

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2. Анализ точности вычислительных процессов.
2.2.1. Общая формула для оценки главной части погрешности.
При численном решении математических и прикладных задач почти неизбежно появление на том или ином этапе их решения погрешностей следующих трех типов.
а) Погрешность задачи. Она связана с приближенным характером исходной содержательной модели (в частности, с невозможностью учесть все факторы в процессе изучения моделируемого явления), а также ее математического описания, параметрами которого служат обычно приближенные числа (например, из-за принципиальной невозможности выполнения абсолютно точных измерений). Для вычислителя погрешность задачи следует считать неустранимой (безусловной), хотя постановщик задачи иногда может ее изменить.
б) Погрешность метода. Это погрешность, связанная со способом решения поставленной математической задачи и появляющаяся в результате подмены исходной математической модели другой или конечной последовательностью других, например, линейных моделей. При создании численных методов закладывается возможность отслеживания таких погрешностей и доведения их до сколь угодно малого уровня. Отсюда естественно отношение к погрешности метода как к устранимой (или условной).
в) Погрешность округлений (погрешность действий). Этот тип погрешностей обусловлен необходимостью выполнять арифметические операции над числами, усеченными до количества разрядов, зависящего от применяемой вычислительной техники (если, разумеется, не используются специальные программные средства, реализующие, например, арифметику рациональных чисел).
Все три описанных типа погрешностей в сумме дают полную погрешность результата решения задачи. Поскольку первый тип погрешностей не находится в пределах компетенции вычислителя, для него он служит лишь ориентиром точности, с которой следует рассчитывать математическую модель. Нет смысла решать задачу существенно точнее, чем это диктуется неопределенностью исходных данных. Таким образом, погрешность метода подчиняют погрешности задачи. Наконец, при выводе оценок погрешностей численных методов обычно исходят из предположения, что все операции над числами выполняются точно. Это означает, что погрешность округлений не должна существенно отражаться на результатах реализации методов, т. е. должна подчиняться погрешности метода. Влияние погрешностей округлений не следует упускать из виду ни на стадии отбора и алгоритмизации численных методов, ни при выборе вычислительных и программных средств, ни при выполнении отдельных действий и вычислении значений функций.
Пусть А и а - два "близких" числа; условимся считать А точным, а — приближенным.
Величина ![]() называется абсолютной погрешностью приближенного числа а, а
называется абсолютной погрешностью приближенного числа а, а 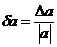 его относительной погрешностью.
его относительной погрешностью.
Числа Δa и δа такие, что Δa > Δа и δа = ![]() a, называются оценками или границами абсолютной и относительной погрешностей соответственно (к Δa и δа часто применяют также термин "предельные погрешности"). Так как обычно истинные погрешности не известны, то там, где не может возникнуть недоразумений, будем иногда называть Δa и δа просто абсолютной и относительной погрешностями.
a, называются оценками или границами абсолютной и относительной погрешностей соответственно (к Δa и δа часто применяют также термин "предельные погрешности"). Так как обычно истинные погрешности не известны, то там, где не может возникнуть недоразумений, будем иногда называть Δa и δа просто абсолютной и относительной погрешностями.
Поставим вопрос о грубом оценивании погрешности результата вычисления значения дифференцируемой функции ![]() приближенных аргументов
приближенных аргументов ![]() , если известны границы их абсолютных погрешностей
, если известны границы их абсолютных погрешностей ![]() соответственно. В этом случае точные значения аргументов
соответственно. В этом случае точные значения аргументов 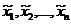 лежат соответственно на отрезках
лежат соответственно на отрезках
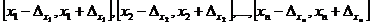 , а точная абсолютная погрешность результата
, а точная абсолютная погрешность результата ![]() есть
есть
![]()
- модуль полного приращения функции. Главной, т. е. линейной частью этого приращения является, как известно, полный дифференциал du . Таким образом, имеем:
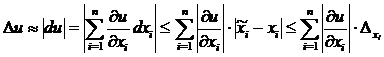 , (2.1)
, (2.1)
т. е. за границу абсолютной погрешности результата приближенно может быть принята величина
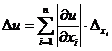 (2.2)
(2.2)
Отсюда легко получается формула приближенной оценки относительной погрешности значения u:
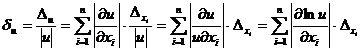 (2.3)
(2.3)
Как частные случаи формул (2.2), (2.3) (точных для функций, линейных относительно xi, или lnxi соответственно) можно получить известные правила оценивания погрешностей результатов арифметических действий [1].
Действительно, пусть 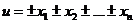 . Тогда
. Тогда 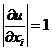 и
и 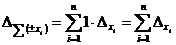 , т. е. при сложении и вычитании приближённых чисел их предельные погрешности складываются.
, т. е. при сложении и вычитании приближённых чисел их предельные погрешности складываются.
Пусть теперь 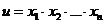 , где можно считать все сомножители положительными. Так как
, где можно считать все сомножители положительными. Так как ![]() и
и ![]() , то, согласно (2.3),
, то, согласно (2.3),
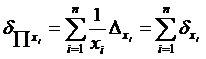 . (2.4)
. (2.4)
Если же 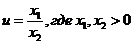 , то
, то 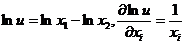 и, значит
и, значит
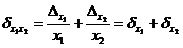 . (2.5)
. (2.5)
Последнее вместе с (2.4) означает известный результат о сложении предельных относительных погрешностей при умножении и делении приближенных чисел.
Возвращаясь к сложению, рассмотрим относительную погрешность суммы n положительных приближенных чисел 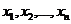 , имеющих границы относительных погрешностей
, имеющих границы относительных погрешностей ![]() соответственно:
соответственно:
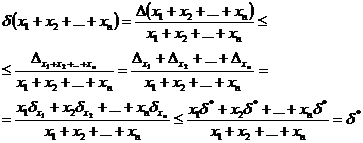 ,
,
где 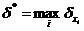 . Полученное неравенство говорит о том, что относительная погрешность суммы n положительных приближённых чисел не превосходит максимальной относительной погрешности слагаемых.
. Полученное неравенство говорит о том, что относительная погрешность суммы n положительных приближённых чисел не превосходит максимальной относительной погрешности слагаемых.
С вычитанием приближённых чисел дело обстоит хуже: оценка
![]()
относительной погрешности разности x1 - х2 двух приближенных положительных чисел указывает на возможность сильного возрастания погрешности при x1 - х2 → 0. В этом случае говорят о потере точности при вычитании близких чисел.
2.2.2. Статистический и технический подходы к учёту погрешности действий.
Рассмотренный выше аналитический (или классический) способ учета погрешностей действий, предполагающий точное оценивание погрешностей, основанное либо на приведенных в предыдущем параграфе правилах подсчета погрешностей арифметических действий, либо на параллельной работе с верхними и нижними границами исходных данных, имеет два существенных недостатка. Во-первых, этот способ чрезвычайно громоздок и не может быть рекомендован при массовых вычислениях. Во-вторых, он учитывает крайние, наихудшие случаи взаимодействия погрешностей, которые допустимы, но маловероятны. Ясно, что, например, при суммировании нескольких приближенных чисел (полученных в результате измерений, округлений или каким-либо другим путем) среди них почти наверное будут слагаемые как с избытком, так и с недостатком, т. е. произойдёт частичная компенсация погрешностей. При больших количествах однотипных вычислений вступают в силу уже вероятностные или статистические законы формирования погрешностей результатов действий. Например, методами теории вероятностей показывается, что математическое ожидание абсолютной погрешности суммы n слагаемых с одинаковым уровнем абсолютных погрешностей, при достаточно большом n, пропорционально √n. В частности, если n>10 и все слагаемые округлены до m-го десятичного разряда, то для подсчета абсолютной погрешности суммы 5 применяют правило Чеботарева .
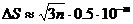 (2.6)
(2.6)
Различие в результатах классического и статистического подходов к оцениванию погрешности суммы рассмотрим на примере оценки погрешности среднего арифметического нескольких приближенных чисел.
Пусть ![]() - среднее арифметическое n (>10) приближенных чисел (например, результатов измерений), имеющих одинаковый уровень абсолютных погрешностей
- среднее арифметическое n (>10) приближенных чисел (например, результатов измерений), имеющих одинаковый уровень абсолютных погрешностей ![]() . Тогда классическая оценка абсолютной погрешности величины х есть
. Тогда классическая оценка абсолютной погрешности величины х есть
![]() ,
,
т. е. такая же, как и у исходных данных. В тоже время по формуле (2.6) имеем
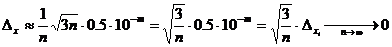 .
.
Как видим, применение правила Чеботарева приводит к естественному выводу о том, что арифметическое усреднение результатов измерений или наблюдений увеличивает точность, чего нельзя сказать на основе классической теории погрешностей.
2.2.3. Графы вычислительных процессов.
Рассмотрим более удобный способ подсчёта распространения ошибки в каком-либо арифметическом вычислении.
С этой целью мы будем, изображать последовательность операций в вычислении с помощью так называемого графа и будем писать около стрелок графа коэффициенты, которые позволят нам сравнительно легко определить общую ошибку окончательного результата. Метод этот удобен еще и тем, что позволяет легко определить вклад любой ошибки, возникшей в процессе вычислений, в общую ошибку.
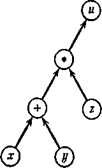
На рис. 2.1 изображен граф вычислительного процесса u = (х + у)*z. Граф следует читать снизу вверх, следуя стрелкам. Сначала выполняются операции, расположенные на каком-либо горизонтальном уровне, после этого — операции, расположенные на более высоком уровне, и т. д. Из рис. 2.1, например, ясно, что x и у сначала складываются, а потом умножаются на z. Граф, изображенный на рис. 2.1, является только изображением самого вычислительного процесса. Для подсчета общей ошибки результата необходимо дополнить этот граф коэффициентами, которые пишутся около стрелок согласно следующим правилам.
Рис. 2.1. Граф вычислительного процесса u = (х + у)*z.
 Сложение
Сложение
Пусть две стрелки, которые входят в кружок сложения, выходят из двух кружков с величинами a1 и а2. Эти величины могут быть как исходными, так и результатами предыдущих вычислений. Тогда стрелка, ведущая от a1 к знаку + в кружке, получает коэффициент a1/(a1 + a2) стрелка же, ведущая от a2 к знаку + в кружке, получает коэффициент a2/(a1 + a2).
Вычитание
Если выполняется операция al — a2, то соответствующие стрелки получают коэффициенты a1/(a1 - a2) a1/(a1 - a2).
Умножение
Обе стрелки, входящие в кружок умножения, получают коэффициент +1.
Деление
Если выполняется деление a1/a2, то стрелка от a1 к косой черте в кружке получает коэффициент +1, а стрелка от a2 к косой черте в кружке получает коэффициент -1.
Смысл всех этих коэффициентов следующий: относительная ошибка результата любой операции (кружка) входит в результат следующей операции, умножаясь на коэффициент у стрелки, соединяющей эти две операции.
В качестве примера можно рассмотреть рис. 2.2, который отличается от 2.1 только тем, что около стрелок расставлены соответствующие коэффициенты.
Предположим, что три исходные величины на рис. 2.1 имеют относительные ошибки округления, равные соответственно ix, iy и iz, и посмотрим, как применяется правило подсчета ошибки. Сначала рассмотрим сложение. Относительная ошибка величины х составляет ix; эта ошибка войдет в результат следующей операции (сложения) умноженной на коэффициент у стрелки, соединяющей х в кружке со знаком + в кружке: ![]()
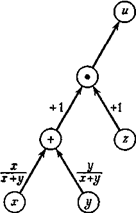
Рис. 2.2. Граф вычислительного процесса
В последнем выражении были опущены черточки над х и у; тем не менее подразумевается, что эти величины являются приближенными. Аналогично, относительная ошибка у, равная iy, войдет в результат операции сложения умноженной на коэффициент при стрелке, соединяющей у в кружке со знаком + в кружке.
Наконец, при выполнении операции сложения появляется ошибка округления, которую мы обозначим через r1. Таким образом, полная относительная ошибка результата сложения равна следующей сумме:
![]() .
.
Теперь можно применить то же правило к умножению. Один из сомножителей есть сумма х и у, ошибку которой мы только что вычислили; эта ошибка, согласно изложенным выше правилам, войдет в результат умножения умноженной на +1. Относительная ошибка сомножителя z, равная iz, также войдет в результат умножения умноженной на +1. При выполнении операции умножения появляется ошибка округления, равная r2. Полная ошибка результата операции умножения выразится следующим образом:
![]()
Если все результаты соответствующим образом округлены (имеется в виду симметричное округление), то ни одна из ошибок округления не превзойдет ![]() . Поэтому
. Поэтому
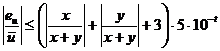
Если х и у оба неотрицательны, то сумма
![]()
не может быть больше 1, и окончательно мы имеем [6]
![]() (2.7)
(2.7)
