
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Так как коды ldpc являются линейными кодами, они могут кодироваться при помощи соответствующей N ×K порождающей матрицы G. В частности, кодовое слово может быть получено следующим образом
x = Ga,
- где а – вектор К информационных бит.
Так как код систематический, генерирующая матрица имеет вид:
![]() (4.6)
(4.6)
- где P это (N−K)×K - матрица, которая формирует проверочные биты кодового слова.
Закодированный вектор х имеет форму
(a1, . . . , aK, p1, . . . , pN−K)T (4.7)
- где вектор проверочных бит p = (p1, . . . , pN−K)T = Pa.
Матрица ![]() определяется как
определяется как
 (3.8)
(3.8)
- это проверочная матрица систематического кода, полученного из порождающей матрицы G, означает, что вектор х является кодовым вектором если, и только если, выполняется соотношение:
![]() (4.9)
(4.9)
Это может быть легко показано, так как любой вектор бит x = (x1, . . . , xN) является кодовым словом если последние (N – K) биты равны проверочным битам вектора р, сгенерированным по первым К битам кодового слова:
p = P(x1, . . . ,xK)T (4.10)
Легко увидеть, что

равна 0, используя логическую алгебру, если, и только если,
![]()
то есть если х – кодовое слово.
Пораждающая матрица G полностью определяется своей подматрицей P, которая, в свою очередь, может быть вычислена при помощи преобразования данной проверочной матрицы H, в ее ![]() форме, при помощи простых операций с рядами (замена ряда линейной комбинацией ряда с другими рядами) [7].
форме, при помощи простых операций с рядами (замена ряда линейной комбинацией ряда с другими рядами) [7].
Учтем проверочную матрицу H, для того, чтобы гарантировать существование соответствующего систематического кода, правая (N-K) × (N-K) суб-матрица H должна быть не единственной. Однако, следует заметить, что если H имеет максимальный ранг, то существует множество N – K столбцов матрицы H, которые формирует невырожденная матрица. Таким образом, можно получить проверочную матрицу соответствующего систематического кода, применяя перестановки столбцов H, которая ставит эти столбцы в правые позиции. Несмотря на это, H является редкой по определению, подматрицы Р от G, в общем, плотные. Это означает, что, отказываются от части единичной матрицы, для того, чтобы хранить G, по крайней мере,
![]()
бит памяти не требуется. С типичным LDPC кодами размер кодового слова колеблется от 103 до 104 бит, это означает, что память для хранения G, например, для кода скоростью 1/2, составляет по крайней мере порядка 106 бит.
Операция умножения матриц, выполняемая только для плотной части матрицы G, требует K(N-K)= К2(1/R-1) операций умножения и (К-1)(N-K)=(К2 - К)(1/R-1) дополнительных операций (логические операции).
4.2 Алгоритмы декодирования LDPC-кодов
Декодирование – это процедура поиска и исправления ошибки, возникших в кодовом слове при передаче по каналу связи, или поиск кодового слова по вектору, принятому из канала. В зависимости от вида решений в демодуляторе различают мягкое и жесткое декодирование.
Применение мягких решений несколько усложняет декодер, но позволяет получить дополнительный выигрыш от декодирования – порядка нескольких децибел.
4.3 Алгоритм ”Сумма произведений”.
Декодирование по максимуму правдоподобия, на символ или кодовое слово обобщенного линейного блочного кода, в общем, непростая задача.
Тем не менее, Галлагер предложил три субоптимальных итерационных алгоритма декодирования для LDPC кодов, которые используют разреженность проверочной матрицы этого кода. Два из них являются простыми и основаны на алгоритмах жесткого решения и техники побитовой обработки, тогда как третий является более точным алгоритмом, который основан на итерационном обмене действительными надежностями бит кодового слова. Эти алгоритмы широко известны как алгоритмы Галлагера А, B, и C.
Все эти алгоритмы обладают привлекательным свойством - возможностью применения графа Таннера для декодирования. В частности, они характеризуются тем, что узлы, как переменных, так и проверочные, выступают в качестве процессоров обмена вещественными сообщениями по кодовому графу. Вся обработка производится локально, т. е. для каждого узла, она основана только на доступных ему сообщениях. Сообщения представляют надежность значения битов кодового слова, в частности, они представляют оценку вероятности того, что каждый конкретный бит кодового слова равен "1".
Алгоритм Галлагера С, в настоящее время, введен с акцентом на его реализацию в логарифмической области. Учитывая бинарность случайной величины X, принимающей значения в интервале {0,1}, её отношение правдоподобия λx определяется как
![]() (4.3.1)
(4.3.1)
и соответствующие логарифмическое отношение правдоподобия:
![]()
На каждой итерации алгоритма декодирования: во-первых, каждый узел переменной вычисляет выходное сообщение для каждой соединенной с ним вершиной (i), и, затем узел проверок вычисляет выходное сообщение для каждой подключенной к нему вершины (ii). Порядок вычисления сообщения, как правило, показывают графиком.
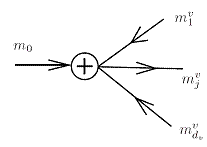
Рисунок 4.3.1 - Узел переменной: величины входящие в расчет j – того выхода [4]
На рисунке 4.3.1, показана степень dv узла переменных и показаны входные и выходные сообщения. Можно отметить, что существует вход, соединенный с узлом и чье значение отмечено как m0, который представляет входное значение надежности, связанное с соответствующим битом узла переменной, выраженной логарифмом правдоподобия. Это значение входной надежности, как правило, рассчитываются на основе наблюдений за каналом [6].
Алгоритм декодирования может быть получен на основании вероятности домена, и как следствие в результате вычисления логарифма отношения правдоподобия (LLR) домена. Сообщение на выходе узла переменных это вероятность того, что соответствующий бит X кодового слова равен "1", из всего множества независимых наблюдений относительно бита. Предположим, что есть dv независимых наблюдений ξ1, . . . ,ξdv. Тогда отношение вероятностей наблюдений будет выглядеть:
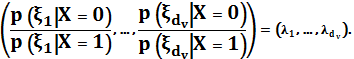 (4.3.2)
(4.3.2)
Вероятность равенства Х = 0 в данных наблюдениях
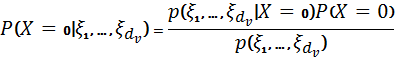 (4.3.3)
(4.3.3)
и соответствующее отношение правдоподобия
![]() (4.3.4)
(4.3.4)
которое предполагает P(X = 0) = P(X = 1) = 1/2, в
![]() (3.3.2)
(3.3.2)
где ![]() .
.
Алгоритм декодирования узла переменных, может быть разработан в области логарифма правдоподобия. Каждый узел переменной степени-dv, как показано на рисунке 3.3.1, вычисляет dv выходных сообщений, следовательно:
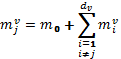 (4.3.5)
(4.3.5)
где mvj - j – тое выходное сообщение и mvi - i – тое входное сообщение от узла проверки. Другими словами узел переменных обрабатывает все сообщения на его входе как независимые данные: dv – один от узлов проверок и один m0, соответствует отношению правдоподобия, ассоциирующееся с первичными данными.
Можно заметить, что сумма явно исключает сообщения, приходящее от ребра, выходное сообщение которого было вычислено.
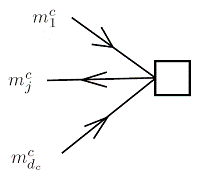
Рисунок 4.3.2 - Узел проверки: показаны величины, входящие в расчет
j – ого выходного сообщения [4]
На рисунке 4.3.2 показан общий узел проверки степени - dc. Проверочный узел представляет разбиение на биты кодового слова, связанных с узлами переменных, соединенных с ним. Это ограничение выражается в соответствующей строке проверочной матрицы: сумма бит кодового слова по модулю 2, связанных с проверочным узлом, равна 0. В этом случае, проблема заключается в следующем:
![]() (4.3.6)
(4.3.6)
Для данных вероятностей, соответствующих dc−1 битам из dc бит, соединенных с узлом проверки четности, вычислим вероятность P0, что их сумма по модулю 2 равна 0 (мы знаем, что сумма всех битов dc по модулю 2 равна 0 ). Предположим что все данные наблюдений, ведущих к вычислению P(X1 = 1), . . . , P(Xdc−1 = 1) независимы, тогда
(4.3.7)
где "х: четная сумма" обозначает все биты векторов х длины dc-1, сумма которых является четным числом, то есть, х содержит четное число единиц. Вычисление этой величины может быть выполнено по следующим принципам.
Во-первых, рассмотрим следующий многочлен q(t):
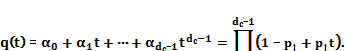 (4.3.8)
(4.3.8)
Заметим, что коэффициент αi задается как
![]() (4.3.9)
(4.3.9)
Другими словами, αi - это вероятность наличия i единиц и dc-1-i нулей среди dc-1 бит. Заметим теперь, что q(1) это сумма всех коэффициентов и q(−1) сумма всех коэффициентов, где все нечетные коэффициенты изменили знак. Следовательно
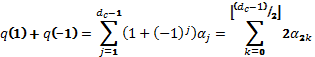 (4.3.10)
(4.3.10)
равна удвоенной сумме всех четных коэффициентов, т. е. удвоенной вероятности приема четного числа единиц. Как следствие,
![]() (4.3.11)
(4.3.11)
Соответствующее логарифмическое отношение правдоподобия, есть

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
