

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция №1.
1. Объект и предмет математической статистики. Признаки.
Математическая статистика (далее МС) имеет свой объект и предмет исследования.
Объектом МС являются так называемые статистические совокупности.
Статистическая совокупность – множество объектов, обладающих некоторым общим свойством, положенным в основу их объединения. Это объединяющее свойство назовем определяющим.
Пример 1: Студенты МГУ.
Студенты – объекты
МГУ – объединяющее свойство.
Пример 2: Школы ЦАО
Школы – объекты
ЦАО – объединяющее свойство
![]()
![]() Объекты
Объекты
Определяющие свойства Общие свойства
Кроме определяющего св-ва объекты статистической совокупности обладают другими свойствами. Те свойства, которые могут заинтересовать исследователя, называются признаками.
Пример 1.
Количественный признак: (студентов МГУ)
·
|
· Вес
· Доход
·
|
· Кол-во друзей
Признаки бывают количественные и качественные.
Качественными являются признаки, которые можно зафиксировать, но нельзя измерить.
Количественные признаки – могут и фиксироваться, и измеряться.
Дискретными называются признаки, которые по своей природе принимают отдельные изолированные значения, в основном целые. (Кол-во друзей, размер обуви)
Непрерывными называются признаки, которые по своей природе принимают значения из некоторого промежутка. (Рост, расстояние, площадь, доход)
Непрерывные признаки имеют иллюзию дискретных, т. е. при измерениях их величины округляют. Но будучи измеренными с большой точностью, значения непрерывных признаков всегда будут отличаться друг от друга.
Предмет МС – методы изучения признаков статистической совокупности.
2. Случайные величины и генеральные совокупности, ассоциированные со статистической совокупностью. Выборка из генеральной совокупности.
Пусть нас интересует признак Х.
Опр. Измеряя значения признака Х у всех объектов статистической совокупности, мы получаем генеральную совокупность ![]() , ассоциированную с данной стат. совокупностью.
, ассоциированную с данной стат. совокупностью.
Объемы стат. совокупности и генеральной совокупности равны и обозначаются N.
Заметим, что значение признака при переходе от одной единицы стат. совокупности к другой, вообще говоря, меняется.
Более того, выбирая произвольно объект стат. сов. Для измерения у него признака Х, мы заранее не знаем, каким будет это значение. Все это говорит о том, что мы имеем дело со случайной величиной Х.
Таким образом в исследовательских целях ген. совокупность Х (множество мощности всех возможных значений признака) ≡ случ. величин. Х.
| |
 | |
| |
|
![]()
|

Это отождествление представляет собой ментальный переход и называется операционализацией. (Переход от абстрактных категорий к конкретным величинам, в отношении которых имеется разработанный мат. аппарат)
Если нас интересует информация о признаках Х у объектов некоторой статистической совокупности, то мы говорим о законе распределения и числовых характеристиках генеральной совокупности Х, а работаем со случайной величиной Х.
Выбрав другой признак У у объектов той же статистической совокупности, мы будем говорить о законе распределения и числовых характеристиках генеральной совокупности У, а работать со случ. величиной У.
Т. о. с каждой стат. совокупностью ассоциированы различные генеральные совокупности (случайные величины по числу признаков).
Истинный, «теоретический» закон распределения генеральной совокупности Х, а так же истинные значения числовых характеристик генеральной совокупности Х и приближенные значения можно получить только в рез-тате сплошного исследования.
На практике сплошное исследование заменяют выборочным. Оно позволяет найти эмпирический закон распределения ге6неральной совокупности Х и приближенные значения числовых характеристик генеральной совокупности Х.
Выборочное исследование начинают со сбора статистических данных.
Статистические данные представляют собой результат серии n независимых наблюдений, в каждом из которых зарегистрировано значение исследуемой случайной величины Х.
То есть в результате «наблюдений» получают n чисел:![]()
![]() – значений, которые случайная величина приняла в данной серии наблюдений.
– значений, которые случайная величина приняла в данной серии наблюдений.
Эти числа![]()
![]() будем считать значениями n одинаково распределенных случайных величин
будем считать значениями n одинаково распределенных случайных величин ![]() , распределенных также, как и исследуемая случайная величина Х.
, распределенных также, как и исследуемая случайная величина Х.
Опр.: Конечную последовательность n независимых одинаково распределенных случайных величин ![]() будем называть выборкой, а указанные числа
будем называть выборкой, а указанные числа ![]()
![]() - реализацией выборки.
- реализацией выборки.
Обрабатывая статистические данные методами описательной статистики, получают практически достоверные сведения о законе распределения и числовых характеристиках всей генеральной совокупности.
3. Этапы работы со статистическими данными.
1) Ранжирование и как результат вариационный ряд.
Выборка ![]()
![]() - неупорядоченный набор чисел.
- неупорядоченный набор чисел.
Упорядочим по неубыванию (не возрас., потому что есть одинаковые значения)
![]()
![]() …
…![]()
Получившуюся последовательность назовем вариационным рядом.
2) Группировка членов В. Р.
2.1) Дискретный статистический ряд.
2.2) Интервальный статистический ряд
Если среди членов в. р. нередко встречаются одинаковые, то группировку осуществляем путем разбиения В. Р. на группы одинаковых значений признака.
Пусть среди n членов В. Р. только R различных, причем некое наименьшее значение ![]() встречается по
встречается по ![]() раз, следующее за ним по величине значение
раз, следующее за ним по величине значение ![]() встречается по
встречается по ![]() раз и так далее.
раз и так далее.
Наконец, значение![]() встречается
встречается ![]() раз, так что
раз, так что
![]()
![]() = n
= n![]()
Таблица «дискретный статистический ряд»
Варианты значений признака |
|
|
| … |
|
Частоты этих вариантов |
|
|
| … |
|
Если среди членов ВР нет или почти нет одинаковых, то проводим группировку ВР путем разбиения (покрытия) диапазона выборки
[ Хmin, Хmax] так называемыми частичными интервалами разбиения.
Ширину частичного ряда h находим по формуле
h ![]()
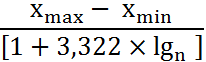 =
=![]() ,
,
где R – размах выборки, К – предполагаемое число частичных интервалов разбиения, [ ] – операция взятия целой части.
Получившееся число![]() округляем.
округляем.
Например, 1,06 ![]() 1 или 4,85
1 или 4,85 ![]()
Округленную величину принимаем за ширину h интервала разбиения.
Далее проводим собственно разбиение
Составляем таблицу – интервальный статистический ряд.
Частичный интервал разбиения |
|
| … |
|
Частота попадания в интервал |
|
| … |
|
Если нашелся член В. Р., значение которого совпадает с границей частичного интервала, то этот член попадает в правый интервал.
4. Дополним статистические ряды строками: расширенные статистические ряды.
· Строкой относительных частот ![]()
· Строкой накопленных частот ![]()
.
