


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Модуль Анализ естественного языка при разработке интерфейсов автоматизированных систем
o Основные характеристики и составляющие части ЕЯ-интерфейсов. 1
o Сравнительный анализ ЕЯ-интерфейсов и традиционных интерфейсов к СИД.. 1
Преимущества ЕЯ-интерфейсов. 2
Недостатки: 3
o Критерии качества ЕЯ-интерфейсов. 3
o Критерии стоимости построения и сопровождения ЕЯ-интерфейса. 4
o Основные составные части ЕЯ-интерфейсов к СИД.. 5
o Проблемы общения с ЭВМ на ЕЯ, связанные с особенностями естественного языка. 6
o Семантически-ориентированный анализ ЕЯ, ориентированный на распознавание смысла предложения. 8
o Распознавание смысла предложений ЕЯ. 9
Распознавание смысла ЕЯ с помощью шаблонов. 10
Распознавание смысла ЕЯ с помощью падежных фреймов. 10
o Основные характеристики и составляющие части ЕЯ-интерфейсов
В современном информационном мире проблемы доступа пользователей к различным компьютерным источникам информации встают чрезвычайно остро. С возникновения первых компьютеров задача хранения данных была и остается одной из главных. И одновременно с появлением первых хранилищ данных появились системы, которые облегчали доступ к данным.
Под пользовательским интерфейсом к структурированным источникам данных в данной работе понимается система средств, облегчающих поиск, получение, просмотр и обработку информации из внешней системы - структурированного источника данных (СИД). Естественно-языковой интерфейс (ЕЯИ) - разновидность пользовательского интерфейса, который принимает запросы на естественном языке, а также, возможно, использует ЕЯ и для вывода информации (реакции системы на запрос пользователя).
o Сравнительный анализ ЕЯ-интерфейсов и традиционных интерфейсов к СИД
В противоположность ЕЯ-интерфейсам, нетрадиционным с точки зрения распространенности, существуют другие виды пользовательских интерфейсов к СИД, которые можно назвать традиционными. Среди них:
· Интерфейсы с формальным языком запросов
· Интерфейсы с графическим построением запросов
· Интерфейсы, основанные на заполнении форм запросов
Предполагается, что рассматриваемые здесь виды интерфейсов по своему предназначению ограничены только получением информации из базы данных, это предположение сделано в силу ограничения на ЕЯ-интерфейсы областью запросов, поскольку область занесения данных и их модификации с помощью естественно-языковых оболочек является отдельной большой темой для рассмотрения.
В интерфейсах с формальным языком запросов пользователь, для того, чтобы правильно задать запрос, должен, во-первых, знать синтаксис языка запросов (например, SQL), а во-вторых, представлять устройство конкретного структурированного источника данных (например, реляционную схему базы данных). При работе с этим типом интерфейсов пользователь должен обладать достаточно высокой квалификацией. Опыт показывает, что такой необходимой квалификацией обладают лишь специалисты, проектирующие и создающие информационные системы, и сам термин "пользователь" с учетом современных тенденций здесь не совсем адекватен. Очевидно, ЕЯ-интерфейсы обладают большей гибкостью - один и тот же запрос обычно можно формулировать различными способами. Что немаловажно, ЕЯ-интерфейсы, как правило, обладают системой понятий - описанием предметной области, которая находится выше логического уровня хранения данных. Это позволяет абстрагироваться от деталей устройства той или иной базы данных как на уровне структуры, так и на уровне содержимого.
Средства графического построения запросов, которыми снабжаются многие "настольные" СУБД (например, MS Access, MS FoxPro), безусловно, обладают большим удобством - по крайней мере пользователь не должен держать в голове названия таблиц, полей и конструкции языка. Однако для работы с такими средствами необходим опыт и представление некоторых понятий, относящихся скорее к математике (например, термин связывания таблиц в реляционной алгебре), а не к предметной области, и иногда достаточно утомительные действия по заполнению форм. Так, в базе данных Microsoft Access для того, чтобы сформулировать выражение AVG(PERSONNEL. SALARY), эквивалентный ЕЯ-фразе "средняя зарплата", требуется около 15 нажатий мышью. Неподготовленный пользователь обычно пасует перед системами, требующими сложных действий. Как и в случае интерфейсов с формальным языком, пользователь должен представлять устройство базы данных. По сути, эти средства позволяют графически создавать формальные запросы, и не случайно они обычно позволяют редактировать пользователя полученный формальный запрос.
Интерфейсы, основанные на заполнении форм запросов, являются более дружественными, по сравнению с формальными языками. Сама метафора формы и ее заполнения подразумевает, что пользователь сразу видит набор критериев и параметров поиска, а иногда и список возможных значений полей формы, это сводит к минимуму ошибки при вводе запроса. От предыдущего метода построения пользовательских интерфейсов данный отличается тем, что как правило, все необходимые запросы уже написаны разработчиком интерфейса, и пользователь, чтобы получить ответ, должен просто вставить недостающие значения. Отличие заключается также в том, что задавая значения формы, пользователь обычно не выбирает, какие атрибуты данного класса объектов будут в результате, а сам список доступных классов (в реляционной базе - таблиц) ограничен множеством построенных форм. Так работают многие современные коммерческие приложения, работающие с базами данных - пользователю информация в системе доступна в виде нескольких типовых "срезов" информационного пространства. К недостатку систем, основанных на таком подходе, как и в предыдущем, также следует отнести необходимость наличия у пользователя опыта работы с подобными системами, а также необходимость создания форм, что требует дополнительных усилий программиста для создания интерфейса.
Преимущества ЕЯ-интерфейсов
Преимущества ЕЯ-интерфейсов достаточно очевидны:
· Минимальная предварительная подготовка пользователя. Естественный язык является наиболее привычным и удобным средством коммуникации, и именно в силу этого с ростом эффективности ЕЯ-систем, он, безусловно, будет вытеснять другие виды интерфейсов к СИД, традиционные в данный момент.
· Простота задания запросов на ЕЯ. Во многих случаях запрос на ЕЯ получается гораздо короче языка на формальном языке, поскольку ЕЯ-представление более емко, ведь в самой структуре языка содержится понятийная база, которую отражает структура источника данных. Зачастую сложность этой структуры отражается на сложности запроса на формальном языке.
· Большая скорость создания произвольного запроса (отсутствует стадия формального задания запроса). Как правило, пользователь сразу может сформулировать корректное ЕЯ-представление запроса, поскольку такое представление является самым естественным для человека, тогда как построение запроса на формальном языке, даже с помощью вспомогательных средств, таит множество ошибок, зачастую исправить которые можно, только проанализировав результат запроса.
· Более высокий уровень модели предметной области. Традиционные интерфейсы обычно не обладают моделью предметной области как таковой, и в лучшем случае скрывают от пользователя искусственные средства и особенности структуры, присущие конкретному типу СИД (такие, как связи по идентификаторам между таблицами в реляционных базах данных или синтаксис XML).
Более подробно рассмотрим недостатки ЕИЯ по сравнению с другими типами интерфейсов.
Недостатки:
· Неоднозначность естественного языка приводит к множественности смыслов. Специфика естественного языка такова, что часто запрос может иметь несколько смыслов, о которых пользователь в момент задания запроса не предполагает. Формальные же языки лишены проблемы неоднозначности. Это свойство ЕЯ приводит к усложнению ЕЯ-интерфейсов и методов анализа, в противном случае ЕЯ-интерфейс получается слишком примитивным для реального использования.
· Недостаточная надежность анализаторов ЕЯ-запросов может привести к неправильному пониманию. Современные ЕЯ-интерфейсы далеко не всегда позволяют диагностировать причины неудач понимания. Причины этих неудач могут быть как в лингвистической сфере, так и в концептуальной. Например, запрос к кадровой базе данных "Кто получает больше Иванова" может привести к непониманию, если ЕЯ-интерфейс не умеет распознавать вложенные запросы (а в данном случае надо сначала получить значение зарплаты Иванова, а затем сравнить с ней зарплату сотрудников). Это случай лингвистической проблемы. Второй пример - "Как зовут жен сотрудников?" может привести к неудаче понимания, если ЕЯ-интерфейс не поймет, что имя супруга/супруги - это реальный атрибут сотрудника, но отсутствующий в данной базе данных. В данном случае налицо будет концептуальная проблема - ЕЯ-интерфейс должен уметь отличать реальную предметную область, которую имеет в виду пользователь, задавая ЕЯ-запрос, от той ее части или трансформации, которая представлена в данном источнике данных.
· Пользователь может иметь завышенные или заниженные ожидания от ЕЯ-интерфейса. Сравнительный анализ типов пользовательских интерфейсов (основанных на формах, с формальным языком запросов, графические) показывает, что в целях построения ЕЯ-интерфейсов превалирует желание максимально приблизить интерфейс к потребностям неподготовленного пользователя. Это несколько поднимает планку требований к дружественности и надежности ЕЯ-интерфейсов, поскольку пользователь, впервые столкнувшись с системой, понимающей естественный язык, слабо представляет, насколько интеллектуальна система. При этом ожидания к степени понимания ЕЯ может отличаться от реальных способностей системы в обе стороны - т. е. пользователь может спрашивать систему о том, чего она "не знает", а может "по привычке" использовать простейшие шаблонные формулировки запросов. В других же типах интерфейсов к СИД рамки того, что пользователь может делать с помощью интерфейса, видны, как правило, сразу.
Поскольку характеристики ЕЯ-интерфейсов и систем для их построения могут существенно различаться, то преимущества и недостатки ЕЯ-интерфейсов по сравнению с другими типами интерфейсов к СИД можно выделить довольно схематично, только на качественном уровне. Для сравнения подходов к построению ЕЯ-интерфейсов введем метрику показателей, характеризующих качество ЕЯ-интерфейсов к структурированным источникам данных.
o Критерии качества ЕЯ-интерфейсов
Для сравнительного анализа подходов к созданию ЕЯ-интерфейсов рассмотрим такую качественную интегральную характеристику, как надежность. Под надежностью здесь понимается способность ЕЯ-интерфейса правильно понимать намерения пользователя по получению информации из источника, при условии, что пользователь корректно выразил потребности в виде ЕЯ-запроса. Надежность отражает правильность принципов, лежащих в методе ЕЯ-анализа, а также правильность (корректность) построения ЕЯ-интерфейса к конкретному СИД.
Любой ЕЯ-интерфейс имеет некоторое пространство правильно понимаемых запросов. Чем больше это пространство, тем большей полнотой обладает ЕЯ-интерфейс. Полнота - характеристика, тесно связанная с гибкостью интерфейса. Поскольку пространство ЕЯ-запросов весьма неоднородно, следует говорить о различных типах запросов, т. е. групп запросов, имеющих сходное строение. Гибкость - показатель того, насколько разнообразные типы запросов может понимать ЕЯ-интерфейс. Речь в основном идет о так называемых "трудных" типах запросов, в числе которых - вложенные, эллипсис, анафорические.
Другой важной характеристикой является дружественность интерфейса, которую можно определить как меру того, насколько ЕЯ-интерфейс удобен в работе, насколько корректно он может сообщать о проблемах понимания, может ли он помогать в переформулировке неберущихся запросов и т. д.
Все эти критерии можно объединить в схему, отражающую составляющие качества ЕЯИ (Рис. 1).
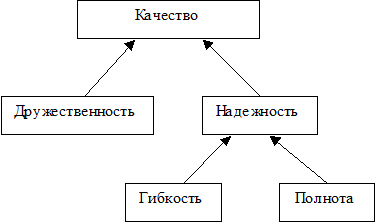
Рис. 1. Иерархия качественных характеристик ЕЯ-интерфейса
o Критерии стоимости построения и сопровождения ЕЯ-интерфейса
Вышеперечисленные характеристики входят в оценки качества ЕЯ-интерфейса. Важным критерием при сравнении ЕЯ-интерфейсов является также трудоемкость его создания, то есть необходимое количество усилий (времени), требуемых для его построения. Ранние ЕЯ-интерфейсы создавались для каждой базы данных отдельно, и, разумеется, их стоимость была очень большой. Все эти системы были экспериментальными. Усугубляло проблему также то, что до конца 70-х годов не было единого универсального формального языка запросов к базам данных. Ранние системы понимания ЕЯ-запросов к СУБД были непортируемыми на другие базы данных, и зачастую лингвистическое ядро не отделялось от предметно-ориентированных настроек.
Современные промышленные системы построения ЕЯ-интерфейсов обладают достаточно высокой степенью портируемости, что, безусловно, снижает стоимость построения ЕЯ-интерфейса. Лингвистическое ядро является универсальным элементом, словарь содержит универсальную лексику, используемую во многих ЕЯ-интерфейсах, модели предметной области могут содержать шаблоны, общие для нескольких предметных областей и т. д. Зачастую используется метафора "фабрики и изделия", изделием выступает ЕЯ-интерфейс, который собирается из готовых компонентов, которые настраиваются под конкретную базу данных.
Следует отметить, однако, что вопрос портирования на другие языки является открытым. Подавляющее большинство исследований проведено для английского языка, некоторые особенности которого изначально заложили в пути исследований мину замедленного действия - первоначально огромное количество усилий были потрачены на анализ синтаксиса. Сейчас можно сказать, что эти усилия не оправдали себя.
На трудоемкость создания ЕЯИ влияет также необходимая квалификация настройщика ЕЯ-интерфейса. Для систем, требующих навыков лингвиста, трудоемкость построения ЕЯИ больше, чем для систем, где для построения интерфейса требуется просто описать предметную область по некоторым предопределенным шаблонам и отобразить ее на схему базы данных, и дело здесь не только в стоимости труда лингвиста и инженера знаний или специалиста в области баз данных. Системы, требующие подстроек на уровне лингвистического ядра, являются более гибкими, поскольку позволяют разрешать проблемы понимания ЕЯ-запросов написанием соответствующих "заплаток", однако работы по написанию таких "заплаток" являются настолько сложными, требуют такого уровня понимания принципов машинного анализа ЕЯ в целом, что настройка ЕЯИ на уровне лингвистического процессора зачастую возможна только авторами системы построения ЕЯИ. Впрочем, сложность подстройки ядра очень сильно зависит от принципов анализа, используемого при написании инструментария, открытости ядра и т. д.
o Основные составные части ЕЯ-интерфейсов к СИД
Кратко рассмотрим основные части ЕЯ-интерфейсов и их взаимосвязи. Прежде всего следует выделить из интерфейса анализатор ЕЯ как компонент, реализующий тот или иной метод анализа естественного языка, и от принципов построения которого зависит архитектура системы и основные характеристики интерфейсов на основе данного компонента.
Работа анализатора заключается в построении внутреннего представления входного ЕЯ-текста либо запроса, обычно в виде некоторой структуры, например, синтаксического дерева, семантической сети, фреймовой структуры и т. д. Предшествующим этапом для процесса анализа является лексический анализ (пред-анализ), который преобразует входной текст как последовательность символов, в цепочку лексем, поступающей на вход анализатора.
Необходимым компонентом работы анализатора является словарь, который содержит слова и фразы, обычно с привязкой к ним определенной информации, связанной с семантикой, морфологией и т. д., в зависимости от подхода анализа ЕЯ. Еще одним важным компонентом многих систем является модель предметной области, структура которой варьируется в очень больших пределах от системы к системе.
Для построения запроса на формальном языке источника данных используется модель источника данных, отражающая основную структуру СИД, ее части, существенные для данного ЕЯИ.
Для перевода запроса из внутреннего представления системы в формальный язык источника данных предназначен процесс генерации формального запроса. Некоторые системы имеют также модуль синтеза ЕЯ, который может применяться для генерации естественно-языкового представления запроса, например, для верификации понимания запроса системой, а также для генерации уточняющих вопросов.
Модель предметной области в некоторых системах (см. там же) дополняется базой знаний со средствами вывода новых знаний.
На рис. 2 приведены основные составляющие ЕЯИ и взаимосвязи между ними, представленные потоками данных.
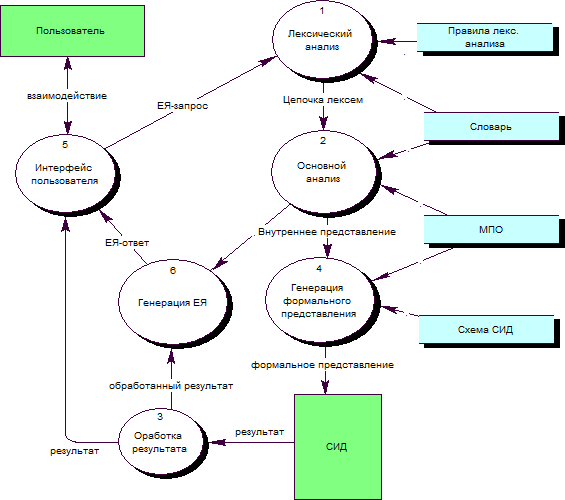
Рис. 2 Основные составляющие ЕЯ-интерфейсов и их взаимосвязи
o Проблемы общения с ЭВМ на ЕЯ, связанные с особенностями естественного языка.
Под технологией анализа ЕЯ подразумевается перевод некоторого выражения на ЕЯ во внутреннее представление. Фактически все системы анализа ЕЯ могут быть распределены на следующие категории: подбор шаблона (Pattern Matching), синтаксический анализ, семантические грамматики, анализ с помощью падежных фреймов, “жди и смотри” (Wait And See), словарный экспертный (Word Expert), коннекционистский, “скользящий” (Skimming) анализ.
Проблемы понимания естественного языка, будь то текст или речь, во многом зависят от знания предметной области. Понимание языка требует знаний о целях говорящего и о контексте. Необходимо также учитывать недосказанность или иносказательность. Например, даже в таком простом предложении «Ваня встретил Машу на поляне с цветами» нам не понятно, кто же был с цветами: Ваня, Маша или поляна? Еще один пример «Врач бегло говорила по-английски». Разбирая это предложение, необходимо в результате разбора зафиксировать, что врач была женщина. Основные проблемы понимания естественного языка:
Проблема СМЫСЛ-ТЕКСТ. В предложении «Какой завод заказал оборудование для конвертерного цеха в Бельгии?» неясен смысл: был ли сделан заказ в Бельгии или цех находится в Бельгии. Проблема планирования возникает при необходимости вести диалог, например, на тему «Куда Вы хотите лететь?». В этом случае нужно глубокое знание предметной области (номера рейсов, время прилета-отлета, цены и т. д.). Проблема равнозначности. Будут ли равнозначны два предложения «У дома стоит слон» и «У дома стоит существо с хоботом и бивнями»? На первый взгляд нет сомнений в равнозначности этих предложений. А если в базе знаний существо с хоботом и бивнями определено двумя значениями: слон и мамонт, то такие сомнения, наверное, появятся. Проблемы моделей участников общения. У участников общения должны быть сопоставимые модели представления знаний, необходимая глубина понимания, возможность логического вывода, возможность действия. Проблема эллиптических конструкций, то есть опущенных элементов диалога. Например, в пословице «Береги платье снову, а честь - смолоду» вторая часть предложения будет синтаксическим эллипсисом (опущен глагол береги). Проблема временных противоречий. Например, в предложении «Я хотел завтра пойти в кино» глагол «хотел» в прошедшей форме сочетается с обстоятельством будущего времени «завтра», что противоречит общепринятой логике.Прикладные системы NLP имеют преимущество перед общими, т. к. работают в узких предметных областях. Тем не менее, создание систем, имеющих возможность общения на ЕЯ в широких областях, возможно, хотя пока результаты далеки от удовлетворительных.
Под технологией анализа ЕЯ подразумевается перевод некоторого выражения на ЕЯ во внутреннее представление. Фактически все системы анализа ЕЯ могут быть распределены на следующие категории: подбор шаблона (Pattern Matching), синтаксический анализ, семантические грамматики, анализ с помощью падежных фреймов, “жди и смотри” (Wait And See), словарный экспертный (Word Expert), коннекционистский, “скользящий” (Skimming) анализ.
Синтаксический анализ. При использовании синтаксического анализа происходит интерпретация отдельных частей высказывания, а не всего высказывания в целом. Обычно сначала производится полный синтаксический анализ, а затем строится внутренне представление введенного текста, либо производится интерпретация.
Деревья анализа и свободно-контекстные грамматики. Большинство способов синтаксического анализа реализовано в виде деревьев. Одна из простейших разновидностей - свободно-контекстная грамматика, состоящая из правил типа S=NP+VP или VP=V+NP и полагающая, что левая часть правила может быть заменена на правую без учета контекста. Свободно-контекстная грамматика широко используется в машинных языках, и с ее помощью созданы высокоэффективные методы анализа. Недостаток этого метода - отсутствие запрета на грамматически неправильные фразы, где, например, подлежащее не согласовано со сказуемым в числе. Для решения этой проблемы необходимо наличие двух отдельных, параллельно работающих грамматик: одной - для единственного, другой - для множественного числа. Кроме того, необходима своя грамматика для пассивных предложений и т. д. Семантически неправильное предложение может породить огромное количество вариантов разбора, из которых один будет превращен в семантическую запись. Всё это делает количество правил огромным и, в свою очередь, свободно-контекстные грамматики непригодными для NLP.
Трансформационная грамматика. Трансформационная грамматика была создана с учетом упомянутых выше недостатков и более рационального использования правил ЕЯ, но оказалась непригодной для NLP. Трансформационная грамматика создавалась Хомским как порождающая, что, следовательно, делало очень затруднительным обратное действие, т. е. анализ.
Расширенная сеть переходов. Расширенная сеть переходов была разработана Бобровым (Bobrow), Фрейзером (Fraser) и во многом Вудсом (Woods) как продолжение идей синтаксического анализа и свободно-контекстных грамматик в частности. Она представляет собой узлы и направленные стрелки, “расширенные” (т. е. дополненные) рядом тестов (правил), на основании которых выбирается путь для дальнейшего анализа. Промежуточные результаты записываются в ячейки (регистры). Ниже приводится пример такой сети, позволяющей анализировать простые предложения всех типов (включая пассив), состоящие из подлежащего, сказуемого и прямого дополнения, таких, как The rabbit nibbles the carrot (Кролик грызет морковь). Обозначения у стрелок означают номер теста, а также либо признаки, аналогичные применяемым в свободно-контекстных грамматиках (NP), либо конкретные слова (by). Тесты написаны на языке LISP и представляют собой правила типа если условие=истина, то присвоить анализируемому слову признак Х и записать его в соответствующую ячейку.
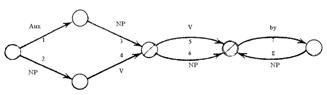
Разберем алгоритм работы сети на вышеприведенном примере. Анализ начинается слева, т. е. с первого слова в предложении. Словосочетание the rabbit проходит тест, который выясняет, что оно не является вспомогательным глаголом (Aux, стрелка 1), но является именной группой (NP, стрелка 2). Поэтому the rabbit кладется в ячейку Subj, и предложение получает признак TypeDeclarative, т. е. повествовательное, и система переходит ко второму узлу. Здесь дополнительный тест не требуется, поскольку он отсутствует в списке тестов, записанных на LISP. Следовательно, слово, стоящее после the rabbit - т. е. nibbles - глагол-сказуемое (обозначение V на стрелке), и nibbles записывается в ячейку с именем V. Перечеркнутый узел означает, что в нем анализ предложения может в принципе закончиться. Но в нашем примере имеется еще и дополнение the carrot, так что анализ продолжается по стрелке 6 (выбор между стрелками 5 и 6 осуществляется снова с помощью специального теста), и словосочетание the carrot кладется в ячейку с именем Obj. На этом анализ заканчивается (последний узел был бы использован в случае анализа такого пассивного предложения, как The carrot was nibbled by the rabbit). Таким образом, в результате заполнены регистры (ячейки) Subj, Type, V и Obj, используя которые, можно получить какое-либо представление (например, дерево).
Расширенная сеть переходов имеет свои недостатки:
немодульность;
сложность при модификации, вызывающая непредвиденные побочные эффекты;
хрупкость (когда единственная неграмматичность в предложении делает невозможным дальнейший правильный анализ);
неэффективность при переборе с возвратами, т. к. ошибки на промежуточных стадиях анализа не сохраняются;
неэффективность с точки зрения смысла, когда с помощью полученного синтаксического представления оказывается невозможным создать правильное семантическое представление.
o Семантически-ориентированный анализ ЕЯ, ориентированный на распознавание смысла предложения.
Системы, в которых используется естественный язык (ЕЯ) можно разделить на классы, как показано на рисунке.
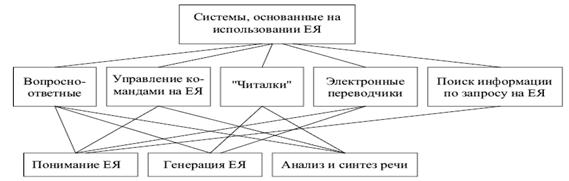
Существуют два основных подхода к реализации систем, моделирующих понимание естественного языка (ЕЯ) – синтаксически - и семантически-ориентированный.
В синтаксически-ориентированном подходе строго выдерживается следующая последовательность этапов анализа:
Морфологический анализ – анализ структуры слов, т. е. распознавание корня и аффиксов (приставок, суффиксов, окончаний), с использованием словарей корней и аффиксов; Синтаксический анализ – анализ структуры предложения, т. е. частей предложения (или ролей слов в нем) с использованием грамматики языка; Семантический анализ – анализ смысла предложения, т. е. интерпретация его в терминах представления смысла, с использованием базы знаний о предметной области знаний о синтаксисе представления смысла; Прагматический анализ – анализ целей предложения или ожиданий и желаний его источника с целью планирования реакции на анализируемое предложение.В семантически-ориентированном анализе главным и первым этапом анализа является анализ семантики (смысла), иногда, предварительный, т. к. далее смысл может уточняться с использованием уже синтаксического и морфологического анализа. В этом случае можно говорить не об анализе, а о распознавании смысла предложения.
Анализ ЕЯ, основанный на использовании семантических грамматик, очень похож на синтаксический, с той разницей, что вместо синтаксических категорий используются семантические.
Естественно, семантические грамматики работают в узких предметных областях. Примером Примером служит система Ladder, встроенная в базу данных американских судов. Ее грамматика содержит записи типа: S -> <present> the <attribute> of <ship> <present> -> what is|[can you] tell me <ship> -> the <shipname>|<classname> class ship.
Такая грамматика позволяет анализировать такие запросы, как Can you tell me the class of the Enterprise? (Enterprise – название корабля). В данной системе анализатор составляет на основе запроса пользователя запрос на языке базы данных.
Недостатки семантических грамматик состоят в том, что, во-первых, необходима разработка отдельной грамматики для каждой предметной области, а во-вторых, они очень быстро увеличиваются в размерах. Способы исправления этих недостатков – использование синтаксического анализа перед семантическим, применение семантических грамматик только в рамках реляционных баз данных с абстрагированием от общеязыковых проблем и комбинация нескольких методов (включая собственно семантическую грамматику).
o Распознавание смысла предложений ЕЯ.
Под технологией анализа ЕЯ подразумевается перевод некоторого выражения на ЕЯ во внутреннее представление. Фактически все системы анализа ЕЯ могут быть распределены на следующие категории: подбор шаблона (Pattern Matching), синтаксический анализ, семантические грамматики, анализ с помощью падежных фреймов, "жди и смотри" (Wait And See), словарный экспертный (Word Expert), коннекционистский, "скользящий" (Skimming) анализ.
Распознавание смысла ЕЯ с помощью шаблонов.
Подбор шаблона. Сущность данного подхода состоит в интерпретации ввода в целом, а не в интерпретации смысла и структуры его отдельных составляющих на более низком уровне. При использовании этого метода происходит сравнение уже имеющихся в системе шаблонов-образцов с текстом, поступившим на вход. Обычно шаблоны представлены в виде простого списка соответствий между классами высказываний и интерпретациями. Иногда они дополнены семантическими элементами или другими компонентами более высокого уровня. Построенная таким образом, система ничего не понимает, а лишь поддерживает диалог, сравнивая реплики пациента с шаблонами и присвоенными
им соответствующими ответными репликами, такими, как:
X всегда Y: Вы можете привести какой-нибудь пример?
Когда?
Действительно, всегда?
X Вы Y меня: Почему Вы думаете, что я Y Вас?
Вам нравится думать, что я Y Вас, не правда ли?
Представьте, что я Y Вас. Что Вы об этом думаете?
В результате система способна вести такой диалог:
Человек Люди всегда пристально смотрят на меня.
подбор по 1-му шаблону с учетом всегда
Система Вы можете привести какой-нибудь пример?
первый ответ по 1-му шаблону
Человек Например, сейчас ты смотришь на меня.
подбор по 2-му шаблону, Y=смотреть
Система Почему Вы думаете, что я смотрю на Вас?
первый ответ по 2-му шаблону
Человек Потому что ты ненавидишь меня.
подбор по 2-му шаблону, Y=ненавидеть
Система Вам нравится думать, что я ненавижу Вас, не правда ли? и т. д.
второй ответ по 2-му шаблону
Распознавание смысла ЕЯ с помощью падежных фреймов.
Под технологией анализа ЕЯ подразумевается перевод некоторого выражения на ЕЯ во внутреннее представление. Фактически все системы анализа ЕЯ могут быть распределены на следующие категории: подбор шаблона (Pattern Matching), синтаксический анализ, семантические грамматики, анализ с помощью падежных фреймов, "жди и смотри" (Wait And See), словарный экспертный (Word Expert), коннекционистский, "скользящий" (Skimming) анализ.
В основе теории фреймов лежит восприятие фактов посредством сопоставления полученной извне информации с конкретными элементами и значениями, а также, с рамками, определенными для каждого концептуального объекта в памяти. Структура, представляющая эти рамки, называется фреймом.
В виде фрейма может описываться некоторый объект, ситуация, абстрактной понятие, формула, закон, правило, визуальная сцена и т. п.
Падежные фреймы - один из наиболее часто используемых методов NLP, т. к. он является наиболее компьютерно-эффективным при анализе как снизу вверх (от составляющих к целому), так и сверху вниз (от целого к составляющим).
Падежный фрейм состоит из заголовка и набора ролей (падежей), связанных определенным образом с заголовком. Фрейм для компьютерного анализа отличается от обычного фрейма тем, что отношения между заголовком и ролями определяется семантически, а не синтаксически, т. к. в принципе одному и то же слово может приписываться разные роли, например, существительное может быть как инструментом действия, так и его объектом.
Общая структура фрейма такова:
[Заголовочный глагол
[падежный фрейм
агент: <активный агент, совершающий действие>
объект: <объект, над которым совершается действие>
инструмент: <инструмент, используемый при совершении действия>
реципиент: <получатель действия - часто косвенное дополнение>
направление: <цель (обычно физического) действия>
место: <место, где совершается действие>
бенефициант: <сущность, в интересах которой совершается действие>
коагент: <второй агент, помогающий совершать действие>]]
Например, для фразы Иван дал мяч Кате падежный фрейм выглядит так:
[Давать
[падежный фрейм
агент: Иван
объект: мяч
реципиент: Катя]
[грам время: прош залог: акт]]
Анализ текста с помощью падежных фреймов состоит из следующих шагов:
- Используя существующие фреймы, подобрать подходящий для заголовка. Если такого нет, текст не может быть проанализирован. Вернуть в систему подходящий фрейм с соответствующим заголовком-глаголом. Попытаться провести анализ по всем обязательным падежам. Если один или более обязательных заполнителей падежей не найдены, вернуть в систему код ошибки. Такой случай может означать наличие эллипсиса, неверный выбор фрейма, неверно введенный текст или недостаток грамматики. Следующие шаги используются уже для анализа и исправления таких ситуаций. Провести анализ по всем необязательным падежам. Если после этого во введенном тексте остались непроанализированные элементы, выдать сообщение об ошибке, связанной с неправильным вводом, недостаточностью данного анализа или необходимостью провести другой, более гибкий анализ.
Преимущества использования падежных фреймов таковы:
· совмещение двух стратегий анализа (сверху вниз и снизу вверх);
· комбинирование синтаксиса и семантики;
· удобство при использовании модульных программ.
