

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 519.722, 51-7
ВЫЯВЛЕНИЕ И СРАВНЕНИЕ ВИДОВ СОСТОЯНИЯ ЭЛЕМЕНТОВ СИСТЕМ МЕТОДАМИ КЛАСТЕРНОГО И ЭНТРОПИЙНОГО АНАЛИЗА
Кафедра автоматизации и исследований
технической кибернетики КемГУ
8 (951) 165 79 35
zubankova. *****@***ru
Постановка задачи.
Сравнить методы кластерного и энтропийного анализа на идентичных данных. В качестве данных для исследований использовать периодические элементы таблицы Менделеева по трём признакам ионизационной энергии атомов.
Решение методом кластерного анализа.
Под кластерным анализом понимается задача разбиения исходных данных на поддающиеся интерпретации группы, таким образом, чтобы элементы, входящие в одну группу были максимально "схожи" (по какому-то заранее определенному критерию), а элементы из разных групп были максимально "отличными" друг от друга. При этом число групп может быть заранее неизвестно, также может не быть никакой информации о внутренней структуре этих групп. Существует около 100 разных алгоритмов кластеризации, однако наиболее часто используемые: иерархический кластерный анализ и кластеризация методов k-средних.
По своему подходу, все алгоритмы иерархической кластеризации делятся на два типа: сверху-вниз и снизу-вверх. Первые начинают с одного большого кластера состоящего из всех элементов, а за тем, шаг за шагом разбивают его на все более и более мелкие кластеры. Вторые, напротив, начинают с отдельных элементов постепенно объединяя их в более и более крупные кластеры. Для пользователя, принципиальной разницы между этими двумя подходами нет, куда более значимо то, каким способом алгоритм пользуется для вычисления расстояний между кластерами. По этому признаку иерархические алгоритмы делятся на алгоритмы с одиночной связью и с полной связью (существуют и другие подходы, но они менее популярны). В алгоритмах с одиночной связью расстоянием между двумя кластерами считается минимальное расстояние между всеми парами элементов из этих двух кластеров. В алгоритмах с полной связью расстоянием считается максимальное расстояние между всеми парами элементов из двух кластеров.
На рис.1 изображена дендограмма, построенная по трем признакам – Ионизационная энергия 1, Ионизационная энергия 2, Ионизационная энергия 3. По оси Х представлены показатели объектов в исходном наборе данных (названия химических элементов). По оси Y - расстояние между объектами. Связи между объектами представляются в виде П-образных линий.
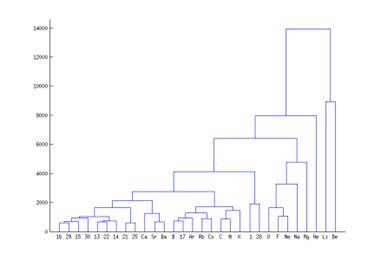
Рис.1. Дендограмма, построенная по исследуемой выборке данных
Алгоритм k-средних строит k кластеров, расположенных на возможно больших расстояниях друг от друга. Основной тип задач, которые решает алгоритм k-средних, - наличие предположений (гипотез) относительно числа кластеров, при этом они должны быть различны настолько, насколько это возможно. Выбор числа k может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции.
Описание алгоритма
1. Первоначальное распределение объектов по кластерам.
Выбирается число k, и на первом шаге эти точки считаются "центрами" кластеров. Каждому кластеру соответствует один центр.
Выбор начальных центроидов может осуществляться следующим образом:
· выбор k-наблюдений для максимизации начального расстояния;
· случайный выбор k-наблюдений;
· выбор первых k-наблюдений.
В результате каждый объект назначен определенному кластеру.
2. Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не выполнено одно из условий:
· кластерные центры стабилизировались, т. е. все наблюдения принадлежат кластеру, которому принадлежали до текущей итерации;
· число итераций равно максимальному числу итераций.
На рис.2 представлено разбиение данных на пять кластеров по одному признаку (Ионизационная энергия 1). Разными цветами показаны элементы, сгруппированные в отдельные кластеры. Крестиками соответствующих цветов обозначены центроиды кластеров. Ось X – порядковый номер элемента в таблице Менделеева, ось – ионизационная энергия 1 (т. е. тот признак, по которому осуществляется кластеризация). Кластеры
 |
расположены по вертикали.
Рис. 2. Разбиение данных на 5 кластеров по 1 признаку
Решение методом энтропийного анализа.
В основе метода лежит модель на основе формулы информационной энтропии (формулы Шеннона)
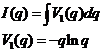
Каждый элемент 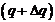 играет такую роль в системе, какую долю информации он внес в общее количество. По этому признаку ему отдается предпочтение, или он может быть выбран для некоторой миссии. Вероятность
играет такую роль в системе, какую долю информации он внес в общее количество. По этому признаку ему отдается предпочтение, или он может быть выбран для некоторой миссии. Вероятность ![]() того, что элемент
того, что элемент 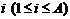 будет выбран из объекта, пропорциональна его взвешенной доле
будет выбран из объекта, пропорциональна его взвешенной доле ![]() (частной или совокупной), которая равна количеству информации.
(частной или совокупной), которая равна количеству информации.
Анализируемый объект состоит из элементов ![]() , для характеристик которых принято обозначение
, для характеристик которых принято обозначение ![]() . Соответственно, запишем модели
. Соответственно, запишем модели
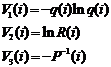
Используем общее определение среднего значения (оценки математического ожидания) и оценки среднего квадратичного отклонения (или разброса) в выборке
![]()
Отображения на оси координат можно представить в стандартном виде
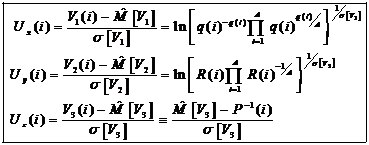
На рис 3 представлен фазовый портрет системы химических элементов, по оси абсцисс энтропийная модель энергии ионизации 1, а по оси ординат - логарифмическая модель энергии ионизации 2.
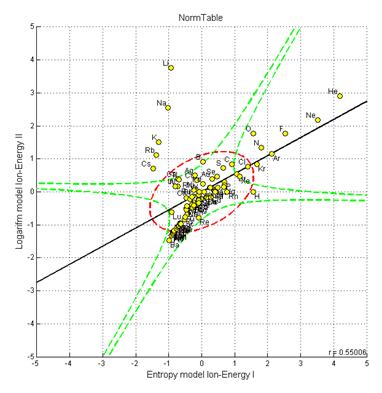 |
Рис.3. Частный фазовый портрет системы химических элементов, построенный на основе энергии ионизации
Литература
1. и ластерный анализ. Пер. с англ. . Под ред. . Предисловие . М., «Статистика», 1977. – 128с., с ил.
2. , , Логов состояния уникальных объектов. – М.: Машиностроение, 2010. – 365с.; ил.
3. Мандель анализ. – М.: Финансы и статистика. 1988 – 176 с.: ил.
Научный руководитель – д. т.н., профессор
