
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Аппроксимация на диаграмме
Очень быстро и наглядно можно построить аппроксимацию непосредственно на диаграмме в ЭТ. Для этого в контекстном меню РЯДА диаграммы выберите Добавить линию тренда. В появившемся диалоге можно выбрать тип и параметры линии:

В диалоговом окне, кроме флажка «показывать уравнение на диаграмме», надо отметить также «поместить величину достоверности аппроксимации R2». Этот показатель обсудим позже.
Для линейной линии тренда получится следующее уравнение и диаграмма:
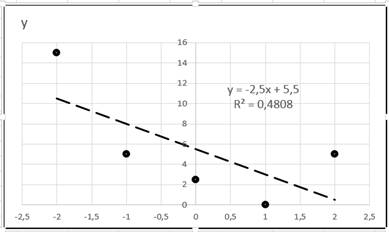
Если использовать полиномиальную линию второй степени, то получим:
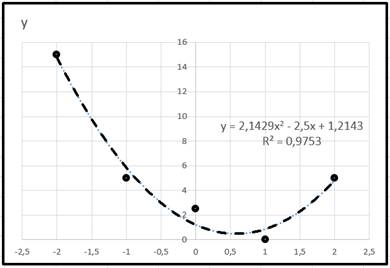
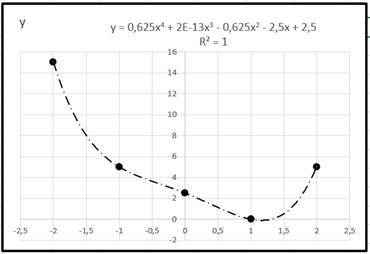 |
Принцип нахождения коэффициентов линий более высоких степеней может быть тем же – МНК. Лишь вычисления будут более громоздкими.
В то же время, если степень полинома будет на единицу меньше, чем число точек, то кривая будет проходить в точности через заданные точки. Тем самым приходим к другому виду аппроксимации функции – интерполяции.
Многие задачи приводят к нелинейным зависимостям. Например, в социально-экономической сфере (между объёмом продукции и основными факторами производства – трудом, капиталом и т. д.). К нелинейным зависимостям также приводят и психолого-педагогические исследования. Например, нелинейными являются связи между психологическими особенностями и успеваемостью по учебным предметам, что подтверждает нелинейный характер зависимостей в теории обучения.
Некоторые формы зависимостей могут быть сведены к линейным, что может упростить задачу нахождения коэффициентов зависимости. Так, степенную и показательную функции можно преобразовать в линейную путём логарифмирования и замены переменных:
Y=a*xb è lnY= ln a +b*ln x
Н=ф*ич è дт Н= дт ф +ч*дт ию
Необходимо помнить, что найденные связи не означают функциональную зависимость. Часто, если нет серьёзных теоретических оснований, исследователь просто ищет оптимальный способ описания связи. Например, для зависимости между переменными Y (рост) и X (масса) студентов 20 лет в одном лекционном потоке (60 человек) было проверено 19 форм связи. Получены оптимальные зависимости:
Y = ![]() ;
;
X= ![]() ;
;
Y – в м*100, X в кг.
.
Статистические критерии в регрессионном анализе
Продемонстрируем применение статистических критериев в регрессионном анализе. В предыдущей части нашего пособия мы достаточно подробно обсуждали необходимость построения аппроксимаций в задачах моделирования. Регрессионный анализ – это, с одной стороны, один из частных случаев аппроксимации, с другой стороны, в ходе регрессионного анализа не только находятся лучшие типы линий и их лучшие коэффициенты, но и оцениваются значимость регрессии и значимость её коэффициентов.
Регрессионный анализ
Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных.
Регрессионный анализ устанавливает формы зависимости между случайной величиной Y (зависимой) и значениями одной или нескольких переменных величин (независимых), причем значения последних считаются точно заданными. Такая зависимость обычно определяется некоторой математической моделью (уравнением регрессии), содержащей несколько неизвестных параметров. В ходе регрессионного анализа на основании выборочных данных находят оценки этих параметров, определяются статистические ошибки оценок или границы доверительных интервалов и проверяется соответствие (адекватность) принятой математической модели экспериментальным данным.
В линейном регрессионном анализе связь между случайными величинами предполагается линейной. В самом простом случае в линейной регрессионной модели имеются две переменные X и Y. Требуется по n парам наблюдений (x1, y1),( x2, y2), …,(xn, yn) построить (подобрать) прямую линию, называемую линией регрессии, которая «наилучшим образом» приближает наблюдаемые значения. Уравнение этой линии Y = а*Х + b является регрессионным уравнением. С помощью регрессионного уравнения можно предсказать ожидаемое значение зависимой величины y0, соответствующее заданному значению независимой переменной xо.
Таким образом, можно сказать, что линейный регрессионный анализ заключается в подборе графика и его уравнения для набора наблюдений. В регрессионном анализе все признаки (переменные), входящие в уравнение, должны иметь непрерывную, а не дискретную природу.
В случае, когда рассматривается зависимость между одной зависимой переменной Y и несколькими независимыми Х1, Х2, …, Хn, говорят о множественной линейной регрессии. В этом случае регрессионное уравнение имеет вид
Y = а0 + а1Х1, + а2Х2 +... + аnХn,
где а0, а1, …, аn – требующие определения коэффициенты при независимых переменных Х1, Х2, … , Хn.
Однако природа редко бывает полностью предсказуемой, и обычно имеется существенный разброс наблюдаемых точек относительно подогнанной прямой (как это было показано ранее на диаграмме рассеяния). Отклонение отдельной точки от линии регрессии (от предсказанного значения) называется остатком.
Мерой эффективности регрессионной модели является коэффициент детерминации R2 (R квадрат). Коэффициент детерминации определяет, с какой степенью точности полученное регрессионное уравнение описывает (аппроксимирует) исходные данные.
Если значение R-квадрата близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значение R-квадрата, близкое к нулю, означает плохое качество построенной модели.
Пример вычисления коэффициента детерминации в простой линейной регрессионной модели в ЭТ
Продолжим наши вычисления по пяти точкам. В данный момент посчитаем для этого простейшего случая коэффициент детерминации, который мы видели на диаграммах при построении линии тренда. Это даст возможность понять суть этого показателя.
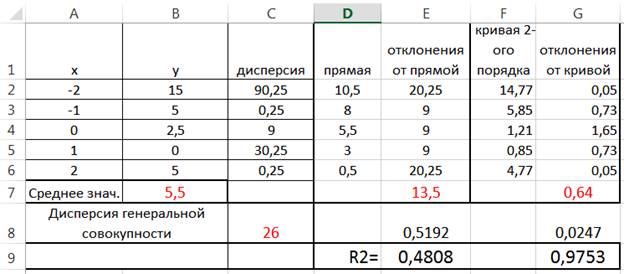
В столбце D вычислим значения на прямой линии, а в столбце F – на кривой второго порядка. Мы уже делали это в примере решения задачи нахождения эмпирической формулы. У нас уже посчитана полная дисперсия значений функции. Теперь вычислим отклонения значений функции (столбец E, формула в E2=(B2-D2)^2) от прямой и от кривой второго порядка (столбец G, формула в G2=(B2-F2)^2), соответственно. В E7 и G7 поместим, соответственно, средние по полученным пяти значениям (13.5 и 0.64).
Если теперь мы разделим эти значения на полную дисперсию, то получим долю дисперсии, необъяснённую регрессией. E8 =E7/$C$8; G8 =G7/$C$8. Коэффициент детерминации показывает долю дисперсии, объяснённую регрессией. Поэтому последнее вычисление, которое необходимо сделать для получения коэффициента детерминации, – это вычесть из единицы, полученные значения необъяснённой доли. Итак, в ячейке E8 получим: 1-0.5192 = 0.4808, а в ячейке G8 получим: 1-0.0247 = 0.9753. Именно эти значения мы и видели на диаграммах с линиями тренда.
Критерии Фишера и Стьюдента
Линия регрессии выражает наилучшее предсказание зависимой переменной (Y) по независимым переменным (X). Исследуется также значимость регрессионной модели с помощью F-критерия (Фишepa). Если величина F-критерия значима (р < 0,05), то регрессионная модель является значимой.
Достоверность отличия коэффициентов от нуля проверяется с помощью критерия Стьюдента. В случаях, когда р > 0,05, коэффициент может считаться нулевым, а это означает, что влияние соответствующей независимой переменной на зависимую переменную недостоверно, и эта независимая переменная может быть исключена из уравнения.
В MS Excel экспериментальные данные аппроксимируются линейным уравнением до 16 порядка:
где Y – зависимая переменная, Х1 ..., Х16 – независимые переменные, а0, а1..., а16 – искомые коэффициенты регрессии.
Для получения коэффициентов регрессии используется процедура Регрессия из Пакета анализа.
Предположение о нормальности остатков допускает, что распределение разницы предсказанных и наблюдаемых значений является нормальным. Для визуального определения характера распределения можно воспользоваться гистограммами остатков.
При использовании регрессионного анализа следует учитывать его основное ограничение. Оно состоит в том, что регрессионный анализ позволяет обнаружить лишь зависимости, а не связи, лежащие в основе этих зависимостей.
Регрессионный анализ дает возможность оценить степень связи между переменными путем вычисления предполагаемого значения переменной на основании нескольких известных значений.
Для решения задачи регрессионного анализа в MS Excel выбираем Анализ данных Регрессия. Задаем входные интервалы X и Y. Входной интервал Y – это диапазон зависимых анализируемых данных, он должен включать один столбец. Входной интервал X – это диапазон независимых данных, которые необходимо проанализировать. Число входных диапазонов должно быть не больше 16.
В нашем примере мера определенности равна 0,99673, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным.
ВЫВОД
Регрессионная статистика | |
Множественный R | 0,803 |
R-квадрат | 0,645 |
Нормированный R-квадрат | 0,636 |
Стандартная ошибка | 10692360 |
Наблюдения | 39,000 |
Регрессия значима, что следует из значения в столбце Значимость F.
Дисперсионный анализ | df | SS | MS | F | Значимость F |
Регрессия | 1 | 7,69E+15 | 7,69E+15 | 67,287 | 7,5617E-10 |
Остаток | 37 | 4,23E+15 | 1,14E+14 | ||
Итого | 38 | 1,19E+16 |
Теперь рассмотрим среднюю часть расчетов. Здесь даны коэффициент регрессии b (89, 53) и смещение по оси ординат, т. е. константа a (890639,48).
Коэффициенты | Стандартная ошибка | t-стати-стика | P-Значение | |
Y-пересечение | 890639,48 | 2216870,81 | 0,40 | 0,6902 |
площадь | 89,53 | 10,91 | 8,20 | 0,0000 |
Исходя из расчетов, можем записать уравнение регрессии таким образом:
Y= x*89, 53+890639,48.
Направление связи между переменными определяется на основании знаков (отрицательный или положительный) коэффициентов регрессии (коэффициента b).
Если знак при коэффициенте регрессии положительный, связь зависимой переменной с независимой будет положительной. В нашем случае знак коэффициента регрессии положительный, следовательно, связь также является положительной.
Если знак при коэффициенте регрессии отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
Использование критерия Фишера
для проверки значимости регрессионной модели
Критерий Фишера для регрессионной модели отражает, насколько хорошо эта модель объясняет общую дисперсию зависимой переменной. Расчет критерия выполняется по уравнению:
![]() ,
,
где R – коэффициент корреляции; f1 и f2 – число степеней свободы.
Первая дробь в уравнении равна отношению объясненной дисперсии к необъясненной. Каждая из этих дисперсий делится на свою степень свободы (вторая дробь в выражении). Число степеней свободы объясненной дисперсии f1 равно количеству объясняющих переменных (например, для линейной модели вида Y=A*X+B получаем f1=1). Число степеней свободы необъясненной дисперсии f2 = N-k-1, где N – количество экспериментальных точек, k –количество объясняющих переменных (например, для модели Y=A*X+B подставляем k=1).
Еще один пример: для линейной модели вида Y=A0+A1*X1+A2*X2, построенной по 20 экспериментальным точкам, получаем f1=2 (две переменных X1 и X2), f2=20-2-1=17.
Для проверки значимости уравнения регрессии вычисленное значение критерия Фишера сравнивают с табличным, взятым для числа степеней свободы f1 (бóльшая дисперсия) и f2 (меньшая дисперсия) на выбранном уровне значимости (обычно 0.05). Если рассчитанный критерий Фишера выше, чем табличный, то объясненная дисперсия существенно больше, чем необъясненная, и модель является значимой.
Коэффициент корреляции и F-критерий, наряду с параметрами регрессионной модели, как правило, вычисляются в алгоритмах, реализующих метод наименьших квадратов.
Использование критерия Стьюдента
для проверки значимости параметров регрессионной модели
Проверка статистической значимости параметров регрессионного уравнения (коэффициентов регрессии) выполняется по t-критерию Стьюдента, который рассчитывается по формуле:
![]()
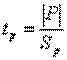
где P – значение параметра;
Sp – стандартное отклонение параметра.
Рассчитанное значение критерия Стьюдента сравнивают с его табличным значением при выбранной доверительной вероятности (как правило, 0.95) и числе степеней свободы N-k-1, где N – число точек, k – число переменных в регрессионном уравнении (например, для линейной модели Y=A*X+B подставляем k = 1).
Если вычисленное значение tp выше, чем табличное, то коэффициент регрессии является значимым с данной доверительной вероятностью. В противном случае есть основание для исключения соответствующей переменной из регрессионной модели.
