

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
(0, 0, 0, 0, 1, 1, 2, 4, 8, 16, 31, 61, ...)
Для этого случая суммами соседних чисел могут быть, например, такие значения:
31 30 28 24 16
Задача
Описать в общем виде (в виде таблицы) алгоритм многофазной сортировки для трех файлов (m=3), указав распределение отрезков на каждом шаге. Минимальная длина файла при начальном распределении должна составлять не менее 5 отрезков.
Решение
Известно, что начальное распределение серий между m-1 файлами описывается суммами соседних (m-1), (m-2), ..., 1 чисел Фибоначчи порядка p=m-2. Последовательность чисел Фибоначчи порядка p начинается с p нулей, (p+1)-й элемент равен 1, а каждый следующий равняется сумме предыдущих p+1 элементов. Следуя этим правилам построения ряда Фибоначчи, имеем
p=m-2=3-2=1
То есть последовательность начинается с одного нуля. Второй элемент равен 1, а каждый последующий сумме двух (p+1=1+1=2) предыдущих элементов. Получаем последовательность
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ....
Количество суммируемых чисел должно быть m-1=3-1=2. Возьмем два числа: 5 и 8. Они образуют две суммы 13 и 8. Значит, возьмем два файла, один из которых состоит из 13, а второй из 8 отрезков. Запишем алгоритм сортировки в общем виде с помощью таблицы (числа означают количество уже слитых отрезков).
Фаза | Файл 1 | Файл 2 | Файл 3 | Примечание |
1 | 1,1,1,1,1,1,1,1,1,1,1,1,1 | 1,1,1,1,1,1,1,1 | Начальное распределение | |
2 | 1,1,1,1,1 | 2,2,2,2,2,2,2,2 | Слияние 8 отрезков в 3-ий файл | |
3 | 3,3,3,3,3 | 2,2,2 | Слияние 5 отрезков во 2-ой файл | |
4 | 5,5,5 | 3,3 | Слияние 3 отрезков в 1-ый файл | |
5 | 5 | 8,8 | Слияние 2 отрезков в 3-ий файл | |
6 | 13 | 8 | Слияние 1 отрезка во 2-ой файл | |
7 | 21 | Слияние 1 отрезка в 1-ый файл |
Если начальное распределение отрезков не соответствует последовательности Фибоначчи, то в файлы добавляются фиктивные отрезки (например, отрезки с отрицательным значениями, если файл содержит только положительные числа). Если в процессе многофазной сортировки приходится сливать два фиктивных отрезка, то образуется новый фиктивный отрезок. Если сливаются реальный и фиктивный отрезок, то просто повторяется исходный реальный отрезок.
2. Поиск и хеширование
Одной из важнейших задач при работе с большими массивами данных является ускорение поиска нужной информации. Для этого, например, можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей. При этом могут быть использованы методы поиска в упорядоченных структурах данных, например, метод половинного деления, что существенно сокращает время поиска данных по значению ключа. Однако при добавлении новой записи требуется переупорядочить таблицу. Потери времени на повторное упорядочивание таблицы могут значительно превышать выигрыш от сокращения времени поиска. Поэтому для сокращения времени доступа к данным в таблицах используется так называемое случайное упорядочивание или хеширование.
Допустим, что запись, для которой организуется поиск, хранится в некоторой таблице и что прежде, чем найти требуемую запись, необходимо организовать просмотр некоторого количества ключей.
Очевидно, что эффективными методами поиска являются те методы, которые минимизируют число этих сравнений. В идеале мы бы хотели иметь такую организацию таблицы, при которой не было бы ненужных сравнений.
Если каждый ключ должен быть извлечен за один доступ, то положение записи внутри такой таблицы может зависеть только от данного ключа.
Наиболее эффективным способом организации такой таблицы является массив.
Пример.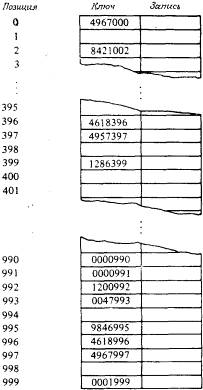 Предположим, что фирма некоторая фирма выпускает детали порядка 1000 наименований и кодирует их семизначными цифрами. Для применения прямой индексации с использованием полного семизначного ключа потребовался бы массив из 100 млн. элементов. Ясно, что это привело бы к потере большого пространства. Поэтому необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона.
Предположим, что фирма некоторая фирма выпускает детали порядка 1000 наименований и кодирует их семизначными цифрами. Для применения прямой индексации с использованием полного семизначного ключа потребовался бы массив из 100 млн. элементов. Ясно, что это привело бы к потере большого пространства. Поэтому необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона.
Тогда для хранения всего файла будет достаточно массива из 1000 элементов. Этот массив индексируется целым числом в диапазоне от 0 до 999 включительно. В качестве индекса записи об изделии в этом массиве используются три последние цифры номера изделия.
Отметим, что два ключа, которые близки друг к другу как числа (такие как 4618396 и 4618996), могут располагаться дальше друг от друга в этой таблице, чем два ключа,. которые значительно различаются как числа (такие как 0000991 и 9846995). Это происходит из-за того, что для определения позиции записи используются только три последние цифры ключа.
Функция, которая преобразует ключ записи в некоторый числовой индекс (адрес) в таблице, называется хеш-функцией: ai=h(keyi).
В данном случае адрес=h(key):= key mod 1000.
При этом данные организуются в виде таблицы при помощи хеш-функции h.
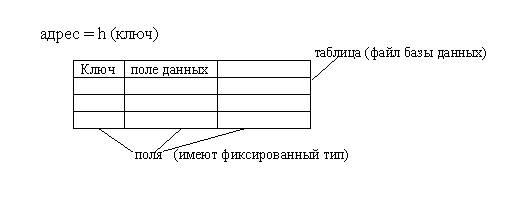
Хеш-таблица – это обычный массив с необычной адресацией, задаваемой хеш-функцией.
Хеширование[1] (глагол «hash» в английском языке означает «рубить, крошить») применяется, когда реальное количество записей значительно меньше, чем количество возможных ключей.
Идеальной (совершенной) хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса. Примером такой функции может служить функция, используемая для хранения ключевых слов языка Паскаль. Все ключевые слова (являющиеся строками символов) заранее известны и могут быть преобразованы в разные индексы.
В случае заранее неопределенного множества значений ключей и ограниченной длины таблицы подбор совершенной функции затруднителен. Поэтому часто используют хеш-функции, которые не гарантируют выполнение условия.
Если входной поток информации абсолютно случаен, то в качестве хеш-функции можно использовать, например, функцию:
h(a)=code(a) mod N
Здесь N – размер массива, а code – внутреннее машинное представление объекта a, интерпретируемое как целое число. Для строковых ключей в качестве code можно использовать некоторую функцию, выполняющую действия с кодами символов. Например, если ключ состоит из 4 символов, то можно в качестве code взять следующую функцию:
code(a)=ord(a[1])+ord(a[2])+ord(a[3])+ord(a[4])
При заполнении таблицы возникают ситуации, когда для двух неодинаковых ключей функция вычисляет один и тот же адрес: ki¹kj; h(ki) = h(kj). Данный случай носит название коллизия, а такие ключи называются ключи-синонимы.
Пример. Два ключа 0596397 и 4957397 должны располагаться по одному адресу.
Разрешение коллизий достигается путём рехеширования – специального алгоритма, который используется при размещении новой записи или при поиске существующей.
Если входной поток содержит объекты, коды которых различаются на единицу, то возможно увеличение среднего количества коллизий. Поэтому желательно, чтобы хэш-функция «разбрасывала» такие «соседние» объекты по таблице, помещая их на некотором удалении друг от друга. Для этого можно использовать следующую хэш-функцию:
h(a)=(B code(a) +C) mod N, где B и C - константы
Методы разрешения коллизий
Для разрешения коллизий используются различные методы, которые в основном сводятся к методам цепочек и открытой адресации.
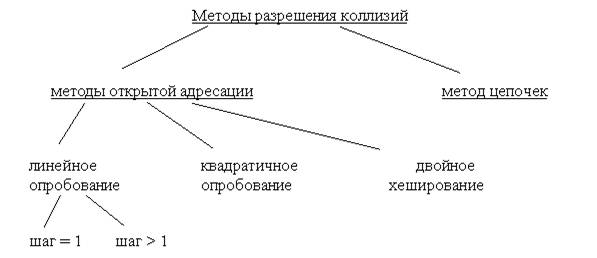
1. Метод цепочек
Методом цепочек называется метод, в котором для разрешения коллизий во все записи вводятся указатели, используемые для организации списков цепочек переполнения. В случае возникновения коллизии при заполнении таблицы в список для требуемого адреса хеш-таблицы добавляется еще один элемент.
Поиск в хеш-таблице с цепочками переполнения осуществляется следующим образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется последовательный поиск в списке, который связан с вычисленным адресом.
Процедура удаления из таблицы сводится к поиску элемента и его удалению из цепочки переполнения.
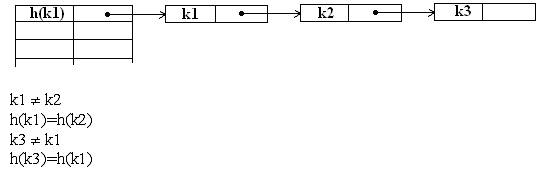
Пример. Даны следующие ключи 0596397 , 4957397, 3475397,… Используется метод цепочек.

2. Метод открытой адресации
Метод открытой адресации состоит в том, чтобы, пользуясь каким-либо алгоритмом, обеспечивающим перебор элементов таблицы, просматривать их в поисках свободного места для новой записи.
а) Линейное рехеширование сводится к последовательному перебору элементов таблицы с некоторым фиксированным шагом c.
a=(h(key) + c*i) mod N,
где i номер попытки разрешить коллизию. При c=1 происходит последовательный перебор всех элементов после текущего.
Пример. Посмотрим, что произойдет, если мы захотим ввести в таблицу некоторый новый номер изделия 0596397. Используя хеш-функцию h(key):=key mod 1000, мы найдем, что h(0596397)=397 и что запись для этого изделия должна находиться в позиции 397 в массиве. Однако позиция 397 уже занята, поскольку там находится запись с ключом 4957397. Следовательно, запись с ключом 0596397 должна быть вставлена в таблицу в другом месте.
Самым простым методом разрешения коллизий при хешировании является помещение данной записи в следующую свободную позицию в массиве. Например, запись с ключом 0596397 помещается в ячейку 398, которая пока свободна, поскольку 397 уже занята. Когда эта запись будет вставлена, другая запись, которая хешируется в позицию 397 (с таким ключом, как) или в позицию 398 (с таким ключом, как), вставляется в следующую свободную позицию, которая в данном случае равна 400.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
