


Банк данных – по своему содержанию, является базой данных, но обычно это предполагает (а) общедоступность и (б) некую степень универсальности ресурса.
В качестве первого знакомства с профессиональной базой данных мы выбрали не самую молекулярную, но абсолютно незаменимую для современного специалиста в области биологии и медицины. Это знаменитый NCBI PubMed Central.
Задание 4. Зарегистрируйтесь к следующему занятию на PubMed и ознакомьтесь с ресурсами, которые он в себя включает. Обратите внимание на ресурсы в области молекулярной биологии и наличие полнотекстового доступа PubMed Central. Скриншоты стартового окна и странички регистрации приведены ниже. Как и большинство подобных ресурсов, он строится на сочетании формальной логики и интуитивного дизайна, так что особых комментариев не требует.
3.2.2. – PuBMed и PubMed Central ((ОПК-8 З.1))
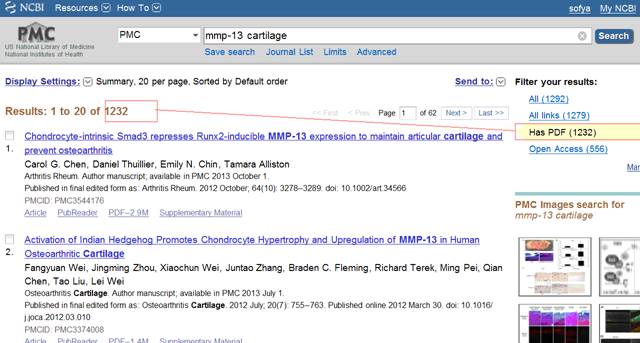
Задание 1. Воспроизведите описанный выше поиск на ресурсе PubMed Central и сверьте полученные вами данные, а также первую сверху ссылку с приведенным ниже скриншотом. Объясните полученные вами расхождения. Попробуйте сузить поиск, добавив фильтр по году выпуска, ограничив доступ только к публикациям не старше 2010 года. Оцените, какая доля публикаций по теме относится к последнему пятилетию.
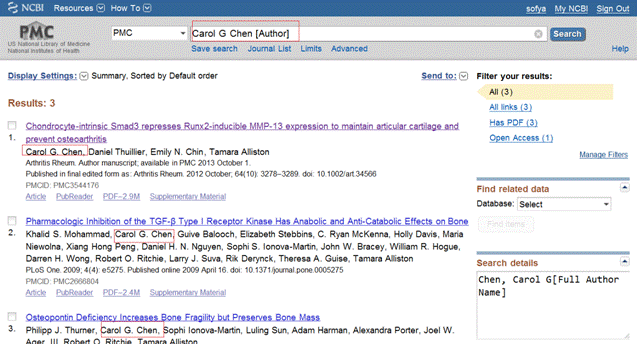
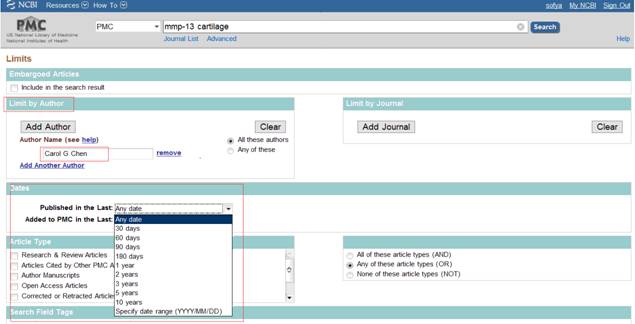
Чтобы найти публикации человека, который подписывает статьи как Carol G. Chen (один из соавторов статьи, открытой ранее), следует написать в строке запроса: Carol G Chen [Author].
Чтобы самому не писать слово "Author", можно воспользоваться сервисом "Limits", на котором можно установить дополнительные ограничения (например, в меню «Dates» можно установить лимит по времени, за который были опубликованы статьи).
Задание 2. Найдите в PubMed Central статьи крупных отечественных молекулярных биологов из МГУ имени М. В. Ломоносова: заведующего кафедрой биоинженерии академика РАН М. П. Кирпичникова (Kirpichnikov M. P.), заведующего кафедрой иммунологии, члена-корреспондента РАН С. А. Недоспасова (Nedospasov S. A.), декана факультета биоинженерии и биоинформатики, академика В. П. Скулачева (Skulachev V. P.). Сохраните ссылки на наиболее интересные из них.
Для просмотра статьи достаточно начать на один из активных доступов: в е-pub формате или. pdf-формате.
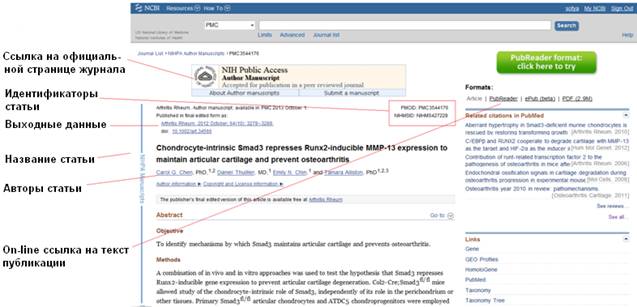
Мы также можем просмотреть наши предыдущие запросы на PMC, воспользовавшись окошком Recent activity.
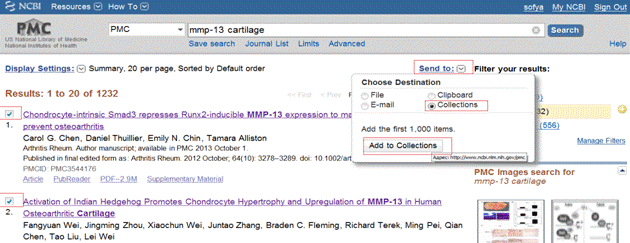
С помощью поиска по ключевым словам, можно отметить и отправить (через меню «Send to») интересующие нас статьи в личную коллекцию. Чтобы просмотреть ее, по окончании работы нужно зайти в список коллекций («My NCBI» -> «Collections»).
Задание 3. Создайте свои «золотые коллекции» статей 2012-2014 годов по ключевым цитокинам (сигнальным молекулам межклеточных взаимодействий) – ФНО-α (tumor necrosis factor alpha) и ИЛ-1 (interleukin 1). Оцените общий объем публикаций. Пооткрывайте и выберите на основании авторских коллективов, университетов и институтов, а также тематики, обзоры или статьи из самых известных мировых журналов. Проверьте эффективность работы, закрыв PubMed и вновь обратившись к нему и своей коллекции. Работает?
3.2.3. – Банки данных биологической информации ((ОПК-8 У.1))
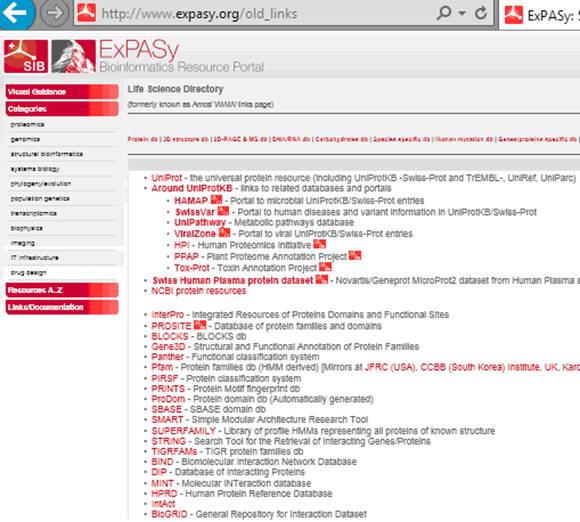
Задание 1. Зайдите на сайт SIB, приведенный выше (начало внушительного списка доступных баз данных приведено на скриншоте). Попытайтесь выйти на 2-3 сайта высокоспециализированных баз данных (например, семейств белков, межмолекулярных взаимодействий, токсикологических и т. п.). Не забудьте обратиться к помощи в виде Help или User Manual. Найдите сведения об объеме ресурса и кратко охарактеризуйте его целевое назначение. Если вы можете выделить особенности дизайна, отличающие такие базы данных от неспециализированного медико-биологического ресурса PubMed, укажите их.
Сравнение последовательностей – одна из важнейших элементарных операций вычислительной биологии и биоинформатики, являющаяся основание для многих других, более сложных манипуляций. На первый взгляд, задача не представляет особой сложности и заключается в определении схожих и отличающихся частей последовательностей. Тем не менее, за кажущейся простотой скрывается целый класс разнообразных задач, для эффективного решения которых зачастую требуются применять специальные алгоритмы.
Для работы с данными о составе биологических последовательностей предназначены многие базы данных и прикладные программы. Наиболее распространены следующие форматы описания последовательностей.
FASTA – формат для представления данных последовательности в виде текста. Иногда используются расширения .fna (Fasta Nucleic Acid) или .faa (Fasta Amino Acid) – для нуклеотидных и аминокислотных последовательностей соответственно.
EMBL – формат, используемый для представления нуклеотидных и пептидных последовательностей в базах данных EMBL (European Molecular Biology Laboratory).
GenBank – формат, используемый NCBI (National Center for Biotechnology Information) для представления нуклеотидных и пептидных последовательностей в базах данных GenBank и RefSeq.
PDB – формат для представления структур биологических молекул в базе данных Protein Data Bank.
SwissProt – формат для представления белковых последовательностей, используемый базой данных SwissProt.
Stockholm – формат, используемый базами Pfam и Rfam для представления множественного выравнивания последовательностей.
Задание 2. Зайдите на сайт SIB, а с него переходите поочередно на ресурсы UniProt, NCBI protein resourse и Pfam. Все они входят в top-20, и расположены на первой же странице поисковика. Проанализируйте на примере поиска интерлейкина-1, какие форматы записи последовательностей используют эти базы данных, насколько они совместимы и как организован экспорт для сравнения этих последовательностей специализированными программами.
3.2.4. – GenBank-NCBI ((ОПК-8 У.1))
Задание 1. Варьируя опциями запроса, постарайтесь получить информацию по ИЛ-2А, максимально близкую той, что приведена на скриншоте. Попробуйте изменить вид организма или вывести информацию о нескольких видах, нескольких интерлейкинах.
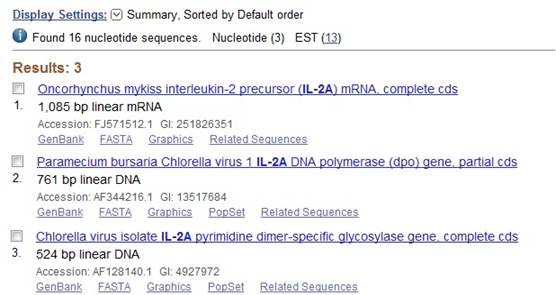
Используя дополнительное меню, вы можете ограничить поиск в соответствии с тем, что вы ищете конкретно: организм, публикация и т. п. Вы можете использовать фильтры, расположенные справа. Наиболее популярные фильтры доступны сразу, остальные открываются с помощью Manage Filters:
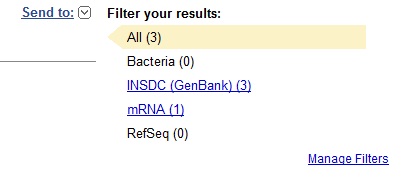
Выберем, например фильтр mRNA (1), получим на единственный источник с данными о mRNA искомого интерлейкина. Выбрав этот результат (привыкаем использовать Search), можно посмотреть общую информацию о нуклеотидной последовательности, получить доступ к расширению FASTA и графике:
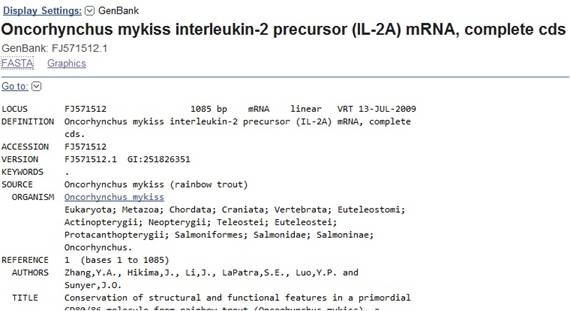


Изменить формат отображающейся информации можно, нажав в левом углу Display Settings, после чего выбрать то, что вам необходимо и применить эти параметры. В этом случае информация будет выдаваться в заданном вами объеме и очередности.
Для того, чтобы сохранить файл с результатами поиска, в правом углу нужно кликнуть Send – Coding Sequences и выбрать нужный формат записи. После этого нажмите Create format и сохраняйте.
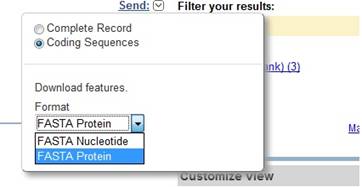
Для изменения вида кликните Customize view в правой стороне экрана, и выберите нужные параметры. Для отображения части последовательности применяется опция Change region show.
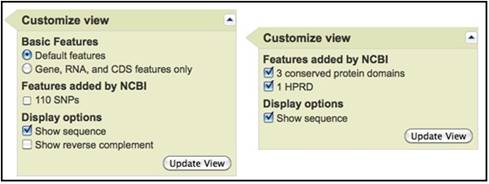
Если у вас несколько последовательностей, выберите Highlight Bar, это поможет быстро перемещаться между анализами без потери данных.
Общая информация о гене выдаются сразу же, после активирования ссылки на него, и включает в себя имя гена и его тип, официальный символ, синонимы, первоисточник и связанные ссылки, кодирующий белок, а также тип организма с полной систематикой. Ссылка Genomic context позволяет показать точное место гена, то есть сайт в конкретной хромосоме данного организма. Так же можно визуализировать геномные области:
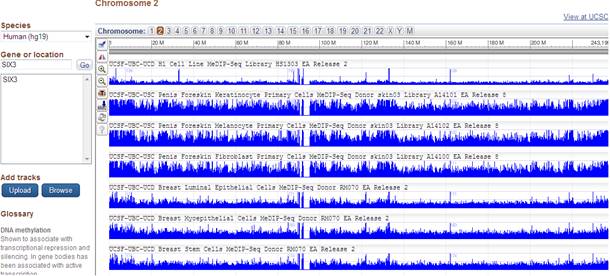
Используя другие опции, большинство из которых построено в интуитивном дизайне, можно познакомиться с типичными фенотипами, ассоциированными с экспрессией гена, актуализировать информацию о кодируемых белках, связанных последовательностях, известных вариациях структуры гена и описанных молекулярных взаимодействиях. Доступно еще несколько дополнительных ссылок, полезных при специальных исследованиях. Актуальная библиография доступна из одноименной опции.
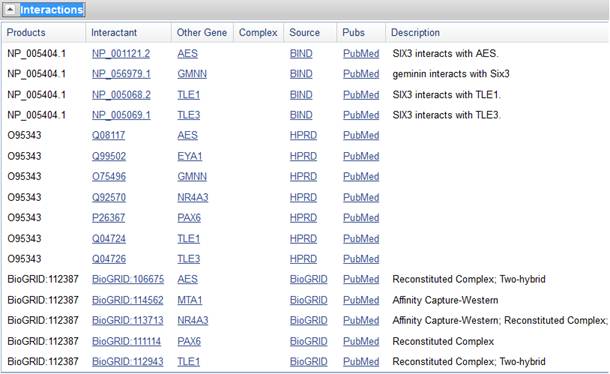
Достаточно типовой является задача, когда нам нужно отыскать и сравнить ген двух и более различных организмов. В этом случае мы выбираем эти организмы и с помощью программы BLAST сравниваем последовательности. Вначале находим нужные гены и открываем их последовательности в формате FASTA. Эти последовательности копируем целиком, чтобы вставить в соответствующие окна программы BLAST. На самом деле программа готова работать с любым текстовым файлом, так что найденные последовательности можно набирать как текст, используя, например блокнот MS Windows, и хранить в текстовых файлах.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 |
