

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ОЦЕНКА МАСШТАБИРУЕМОСТИ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ ДЛЯ ОДНОШАГОВЫХ МНОГОТОЧЕЧНЫХ МЕТОДОВ решения ЗАДАЧи КОШИ
,
Донецкий национальный технический университет, Украина
В докладе исследование масштабируемости параллельных вычислений проиллюстрировано на примере решения задачи Коши на основе одношаговых разностных схем с контролем погрешности на шаге. В качестве параллельных вычислительных систем использованы следующие кластеры ДонНТУ, имеющие MIMD-архитектуру с распределенной памятью: однородный NeClus-2010 и неоднородный WCCS-2003.
Существует несколько подходов для количественной оценки свойств масштабируемости параллельного алгоритма в совокупности с архитектурой, на которой он реализован. Наиболее применяемой является метрика, основанная на введении функции изоэффективности [1-2]. Для этого определяется новая динамическая характеристика: ![]() – накладные расходы на параллелизм. Для заданной параллельной системы
– накладные расходы на параллелизм. Для заданной параллельной системы ![]() есть функция размерности задачи –
есть функция размерности задачи – ![]() , числа процессоров –
, числа процессоров – ![]() , машинно-зависимых констант вычислений и обмена, и определяется, как:
, машинно-зависимых констант вычислений и обмена, и определяется, как:
![]() , (1)
, (1)
где ![]() – время, решения задачи заданного размера на одном процессоре с помощью наилучшего последовательного алгоритма;
– время, решения задачи заданного размера на одном процессоре с помощью наилучшего последовательного алгоритма; ![]() – общее время реализации параллельного алгоритма на параллельной архитектуре:
– общее время реализации параллельного алгоритма на параллельной архитектуре: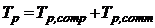 .
.
Пусть ![]() задает необходимый уровень эффективности выполняемых вычислений, тогда:
задает необходимый уровень эффективности выполняемых вычислений, тогда:
![]()
![]() . (2)
. (2)
Порождаемую последним соотношением зависимость ![]() между сложностью решаемой задачи и числом процессоров называют функцией изоэффективности. Выражение (2) – центральное соотношение изоэффективного анализа. Функция
между сложностью решаемой задачи и числом процессоров называют функцией изоэффективности. Выражение (2) – центральное соотношение изоэффективного анализа. Функция ![]() определяет, как надо увеличивать размер задачи при увеличении числа процессоров для поддержания постоянной эффективности.
определяет, как надо увеличивать размер задачи при увеличении числа процессоров для поддержания постоянной эффективности.
В докладе приведены результаты исследований авторов, посвященные как разработке параллельных алгоритмов решения задачи Коши на основе явных и неявных многоточечных одношаговых методов, так и оценке их эффективности и масштабируемости. Так, для вложенного ![]() -стадийного одношагового метода функция изоэффективности имеет следующий вид:
-стадийного одношагового метода функция изоэффективности имеет следующий вид:
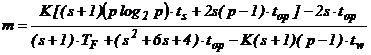 ,
,
где ![]() – время выполнения операции с плавающей точкой,
– время выполнения операции с плавающей точкой, ![]() – латентность,
– латентность, ![]() – время передачи одного слова, что свидетельствует о квазилинейной масштабируемости метода.
– время передачи одного слова, что свидетельствует о квазилинейной масштабируемости метода.
Для MIMD-систем с высокоскоростными каналами связи масштабируемость алгоритма увеличивается, то есть ускорение с ростом числа процессоров становится практически линейным. Пик ускорения достигается при большем числе процессоров, величина максимально возможного ускорения возрастает. Число процессоров, при котором достигается насыщение ускорения, прямопропорционально размерности исходной задачи. Эта тенденция имеет место для параллельных систем произвольной архитектуры, эффективности коммуникационной сети и топологии соединения процессоров. Продемонстрируем влияние на величину функции изоэффективности коэффициента масштабируемости, а, следовательно, и допустимой эффективности, при варьировании числа процессоров и характеристик коммуникационной сети (рис. 1).
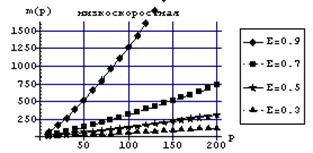
Рисунок 1 – Функция изоэффективности вложенного одношагового метода
Зависимости, приведенные на рис.1., показывают, какой размерности задачу необходимо решать на имеющейся параллельной вычислительной системе, чтобы эффективность использования оборудования достигала определенного значения. Диапазон изменений коэффициента эффективности 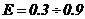 , позволяет исследовать различную загрузку процессоров системы от малой до практически полной.
, позволяет исследовать различную загрузку процессоров системы от малой до практически полной.
Для многоточечных блочных канонических методов и методов «типа Биккарта» получены соответствующие соотношения для определения степени масштабируемости алгоритма по каждому временному терму, в частности, для топологии гиперкуб имеем:
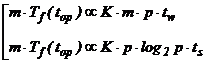 .
.
Применение математического аппарата изоэффективного анализа позволяет не только определить степень масштабируемости одного алгоритма, но и выявить области приоритетного использования различных алгоритмов решения одной и той же задачи. Для этого определяются аналитические выражения для накладных расходов на параллелизм каждого из алгоритмов и приравниваются между собой. Из полученного равенства имеем функцию изоэффективности, зависимость 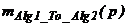 , из которой в конечном итоге и определяется, при каких значениях размерности,
, из которой в конечном итоге и определяется, при каких значениях размерности, ![]() задачи и числа процессоров,
задачи и числа процессоров, ![]() один алгоритм лучше другого, то есть имеет меньшие накладные расходы.
один алгоритм лучше другого, то есть имеет меньшие накладные расходы.
В докладе так же приведены результаты применения теории изоэффективного анализа для неоднородной параллельной вычислительной системы, которая может иметь в своем составе, как процессоры разной продуктивности, так и сетевое оборудование разной пропускной способности [3].
Література
1. Kumar V., Gupta A. Analyzing scalability of parallel algorithms and architectures // Journal of Parallel and Distributed Computing. – v. 22(3). – 1994. – P. 379-391 (2nd edn., 2003).
2. Теория и практика параллельных вычислений. – Москва: Бином. Лаборатория знаний, 2007. – 423с.
3. Kalinov A. Scalability Analysis of Matrix-Matrix Multiplication on Heterogeneous Clusters, Proceedings of 3rd ISPDC/HeteroPar'04, Cork, Ireland, July 05 - 07, 2004, IEEE CS Press, pp. 303-309
