
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Как правило, сканеры действуют по следующему принципу: очередной символ из входного потока данных добавляется в лексему всегда, когда он может быть туда добавлен. Как только символ не может быть добавлен в лексему, то считается, что он является границей лексемы и началом следующей лексемы (если символ не является пустым разделителем — пробелом, символом табуляции или перевода строки, знаком комментария). Такой принцип не всегда позволяет правильно определить границы лексем в том случае, когда они не разделены пустыми символами. Например, приведенная выше строка языка С k=1+++++j; будет разбита на лексемы следующим образом: k = 1++ ++ + j; — и это разбиение неверное, компилятор должен будет выдать пользователю сообщение об ошибке, хотя правильный вариант распознавания строки существует.
Однако разработчики компиляторов сознательно идут на то, что отсекают некоторые правильные, но не вполне читаемые варианты исходных программ. Попытки усложнить лексический распознаватель неизбежно приведут к необходимости его взаимосвязи с синтаксическим разбором. Это потребует организации их параллельной работы и неизбежно снизит эффективность работы всего компилятора. Возникшие накладные расходы никак не оправдываются достигаемым эффектом — чтобы распознавать строки с сомнительными лексемами, достаточно лишь обязать пользователя явно указать с помощью пробелов (или других незначащих символов) границы лексем, что значительно проще.
Выполнение действий, связанных с лексемами
Выполнение действий в процессе распознавания лексем представляет для сканера гораздо меньшую проблему. Фактически КА, который лежит в основе распознавателя лексем, должен иметь не только входной язык, но и выходной. Он должен не только уметь распознать правильную лексему на входе, но и породить связанную с ней последовательность символов на выходе. В такой конфигурации КА преобразуется в конечный преобразователь [5, 6, т 1, 42].
Для сканера действия по обнаружению лексемы могут трактоваться несколько шире, чем только порождение цепочки символов выходного языка. Сканер должен уметь выполнять такие действия, как запись найденной лексемы в таблицу лексем, поиск ее в таблице символов и запись новой лексемы в таблицу символов. Набор действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же по обнаружению конца распознаваемой лексемы.
В КА сканера эти действия можно отобразить сравнительно просто — достаточно. иметь возможность с каждым переходом на графе автомата (или в функции переходов автомата) связать выполнение некоторой произвольной функции f(q, a), где q — текущее состояние автомата, а — текущий входной символ Функция может выполнять произвольные действия, доступные сканеру, в том числе работать с хранилищами данных, имеющимися в компиляторе (функция может быть и пустой — не выполнять никаких действий). Такую функцию, если она есть, обычно записывают на графе переходов КА под дугами, соединяющими состояния КА.
Лексический анализатор для М-языка
Вход лексического анализатора - символы исходной программы на М-языке; результат работы - исходная программа в виде последовательности лексем (их внутреннего представления).
Лексический анализатор для модельного языка будем писать в два этапа: сначала построим диаграмму состояний с действиями для распознавания и формирования внутреннего представления лексем, а затем по ней напишем программу анализатора.
Первый этап: разработка ДС.
Представление лексем: все лексемы М-языка разделим на несколько классов; классы перенумеруем:
à служебные слова - 1,
à ограничи,
à константы (целые числа) - 3,
à идентификаторы - 4.
Внутреннее представление лексем - это пара (номер_класса, номер_в_классе). Номер_в_классе - это номер строки в таблице лексем соответствующего класса.
Соглашение об используемых переменных, типах и функциях:
1) пусть есть переменные:
buf - буфер для накопления символов лексемы;
c - очередной входной символ;
d - переменная для формирования числового значения константы;
TW - таблица служебных слов М-языка;
TD - таблица ограничителей М-языка;
TID - таблица идентификаторов анализируемой программы;
TNUM - таблица чисел-констант, используемых в программе.
Таблицы TW и TD заполнены заранее, т. к. их содержимое не зависит от исходной программы; TID и TNUM будут формироваться в процессе анализа; для простоты будем считать, что все таблицы одного типа; пусть tabl - имя типа этих таблиц, ptabl - указатель на tabl.
2) пусть есть функции:
void clear (void); - очистка буфера buf;
void add (void); - добавление символа с в конец буфера buf;
int look (ptabl Т); - поиск в таблице Т лексемы из буфера buf; результат: номер строки таблицы с информацией о лексеме либо 0, если такой лексемы в таблице Т нет;
int putl (ptabl Т); - запись в таблицу Т лексемы из буфера buf, если ее там не было; результат: номер строки таблицы с информацией о лексеме;
int putnum (); - запись в TNUM константы из d, если ее там не было; результат: номер строки таблицы TNUM с информацией о константе-лексеме;
void makelex (int k, int i); - формирование и вывод внутреннего представления лексемы; k - номер класса, i - номер в классе;
void gc (void) - функция, читающая из входного потока очередной символ исходной программы и заносящая его в переменную с.
Тогда диаграмма состояний для лексического анализатора:
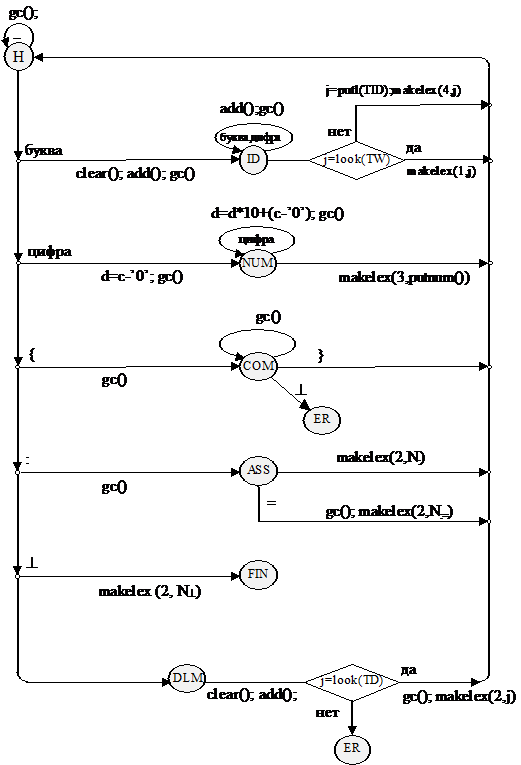
Замечание: символом Nx в диаграмме (и в тексте программы) обозначен номер лексемы x в ее классе.
Второй этап: по ДС пишем программу
#include <stdio. h>
#include <ctype. h>
#define BUFSIZE 80
typedef struct tabl * ptabl;
extern ptabl TW, TID, TD, TNUM;
char buf[BUFSIZE]; /* для накопления символов лексемы */
int c; /* очередной символ */
int d; /* для формирования числового значения
константы */
void clear(void); /* очистка буфера buf */
void add(void); /* добавление символа с в конец буфера
buf*/
int look(ptabl); /* поиск в таблице лексемы из buf;
результат: номер строки таблицы либо 0 */
int putl(ptabl); /* запись в таблицу лексемы из buf,
если ее там не было; результат:
номер строки таблицы */
int putnum(); /* запись в TNUM константы из d, если ее
там не было; результат: номер строки
таблицы TNUM */
int j; /* номер строки в таблице, где находится
лексема, найденная функцией look */
void makelex(int, int); /* формирование и вывод внутреннего
представления лексемы */
void scan (void)
{enum state {H, ID, NUM, COM, ASS, DLM, ER, FIN};
state TC; /* текущее состояние */
FILE* fp;
TC = H;
fp = fopen("prog","r"); /* в файле "prog" находится
текст исходной программы */
c = fgetc(fp);
do {switch (TC) {
case H:
if (c == ' ') c = fgetc(fp);
else if (isalpha(c))
{clear(); add(); c = fgetc(fp); TC = ID;}
else if (isdigit (c))
{d = c - '0'; c = fgetc(fp); TC = NUM;}
else if (c=='{') {c=fgetc(fp); TC = COM;}
else if (c == ':')
{c = fgetc(fp); TC = ASS;}
else if (c == '^')
{makelex(2, N^); TC = FIN;}
else TC = DLM;
break;
case ID:
if (isalpha(c) || isdigit(c)) {add(); c=fgetc(fp);}
else {if (j = look (TW)) makelex (1,j);
else {j = putl (TID); makelex (4,j);};
TC = H;};
break;
case NUM:
if (isdigit(c)) {d=d*10+(c - '0'); c=fgetc (fp);}
else {makelex (3, putnum()); TC = H;}
break;
/* ........... */
} /* конец switch */
} /* конец тела цикла */
while (TC!= FIN && TC!= ER);
if (TC == ER) printf("ERROR!!!");
else printf("O. K.!!!");
}

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
