

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Семантика изоляции
Управление семантикой изоляции осуществляется уровнями изоляции транзакций ядра СУБД. Если доступ к данным FILESTREAM осуществляется через Win32 API, то поддерживается только уровень изоляции READ COMMITTED. Доступ через Transact-SQL также обеспечивает уровень изоляции REPEATABLE READ и сериализуемые уровни изоляции. Кроме того, при доступе через Transact-SQL «грязное» считывание разрешено через уровень изоляции READ UNCOMMITTED или указание запроса NOLOCK, но такой доступ не отображает обновления откатом незавершенных данных FILESTREAM.
Открытые операции доступа к файловой системе не ожидают никаких блокировок. Вместо этого открытые операции моментально завершаются ошибкой, если вследствие изоляции транзакции
не удается получить доступ к данным. Потоковые вызовы API завершаются ошибкой ERROR_SHARING_VIOLATION, если вследствие нарушения изоляции продолжение открытой операции невозможно.
Частичные обновления
Чтобы разрешить частичные обновления, приложение может выполнить команду FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT для выборки старого содержимого в файл, открытый с помощью ссылки на дескриптор. Это можно также сделать через управляемый интерфейс SqlFileStream API с помощью флажка ReadWrite. Это приведет к копированию старого содержимого на стороне сервера, как было описано выше. Чтобы обеспечить повышение производительности приложения и избежать потенциальных сбоев из-за истечения времени ожидания при работе с очень большими файлами, следует использовать асинхронные операции ввода-вывода.
Если выполнение команды FSCTL произошло после записи в дескриптор, то сохраняется последняя операция записи, а результаты предыдущих операций записи в дескриптор теряются.
Дополнительные сведения о частичных обновлениях см. в разделе «FSCTL_SQL_FILESTREAM_
FETCH_OLD_CONTENT» электронной документации по SQL Server 2008 (http://technet. microsoft. com/
ru-ru/library/cc627407.aspx).
Сквозная запись с удаленных клиентов
Удаленный доступ файловой системы к данным FILESTREAM осуществляется по протоколу Server Message Block (SMB). Если клиент является удаленным, то кэширование операций записи зависит от заданных параметров и используемого API. Например, по умолчанию машинный код API выполняет сквозную запись, а управляемые API по умолчанию используют буферизацию. Это различие появилось в результате отзывов пользователей о разных API и опыта их использования в предварительных CTP-версиях SQL Server 2008.
В приложениях, работающих на удаленных клиентах, рекомендуется объединять небольшие операции записи (выполнять сквозную буферизацию), чтобы сократить число операций записи
за счет укрупнения данных. Кроме того, если используется буферизация, то клиент должен выполнить явную очистку до фиксации транзакции.
Создание представлений, отображаемых в памяти (в памяти операций ввода-вывода),
с дескриптором FILESTREAM не поддерживается. Если для данных FILESTREAM используется отображение в памяти, то ядро СУБД не может гарантировать целостность, согласованность
и надежность данных.
Условия использования FILESTREAM
Несмотря на многочисленные преимущества технологии FILESTREAM, в некоторых случаях
она не будет оптимальным выбором. Как отмечалось ранее, размер данных больших двоичных объектов и шаблоны доступа — наиболее важные факторы, определяющие способ хранения данных больших двоичных объектов целиком внутри базы данных или в виде FILESTREAM.
Размер влияет на следующие факторы:
· Эффективность доступа к данным больших двоичных объектов при использовании каждого механизма хранения. Как отмечалось ранее, потоковый доступ к крупным массивам данных больших двоичных объектов более эффективен с использованием FILESTREAM, однако частичные обновления выполняются медленнее (иногда значительно).
· Эффективность резервного копирования комбинированных структурированных данных
и данных больших двоичных объектов с использованием каждого из механизмов хранения. Резервное копирование файлов базы данных SQL Server совместно с большим количеством файлов FILESTREAM выполняется медленнее, чем резервное копирование только файлов баз данных SQL Server такого же общего размера. Это связано
с дополнительными затратами на резервное копирование каждого файла в файловой системе NTFS (одно на каждое значение данных FILESTREAM). Издержки будут тем заметнее, чем меньше размер файлов FILESTREAM (возрастает доля затрат времени
в общем времени резервного копирования 1 МБ данных).
В качестве примера на следующей диаграмме приведена относительная пропускная способность при локальном считывании данных больших двоичных объектов разного размера с помощью varbinary (max), FILESTREAM с помощью Transact-SQL и FILESTREAM через файловую систему NTFS. По синей линии можно видеть, что доступ в системе Win32 к данным FILESTREAM стал
в несколько раз быстрее, чем доступ с использованием Transact-SQL к данным varbinary (max) по мере увеличения размера данных. Обратите внимание, что показатели пропускной способности даны в мегабитах в секунду (Мбит/с).
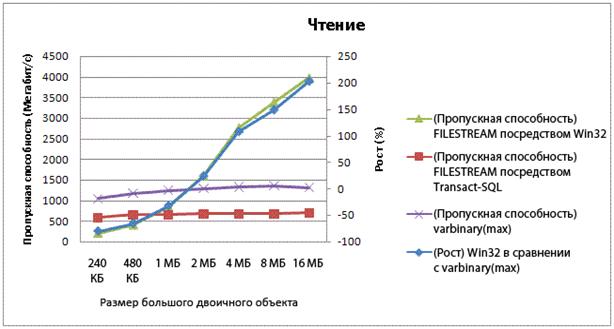
Рис. 1. Производительность при считывании больших двоичных объектов различных размеров
Показатели NTFS включают время, необходимое для начала транзакции, получения пути
и контекста транзакции из SQL Server, а также открытия дескриптора Win32 для данных FILESTREAM. Каждый тест был выполнен с использованием одного и того же компьютера
с 4 процессорными ядрами и горячим буферным пулом SQL Server.
Другой фактор, который следует учитывать, — можно ли переписать клиент или приложение промежуточного уровня на использование Win32 API наряду с обычным доступом к SQL Server. Если нет, то FILESTREAM будет неподходящим вариантом, поскольку оптимальная производительность достигается именно при использовании API потоковой передачи Win32.
Настройка Windows для FILESTREAM
Как и при любом развертывании, перед началом развертывания приложения, использующего FILESTREAM, важно подготовить сервер Windows, на котором будет размещаться база данных SQL Server и соответствующие контейнеры данных FILESTREAM. В этом разделе описано, как настроить оборудование хранилища и файловую систему NTFS при подготовке к использованию FILESTREAM. Затем будет показано, как включить FILESTREAM на уровне Windows.
Выбор и настройка оборудования
Одна из наиболее типичных причин низкой производительности при выполнении рабочей нагрузки — неудачная конфигурация оборудования. Иногда причина заключается в нехватке памяти, приводящей к «пробуксовке» в буферном пуле SQL Server, а иногда причина просто в том,
что пропускная способность ввода-вывода оборудования хранилища недостаточна для
данной рабочей нагрузки. Для приложений, которые будут использовать FILESTREAM
для высокопроизводительной потоковой передачи данных больших двоичных объектов
с использованием Win32 API, чрезвычайно важен выбор и настройка оборудования хранилища.
В следующих разделах приведены некоторые рекомендации по выбору и организации хранилища. Более глубокое рассмотрение этой темы можно найти в техническом документе «Physical Database Storage Design» на сайте TechNet (http://www. /technet/prodtechnol/sql/2005/
physdbstor. mspx). После проектирования и оптимизации структуры приложения рекомендуется провести нагрузочное тестирование, чтобы проверить производительность подсистемы ввода-вывода. Подробное описание см. в статье «Predeployment I/O Best Practices» на сайте TechNet
SQL Server Best Practices (http://www. /technet/prodtechnol/sql/bestpractice/pdpliobp. mspx).
Схема физического хранения
Принимая решение о местоположении контейнера данных FILESTREAM, обязательно учитывайте предполагаемую рабочую нагрузку на него, а также рабочие нагрузки на все совместно размещенные контейнеры и файлы данных SQL Server. Возможно, потребуется разместить каждый контейнер данных FILESTREAM на отдельном томе, так как наличие нескольких контейнеров данных
с интенсивными рабочими нагрузками на одном томе может привести к повышению конкуренции
за ресурсы.
Отсюда следует, что, если просто разместить их все на одном томе, не принимая в расчет рабочих нагрузок, то это чревато снижением производительности. Необходимая степень разделения, различная для разных клиентов.
Можно также создать схему таблицы внутри SQL Server, которая обеспечит грубую балансировку нагрузки данных FILESTREAM между несколькими томами. Это описано в разделе «Балансировка загрузки данных FILESTREAM».
Выбор уровня RAID
Преимущества применения технологии RAID известны, и, кроме того, много написано о выборе уровня RAID, соответствующего требованиям приложения, поэтому в данном техническом документе эти вопросы не обсуждаются. В упомянутом выше техническом документе «Physical Database Storage Design» имеется отличный раздел об уровнях RAID и выборе уровней RAID. Ниже всего лишь кратко описаны факторы, которые необходимо принимать во внимание.
Уровни RAID имеют ряд отличий, прежде всего по производительности чтения и записи, по стоимости и устойчивости к сбоям. Например, массив RAID 5 имеет относительно низкую цену, устойчив к сбою одного диска в массиве и не всегда пригоден для интенсивных рабочих нагрузок. С другой стороны, RAID 10 обеспечивает отличную производительность чтения и записи
и устойчив к ошибкам нескольких дисков (в зависимости от уровня зеркального отображения), однако цена их выше при условии, что как минимум 50 % дисков в массиве RAID избыточные. Ниже перечислены три основных фактора, которые нужно учитывать при выборе уровня RAID. Выбор уровня RAID может быть другим для тома, где хранятся все пользовательские базы данных, и даже для томов, где хранятся файлы данных и файлы журнала одной базы данных.
Если рабочая нагрузка связана с высокопроизводительной потоковой передачей данных FILESTREAM, то том контейнера данных FILESTREAM однозначно остановит свой выбор на использовании уровня RAID, поскольку он обеспечивает самую высокую производительность при считывании. Однако это может не дать высокой устойчивости при возникновении ошибок. С другой стороны, первым выбором может быть использование того же уровня RAID, что и у других томов, содержащих данные базы данных, но это может не обеспечить необходимого уровня производительности, требуемого для рабочей нагрузки.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
