

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Линейная модель парной регрессии.
Основная задача регрессионного анализа заключается в исследовании зависимости изучаемой переменной от различных факторов и отображении их взаимосвязи в форме регрессионной модели.
В регрессионных моделях зависимая (объясняемая) переменная У может быть представлена в виде функции f(Х1, Х2,..., Хк), где X1 , X2 ,..., Хк - независимые (объясняющие) переменные, или факторы.
Связь между переменной У и k независимыми факторами X можно охарактеризовать функцией регрессии У= f(Х1, Х2,..., Хк), которая показывает, каково будет в среднем значение переменной У, если переменные Хi примут конкретные значения.
Сформулируем регрессионную задачу для случая одного факторного признака.
Пусть имеется набор значений двух переменных: У= (у1, у2, …,уn ) - объясняемая переменная и Х= (х1, х2, ..., хn) - объясняющая переменная, каждая из которых содержит n наблюдений. Пусть между переменными Х и У теоретически существует некоторая линейная зависимость
У=f(X) = f(х1, х2, ..., хn) = α+βх.
Это уравнение будем называть «истинным» уравнением регрессии.
Однако в действительности между X и Y наблюдается не столь жесткая связь. Учитывая возможные отклонения, линейное уравнение связи двух переменных (парную регрессию) представим в виде:
уi= α+βхi+εi, i=![]()
где α - постоянная величина (или свободный член уравнения); β - коэффициент регрессии, определяющий наклон линии, вдоль которой рассеяны данные наблюдений; εi - случайная переменная (случайная составляющая, остаток, или возмущение).
Коэффициент регрессии β характеризует изменение переменной уi при изменении значения хi на единицу. Если β>0, переменные хi и yi положительно коррелированны, если β<0 - отрицательно коррелированны. Значение каждого наблюдения представлено как сумма двух частей - систематической α+βхi и случайной εi. В свою очередь, систематическую часть можно представить в виде уравнения: ![]() = α+βхi.
= α+βхi.
Свойства коэффициентов регрессии существенным образом зависят от свойств случайной составляющей. Для того чтобы регрессионный анализ, основанный на методе наименьших квадратов (МНК), давал наилучшие из всех возможных результаты, должны выполняться условия Гаусса — Маркова:
1. Математическое ожидание случайной составляющей в любом наблюдении должно быть равно нулю: М(εi)=0
Иногда случайная составляющая εi будет положительной, иногда отрицательной, но она не должна иметь систематического смещения ни в одном из двух возможных направлений.
2. Возмущение εi (или зависимая переменная уi) есть величина случайная, а объясняющая переменная хi - величина неслучайная. Если это условие выполнено, то теоретическая ковариация между независимой переменной и случайным членом равна нулю.
3. В любых двух наблюдениях отсутствует систематическая связь между значениями случайной составляющей. Случайные составляющие должны быть независимы друг от друга: М(εi, εj )=0 (i≠j).
Возмущения εi и εj некоррелированны (условие независимости случайных составляющих в различных наблюдениях). Это условие означает, что отклонения регрессии (а значит, и сама зависимая переменная) не коррелируют. В случае временного ряда yt условие М(εi, εj )=0 означает отсутствие автокорреляции ряда εi.
4. Дисперсия случайной составляющей должна быть постоянна для всех наблюдений. D(εi)=σεi2
Это условие гомоскедастичности, или равноизменчивости, случайной составляющей (возмущения).
Величина σεi2 неизвестна. Одна из задач регрессионного анализа состоит в оценке стандартного отклонения случайной составляющей.
Наряду с условиями Гаусса - Маркова обычно также предполагается нормальность распределения случайного члена. Если случайный член нормально распределен, то так же будут распределены и коэффициенты регрессии.
В тех случаях, когда предпосылки выполняются, оценки, полученные по МНК, будут обладать свойствами несмещенности, эффективности и состоятельности.
Несмещенность оценки означает, что математическое ожидание остатков равно нулю. Если оценки обладают свойством несмещенности, то их можно сравнивать по разным исследованиям.
Оценки считаются эффективными, если они характеризуются наименьшей дисперсией. Поэтому несмещенность оценки должна дополняться минимальной дисперсией.
Состоятельность оценок характеризует увеличение их точности с увеличением объема выборки. Достоверность доверительных интервалов параметров регрессии обеспечивается, если оценки будут несмещенными, эффективными и состоятельными.
Для оценки параметров регрессионного уравнения наиболее часто используют метод наименьших квадратов.
Метод наименьших квадратов (МНК) дает оценки, имеющие наименьшую дисперсию в классе всех линейных оценок, если выполняются предпосылки нормальной линейной регрессионной модели. МНК минимизирует сумму квадратов отклонения наблюдаемых значений уi от модельных значений ![]()
Оценки α, β находят путем минимизации суммы квадратов
Q(α, β)=![]()
по всем возможным значениям α и β при заданных (наблюдаемых) значениях х1, ..., хn, у1, ..., уn. Задача сводится к математической задаче поиска точки минимума функции двух переменных. Точка минимума находится путем приравнивания к нулю частных производных функции Q(α, β) по переменным α и β. Это приводит к системе нормальных уравнений:
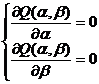 И далее:
И далее: 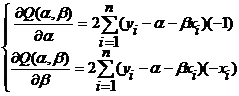
Искомые значения α и β удовлетворяют соотношениям:
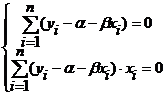
Эту систему двух уравнений можно записать в виде:
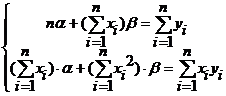
Она является системой двух линейных уравнений с двумя неизвестными и может быть решена любым известным методом. Решение может существовать только при выполнении условия: 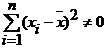 , которое называется условием идентифицируемости модели наблюдений уi= (α+βхi)+εi, i=
, которое называется условием идентифицируемости модели наблюдений уi= (α+βхi)+εi, i=![]() и означает, что не все значения х1, х2, ..., хn совпадают между собой. В матричной форме парной регрессии имеет вид: У=Х∙а+ε,
и означает, что не все значения х1, х2, ..., хn совпадают между собой. В матричной форме парной регрессии имеет вид: У=Х∙а+ε,
где У – вектор – столбец размерности n*1 наблюдаемых значений зависимой переменной; Х – матрица размерности n*2 наблюдаемых значений факторных признаков (дополнительный фактор х0, состоящий из одних единиц, вводится для вычисления свободного члена); а – вектор-столбец размерности 2*1 неизвестных, подлежащих оценке коэффициентов регрессии; ε – вектор-столбец размерности n*1 ошибок наблюдений. Таким образом:
У=![]() , Х=
, Х=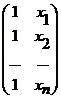 , а=
, а=![]() , ε=
, ε= .
.
Решение системы нормальных уравнений в матричной форме:
А=(Х 'Х)-1 Х 'У=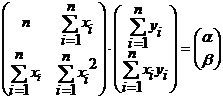
Качество модели регрессии связывают с ее адекватностью наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков εi.
Остаток εi представляет собой отклонение фактического значения зависимой переменной от ее значения, полученного расчетным путем:
εi= уi -![]() , i=
, i=![]()
Если εi= 0 (i=![]() ), то для всех наблюдений фактические значения зависимой переменной совпадают с расчетными (теоретическими) значениями.
), то для всех наблюдений фактические значения зависимой переменной совпадают с расчетными (теоретическими) значениями.
Графически это означает, что теоретическая линия регрессии (линия, построенная по функции ![]() = α+βхi.) проходит через все точки корреляционного поля, что возможно только при строго функциональной связи.
= α+βхi.) проходит через все точки корреляционного поля, что возможно только при строго функциональной связи.
На практике имеет место некоторое рассеивание точек корреляционного поля относительно теоретической линии регрессии, т. е. отклонения эмпирических данных от теоретических (εi≠0). Величина этих отклонений и лежит в основе расчета показателей качества (адекватности) уравнения регрессии.
При анализе качества модели регрессии используется основное положение дисперсионного анализа, согласно которому общая сумма квадратов отклонений зависимой переменной от среднего значения у может быть разложена на две составляющие - объясненную и необъясненную уравнением регрессии:
![]() ,
,
где ![]() - значения у, вычисленные по модели
- значения у, вычисленные по модели ![]() = α+βхi.
= α+βхi.
Разделив правую и левую часть равенства на ![]() , получаем
, получаем
1=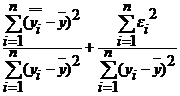
Коэффициент детерминации определяется следующим образом:
R2=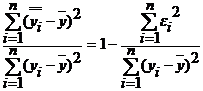 .
.
Данный коэффициент показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака У учтена в модели и обусловлена влиянием на него факторов. Чем ближе R2 к единице, тем выше качество модели.
Коэффициент множественной корреляции (индекс корреляции):
R=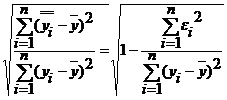 .
.
Данный коэффициент универсален, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Для парной модели регрессии индекс корреляции равен коэффициенту парной корреляции: R=![]() .
.
Для оценки качества регрессионных моделей используется также средняя относительная ошибка аппроксимации:
Еотн=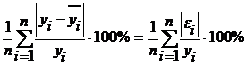
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации; Еотн<7% свидетельствует о хорошем качестве модели.
После того как уравнение регрессии построено, выполняется проверка значимости построенного уравнения в целом и отдельных параметров.
Оценка значимости уравнения регрессии позволяет узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет. При этом выдвигают основную гипотезу о незначимости уравнения в целом, которая формально сводится к гипотезе о равенстве нулю параметров регрессии, или, что то же самое, о равенстве нулю коэффициента детерминации: R2=0. Альтернативная гипотеза о значимости уравнения — гипотеза о неравенстве нулю параметров регрессии.
Для проверки значимости модели регрессии используется F-критерий Фишера, вычисляемый как отношение дисперсии исходного ряда и несмещенной дисперсии остаточной компоненты. Если расчетное значение, c ν1=k и ν2= n-k-1 степенями свободы (k - количество факторов, включенных в модель), больше табличного при заданном уровне значимости α, то модель считается значимой.
Для модели парной регрессии:
F=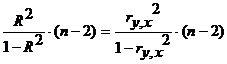 .
.
В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты S2. Стандартная ошибка Se – корень квадратный из S2 и вычисляется по формуле: Se=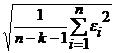 , где k – количество факторов, включенных в модель.
, где k – количество факторов, включенных в модель.
Для модели парной регрессии Se=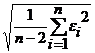 .
.
Для анализа статистической значимости параметров модели парной регрессии вычисляют стандартные ошибки коэффициентов
S α=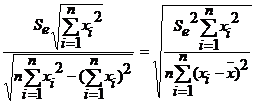
Sβ=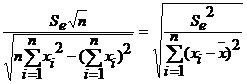 , где
, где ![]() - среднее значение независимой переменной х; Se – стандартная ошибка.
- среднее значение независимой переменной х; Se – стандартная ошибка.
Проверка значимости отдельных коэффициентов регрессии связана с определением расчетных значений t-критерия (t-статистики) для соответствующих коэффициентов регрессии:
t α расч=![]() ; t β расч=
; t β расч=![]() .
.
Расчетные значения t расч сравниваются с табличными t табл. Табличное значение критерия определяется при (n-2) степенях свободы (n – число наблюдений) и соответствующем уровне значимости α.. Если t расч с (n-k-1) степенями свободы больше t табл при заданном уровне значимости, то коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, должен быть исключен из модели, а оставшиеся в модели параметры пересчитаны.
Прогнозированное значение переменной У получается при подстановке в уравнение регрессии ожидаемой величины фактора Х: ![]() = α+βхпрогн. Такой прогноз называется точечным.
= α+βхпрогн. Такой прогноз называется точечным.
у![]() с вероятностью (1-α) попадут в доверительный интервал:
с вероятностью (1-α) попадут в доверительный интервал:
у![]() Є[
Є[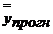 -Se tα
-Se tα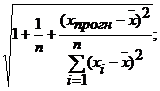 +Se tα
+Se tα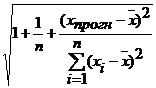 ]
]
