линий является точкой нелинейности и представляет собой точку, в которой разобьется узел в модели дерева решений. Например, узел, соответствующий точке нелинейности на предыдущем графике, может быть представлен следующей диаграммой. Эти два уравнения представляют регрессионные уравнения для этих двух линий.
Настройка параметров модели
Модель дерева решений должна содержать ключевой столбец, входные столбцы и один прогнозируемый столбец.
В следующей таблице перечислены конкретные типы содержимого входных столбцов, типы содержимого прогнозируемых столбцов и флаги моделирования, поддерживаемые алгоритмом дерева принятия решений (Майкрософт).
Типы содержимого входных столбцов | Непрерывные, циклические, дискретные, дискретизированные, ключевые, табличные и упорядоченные |
Типы содержимого прогнозируемых столбцов | Непрерывные, циклические, дискретные, дискретизированные, табличные и упорядоченные |
Флаги моделирования | MODEL_EXISTENCE_ONLY, NOT NULL и REGRESSOR |
Все алгоритмы Майкрософт поддерживают общий набор функций. Однако алгоритм дерева принятия решений (Майкрософт) поддерживает дополнительные функции, перечисленные в следующей таблице.
Прогнозирующая функция | Использование |
IsDescendant (расширения интеллектуального анализа данных) | Определяет, является ли узел дочерним для другого узла модели. |
IsInNode (расширения интеллектуального анализа данных) | Указывает, содержит ли заданный узел текущий вариант. |
PredictAdjustedProbability (расширения интеллектуального анализа данных) | Возвращает взвешенную вероятность. |
PredictAssociation (расширения интеллектуального анализа данных) | Прогнозирует вхождение в ассоциативном наборе данных. |
PredictHistogram (расширения интеллектуального анализа данных) | Возвращает таблицу значений, связанную с текущим прогнозируемым значением. |
PredictNodeId (расширения интеллектуального анализа данных) | Возвращает параметр Node_ID для каждого случая. |
PredictProbability (расширения интеллектуального анализа данных) | Возвращает вероятность для прогнозируемого значения. |
PredictStdev (расширения интеллектуального анализа данных) | Возвращает прогнозируемое стандартное отклонение для заданного столбца. |
PredictSupport (расширения интеллектуального анализа данных) | Возвращает опорное значение для указанного состояния. |
Алгоритм дерева принятия решений (Майкрософт) поддерживает использование языка разметки прогнозирующих моделей (PMML) для создания моделей интеллектуального анализа данных.
Алгоритм дерева принятия решений (Майкрософт) поддерживает несколько параметров, влияющих на производительность и точность получающейся в результате модели интеллектуального анализа данных. В следующей таблице содержатся описания всех параметров.
Параметр | Описание |
MAXIMUM_INPUT_ATTRIBUTES | Определяет количество входных атрибутов, которые алгоритм может обработать перед вызовом выбора компонентов. Установите значение 0, чтобы отключить выбор компонентов. Значение по умолчанию равно 255. |
MAXIMUM_OUTPUT_ATTRIBUTES | Определяет количество выходных атрибутов, которые алгоритм может обработать перед вызовом выбора компонентов. Установите значение 0, чтобы отключить выбор компонентов. Значение по умолчанию равно 255. |
SCORE_METHOD | Определяет метод, используемый для вычисления коэффициента разбиения. Доступные параметры: Энтропия (1), априорный метод Байеса с K2 (2) или априорный эквивалент Дирихле метода Байеса (BDE) (3). Значение по умолчанию равно 3. |
SPLIT_METHOD | Определяет метод, используемый для разбиения узла. Доступные параметры: двоичный (1), полный (2) или оба (3). Значение по умолчанию равно 3. |
MINIMUM_SUPPORT | Определяет минимальное количество конечных вариантов, необходимых для формирования разбиения в дереве решений. Значение по умолчанию равно 10. |
COMPLEXITY_PENALTY | Управляет ростом дерева решений. Низкое значение увеличивает количество разбиений, а высокое количество — уменьшает. Значение по умолчанию основано на количестве атрибутов для конкретной модели, как описано в следующем списке. · Для атрибутов с 1 по 9 значением по умолчанию является 0,5. · Для атрибутов с 10 до 99 значением по умолчанию является 0,9. · Для 100 или более атрибутов значением по умолчанию является 0,99. |
FORCED_REGRESSOR | Приводит алгоритм к использованию указанных столбцов в качестве регрессоров, не обращая внимания на важность столбцов, вычисленную алгоритмом. Этот параметр используется только для деревьев решений, прогнозирующих непрерывный атрибут. |
Структура дерева решений
Модель дерева принятия решений содержит один родительский узел, представляющий модель и ее метаданные. Под родительским узлом находятся независимые деревья, представляющие выбранные прогнозируемые атрибуты. Например, если настроить модель дерева принятия решений для прогнозирования покупок, совершаемых клиентами, и задать входные значения пола и дохода, то модель создаст одно дерево для атрибута покупки со множеством ветвей, разделяющихся по условиям, связанных с полом и доходом.
Однако если затем добавить отдельный прогнозируемый атрибут для участия в поощрительной программе, алгоритм создаст два отдельных дерева под родительским узлом. Одно дерево содержит анализ для совершения покупки, а второе — анализ для участия в поощрительной программе. Если использовать алгоритм деревьев принятия решений для создания модели взаимосвязей, алгоритм создает отдельное дерево для каждого прогнозируемого товара, и это дерево содержит все сочетания других товаров, отвечающие выбору целевого атрибута.
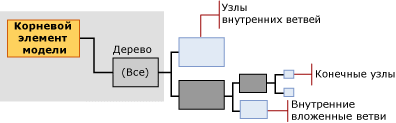
Дерево для каждого прогнозируемого атрибута содержит сведения, описывающие, как выбранные входные столбцы влияют на выходные данные этого прогнозируемого атрибута. Вверху каждого дерева находится узел (NODE_TYPE = 9), содержащий прогнозируемый атрибут, а затем следует ряд узлов (NODE_TYPE = 10), которые представляют входные атрибуты. Атрибут соответствует столбцу уровня вариантов или значениям столбцов вложенной таблицы, которые обычно находятся в столбце Key вложенной таблицы.
Внутренние и конечные узлы представляют условия разбиения. Дерево может разбиваться несколько раз по одному атрибуту. Например, модель TM_DecisionTree может разбиваться по атрибутам [Yearly Income] и [Number of Children], а на следующем участке дерева вновь разбиваться по атрибуту [Yearly Income].
Алгоритм дерева принятия решений (Майкрософт) также может содержать линейные регрессии во всем дереве или в его части. Если моделируемый атрибут имеет непрерывный числовой тип данных, модель может создать узел дерева регрессии (NODE_TYPE = 25) там, где связь между атрибутами может моделироваться линейно. В этом случае узел содержит формулу регрессии.
Однако если прогнозируемый атрибут имеет дискретные значения, а также если его числовые значения сегментированы или дискретизированы, то модель всегда создает дерево классификации (NODE_TYPE =2). Дерево классификации может иметь несколько ветвей или внутренних узлов дерева (NODE_TYPE =3) для каждого значения атрибута, однако не для каждого значения атрибута выполняется разбиение.
Алгоритм дерева принятия решений (Майкрософт) не допускает входные данные непрерывных типов. Поэтому, если какие-либо столбцы имеют непрерывный числовой тип данных, их значения дискретизируются. Для всех непрерывных атрибутов алгоритм самостоятельно выполняет дискретизацию в момент разбиения.
Ассоциативные правила
Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила, служит утверждение, что покупатель, приобретающий 'Хлеб', приобретет и 'Молоко' с вероятностью 72%. Первый алгоритм поиска ассоциативных правил, называвшийся AIS был разработан в 1993 году сотрудниками исследовательского центра IBM Almaden. С этой работы возрос интерес к ассоциативным правилам; на середину 90-х годов прошлого века пришелся пик исследовательских работ в этой области, и с тех пор каждый год появлялось по несколько алгоритмов.
Впервые эта задача была предложена для поиска ассоциативных правил для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Анализ рыночной корзины
Пусть имеется база данных, состоящая из покупательских транзакций. Каждая транзакция – это набор товаров, купленных покупателем за один визит. Такую транзакцию еще называют рыночной корзиной.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)