

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа №7
Логистическая регрессия и ROC-анализ
Целью выполнения данной лабораторной работы является:
Научиться обрабатывать данные и прогнозировать события, используя возможности логистической регрессии и ROC-анализ.
1. Теоретическая часть
Логистическая регрессия — метод построения линейного классификатора, позволяющий оценивать апостериорные вероятности принадлежности объектов классам.
Вообще, регрессионная модель предназначена для решения задач предсказания значения непрерывной зависимой переменной, при условии, что эта зависимая переменная может принимать значения на интервале от 0 до 1. В силу такой специфики ее часто используют для предсказания вероятности наступления некоторого события в зависимости от значений некоторого числа предикторов.
При изучении линейной регрессии мы исследуем модели вида
y = a + b1x1 + b2 x2 +...+ bn xn .
Здесь зависимая переменная y является непрерывной, и мы определяем набор независимых переменных xi и коэффициенты при них bi, которые позволили бы нам предсказывать среднее значение y с учетом наблюдаемой ее изменчивости.
Во многих ситуациях, однако, y не является непрерывной величиной, а принимает всего два возможных значения. Обычно единицей в этом случае представляют осуществление какого-либо события (успех), а нулем - отсутствие его реализации (неуспех).
Среднее значение y - обозначенное через p, есть доля случаев, в которых y принимает значение 1. Математически это можно записать как p = P(y = 1) или p = P("Успех").
ROC-кривая или кривая ошибок - показывает зависимость количества верно классифицированных положительных объектов (по оси y) от количества неверно классифицированных отрицательных объектов (по оси x).
В терминологии ROC - анализа первые называются истинно положительным, вторые – ложно отрицательным множеством. При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения. В зависимости от него будут получаться различные величины ошибок I и II рода.
В логистической регрессии порог отсечения изменяется от 0 до 1
– это и есть расчетное значение уравнения регрессии. Будем называть его рейтингом.
Введём ещё несколько определений:
TP (True Positives) – верно классифицированные положительные примеры (так называемые истинно положительные случаи);
TN (True Negatives) – верно классифицированные отрицательные примеры (истинно отрицательные случаи);
FN (False Negatives) – положительные примеры, классифицированные как отрицательные (ошибка I рода). Это так называемый «ложный пропуск» – когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные примеры);
FP (False Positives) – отрицательные примеры, классифицированные как положительные (ошибка II рода). Это ложное обнаружение, т. к. при отсутствии события ошибочно выносится решение о его присутствии (ложно положительные случаи).
Что является положительным событием, а что – отрицательным, зависит от конкретной задачи. Например, если мы прогнозируем вероятность наличия заболевания, то положительным исходом будет класс «Больной пациент», отрицательным – «Здоровый пациент». И наоборот, если мы хотим определить вероятность того, что человек здоров, то положительным исходом будет класс «Здоровый пациент», и так далее.
При анализе чаще оперируют не абсолютными показателями, а относительными – долями, выраженными в процентах:
Доля истинно положительных примеров (True Positives Rate):
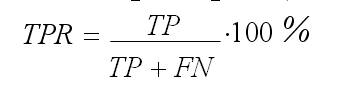
Доля ложно положительных примеров (False Positives Rate):
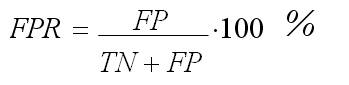
Введем еще два определения: чувствительность и специфичность модели. Ими определяется объективная ценность любого бинарного классификатора.
Чувствительность (Sensitivity) – доля истинно положительных случаев:
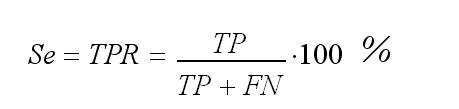
Специфичность (Specificity) – доля истинно отрицательных случаев, которые были правильно идентифицированы моделью:
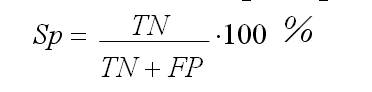
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры).
ROC-кривая получается следующим образом:
1. Для каждого значения порога отсечения, которое меняется от 0 до 1 с шагом dx (например, 0,01), рассчитываются значения чувствительности Se и специфичности Sp. В качестве альтернативы порогом может являться каждое последующее значение примера в выборке.
2. Строится график зависимости: по оси y откладывается чувствительность Se, по оси x – (100 %–Sp) (сто процентов минус специфичность), или, что то же самое, FPR – доля ложно положительных случаев.
Численный показатель площади под кривой называется AUC (Area Under Curve). С большими допущениями можно считать, что чем больше показатель AUC, тем лучшей прогностической силой обладает модель. Однако следует знать, что:
- показатель AUC предназначен скорее для сравнительного анализа нескольких моделей;
- AUC не содержит никакой информации о чувствительности и специфичности модели.
В литературе иногда приводится следующая экспертная шкала для значений AUC, по которой можно судить о качестве модели:
- отличное качество модели – интервал AUC 0,9-1,0;
- очень хорошее качество модели – интервал AUC 0,8-0,9;
- хорошее качество модели – интервал AUC 0,7-0,8;
- среднее качество модели – интервал AUC 0,6-0,7;
- неудовлетворительное качество модели – интервал AUC 0,5-0,6.
Идеальная модель обладает 100 % чувствительностью и специфичностью. Однако на практике добиться этого невозможно, более того, невозможно одновременно повысить и чувствительность,
и специфичность модели. Компромисс находится с помощью порога отсечения, т. к. пороговое значение влияет на соотношение Se и Sp. Можно говорить о задаче нахождения оптимального порога отсечения.
Практическая часть
Используя мастер импорта и файл с данными, например, C:\ProgramFiles\BaseGroup\Deductor\Samples\CreditSample. txt, создайте новый сценарий и импортируйте данные.
В мастере обработки выберите способ обработки «Логистическая регрессия».
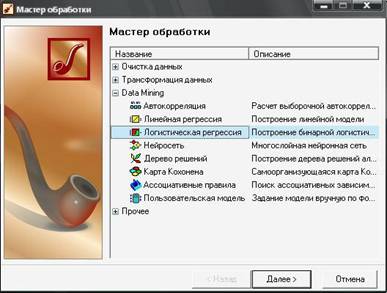
Выбор метода «Логистическая регрессия»
Прежде чем начнется обработка данных, необходимо провести нормализацию полей и настроить обучающую выборку.
Нормализация полей проводится с цель преобразования данных к виду, подходящему для обработки средствами АП «Deductor». Например, при построении нейронной сети, линейной модели прогнозирования или самоорганизующихся карт «Входящие» данные должны иметь числовой тип (т. е. непрерывный характер), а их значения должны быть распределены в определенном диапазоне. В этом случае при нормализации дискретные данные преобразуются в набор непрерывных значений.
Настройка нормализации полей вызывается с помощью кнопки «Настройка нормализации» в нижней левой части окна «Настройка назначения столбцов».
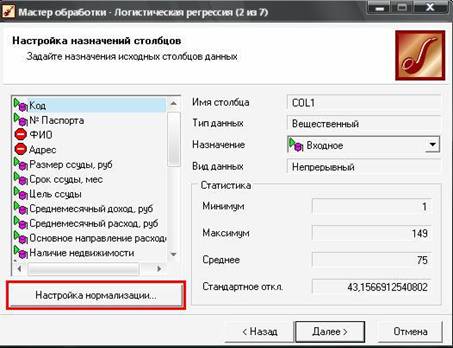
Вызов окна настройки нормализации
В окне «Настройка нормализации данных» слева приведен полный список входных и выходных полей. При этом каждое поле помечено значком, обозначающим вид нормализации:
- линейная - линейная нормализация исходных значений;
- уникальные значения - преобразование уникальных значений
в их индексы;
- битовая маска - преобразование дискретных значений в битовую маску.
В правой части окна для выделенного поля отображаются параметры нормализации.
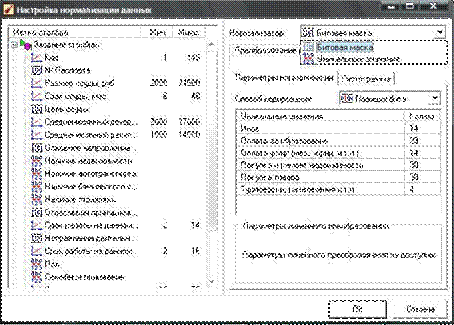
Окно настройки нормализации данных
Для числовых (непрерывных) полей с линейной нормализацией дополнительные параметры недоступны. В полях «Минимум» и «Максимум» секции «Диапазон значений» можно посмотреть минимальное и максимальное значения этого поля.
Для дискретных полей могут быть использованы два вида нормализации - уникальные значения и битовая маска.
Если дискретные значения преобразуются в битовую маску (т. е. каждому уникальному значению ставится в соответствие уникальная битовая комбинация), то возможны два способа такого преобразования, выбираемые из списка «Способ кодирования»:
1. Позиция бита - поле в этом случае представляется в виде n битов, где n - число уникальных значений в поле. Каждый бит соответствует одному значению. В 1 устанавливается только бит, соответствующий текущему значению, принимаемому полем, все остальные биты равны 0. Этот способ кодирования используется при малом числе уникальных значений.
2. Комбинация битов - каждому уникальному значению соответствует своя комбинация битов в двоичном виде.
Настройка обучающей выборки - разбиение обучающей выборки на два множества - обучающее и тестовое - для построения линейной модели.
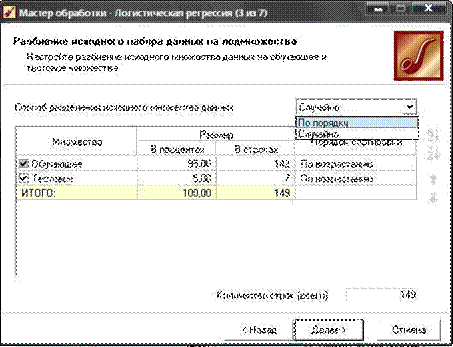
Пример настройки обучающей выборки
Обучающее множество - включает записи, которые будут использоваться в качестве входных данных, а также соответствующие желаемые выходные значения.
Тестовое множество - также включает записи, содержащие входные и желаемые выходные значения, но используемое не для обучения модели, а для проверки его результатов.
Примечание. Oбучение может с большой долей вероятности считаться успешным, если процент распознанных примеров на обучающем и тестовом множествах достаточно велик.
Следующий этап – настройка параметров остановки обучения, которая включает определение максимального числа итераций (заданная точность), задание функции правдоподобия, порога отсечения и допустимость ошибки.
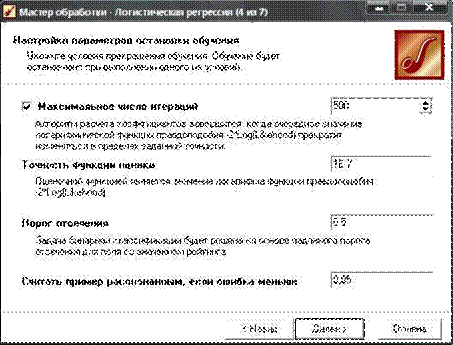
Настройка параметров остановки обучения
Итогом проведения регрессионного анализа будет построенная ROC-кривая.
2. Порядок выполнения работы:
1. С помощью мастера импорта откройте файл (например, C:\ProgramFiles\BaseGroup\Deductor\Samples\ CreditSample. txt).
2. В мастере обработки выберите «Логистическая регрессия».
3. Проведите настройку нормализации полей.
4. Настройте обучающую выборку.
5. Проанализируйте полученные данные.
6. Создайте отчет.
