

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
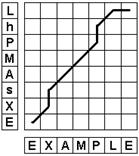 Эта проблема показана на рис.1. Временная матрица используется для визуализации выравнивания.
Эта проблема показана на рис.1. Временная матрица используется для визуализации выравнивания.
На этом рисунке входной сигнал “EXsAMPhL” – это “зашумленная” версия эталона “EXAMPLE”. Идея заключается в том, что «s» - ближайшее совпадение с «X» по сравнению с чем-нибудь ещё в эталоне. Задача состоит в поиске пути, ставящему каждому элементу эталона соответствующий элемент сигнала, и при этом являющегося минимальным с точки зрения расхождения эталона и теста.
Для оптимальности поиска максимального совпадения между эталоном и входным сигналом на путь накладываются ограничения.
· Каждый кадр входного сигнала должен быть использован в процессе сравнения.
·
|
· Пути не могут идти назад во времени (так наз. локальные ограничения).
Классификатор
Задача качественного сравнения двух выровненных во времени последовательностей векторов речевых характеристик может быть приведена к классической задаче классификации. Пусть даны два вектора характеристик С1 и С2 одинаковой длины. Требуется определить, принадлежат ли они одному или разным классам.
В данной работе рассчитывалось суммарное квадратичное отклонение между последовательностями речевых характеристик по каждой компоненте: 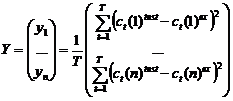 , где
, где ![]() -
- ![]() -й элемент эталонного вектора речевых характеристик в момент времени
-й элемент эталонного вектора речевых характеристик в момент времени ![]() ;
; ![]() -
- ![]() -й элемент тестового вектора речевых характеристик в момент времени
-й элемент тестового вектора речевых характеристик в момент времени 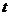 ;
;
Для принятия решения о допуске пользователя или его отклонении сформируем две гипотезы. Первая гипотеза H0 будет обозначать, что величина измеренного отклонения Y принадлежит распределению ![]() , вторая - H1 – что
, вторая - H1 – что 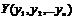 принадлежит распределению
принадлежит распределению ![]() . Та из гипотез, которая будет принята верной, определит соответствующий выбор системы при допуске пользователя.
. Та из гипотез, которая будет принята верной, определит соответствующий выбор системы при допуске пользователя.
На рис. 2 показаны проекции вектора ![]() на плоскости, образованные его 2-й и 3-й компонентами для 240 случаев доступа в систему клиента или злоумышленника.
на плоскости, образованные его 2-й и 3-й компонентами для 240 случаев доступа в систему клиента или злоумышленника.
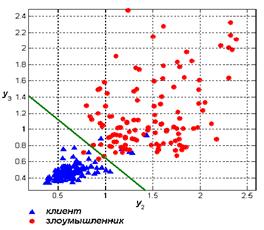 Решение о принадлежности случайного вектора
Решение о принадлежности случайного вектора 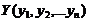 определялось, исходя из знака линейной решающей функции:
определялось, исходя из знака линейной решающей функции: 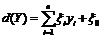 , где
, где ![]() - набор весовых коэффициентов.
- набор весовых коэффициентов.
Аналитический расчет такого рода функций сложен, кроме того, он использует известную плотность распределения и корреляционные коэффициенты между случайными величинами ![]() . Поэтому в данной работе была использована линейная решающая функция, весовые коэффициенты которой вычислялись итеративно с помощью алгоритма SMO (sequential minimal optimization) [3].
. Поэтому в данной работе была использована линейная решающая функция, весовые коэффициенты которой вычислялись итеративно с помощью алгоритма SMO (sequential minimal optimization) [3].
Реализация системы верификации на ПЦОС
![]() Программный код, реализующий функциональность автоматической текстозависимой системы верификации, был разработан с использованием стандарта ANSI C. Это дает возможность портировать его на большинство известных процессором Цифровой Обработки Сигналов.
Программный код, реализующий функциональность автоматической текстозависимой системы верификации, был разработан с использованием стандарта ANSI C. Это дает возможность портировать его на большинство известных процессором Цифровой Обработки Сигналов.
Особенностью данной реализации являлось то, что в ней не использовалось каких-либо специфических возможностей ПЦОС того или иного семейства. Использовались общие способы по оптимизации при написании кода для ПЦОС:
· минимизация использования быстрой оперативной памяти
· использование 16-битных данных
· использование операций над числами в целой точке
· развертка и программная конвейеризация циклов
В таблице 1 представлены сравнительные характеристики DSP процессоров семейств TMS320C64xx и ADSP-BF53x [4]. Таблица 1. Сравнительные характеристики ПЦОС.
ПЦОС | TMS320C64xx | ADSP-BF53x |
Тактовая частота | 400-1000 МГц | 350-750 МГц |
MMACS (16-бит) | 1600-4000 | 700-1500 |
Память программ и данных | 160–2080 кбайт | 52–308 кбайт |
Реализация алгоритма системы автоматической верификации поставляется в виде открытого кода. Для использования алгоритма программист должен следовать следующим соглашениям:
· соглашения на вызов функции алгоритма;
· соглашения на распределение памяти процессора.
В таблице 2 представлено распределение памяти для ПО реализованной системы верификации и требуемая производительность для каждой платформы.
ПЦОС | TMS320C6416 | ADSP-BF535 |
Память данных | 538.2 кбайт | 604.4 кбайт |
Память программ | 6.8 кбайт | 3.4 кбайт |
Время верификации (1 сек речи) | ~120 мс | ~600 мс |
Таблица 2. Распределение памяти и производительность.
Результаты тестирования
Для тестирования исследуемой автоматической системы верификации была использована речевая база данных 20 дикторов. Для регистрации требовалось 5 записей одной и той же парольной фразы. У всех дикторов была одинаковая парольная фраза – слово «Распознавание». Было произведено 200 попыток доступа клиента и 3800 попыток доступа в систему злоумышленника. Результаты опыта приведены в таблицах 3, 4.
Пользователь | Кол-во попыток доступа | Кол-во отказов | Кол-во пропусков |
Клиент | 200 | 2 | 198 |
Злоумышленник | 3800 | 3799 | 1 |
Таблица 3. Результаты тестирования.
Заключение
В результате изучения возможности использования алгоритма ДИВ для временного выравнивания образцов и простейшей дискриминантной фунции для классификации при построении автоматической текстозависимой системы верификации диктора, получены экспериментальные данные, показывающие достаточно высокую эффективность работы. Так, ошибки пропуска/отклонения, равные 0.026/1.00% допустимы при использовании её в системах охраны.
Литература
1. Kuitert. M. and Boves. L. (1997), Speaker verification with GSM coded telephone speech, In Proceedings of the European Conference on Speech Technology. pages 975-978. Rhodes. Л.Р.
2. Rabiner L. Juang B. H.. Fundamentals of Speech Recognition. - N. Y.: Prentice Hall, 1993.
3. S. S. Keerthi, S. K. Shevade, C. Bhattacharyya, K. R.K. Murthy, "Improvements to Platt's SMO Algorithm for SVM Classifier Design". Neural Computation, 13(3), pp 637-649, 2001
4. Процессоры цифровой обработки сигналов компании Texas Instruments Inc. М.: «СКАН», 1999.
¾¾¾¾¾¨¾¾¾¾¾
DEVELOPMENT OF EMBEDDED AUTOMATIC SPEACKER VERIFICATION SYSTEM
Simonchik K.
Saint-Petersburg State Electrotechnical University
Problem of automatic speaker verification system is observed for embedded platforms. Modern algorithms and methods of speech technologies area that used in the low performance and memory conditions are investigated.
The subject of analysis is text-dependent speaker verification system. This determines, first of all, by the wide variety of practice applications:
1. Validity check of access permissions to different information and physical systems (bankers' discount status query by the telephone, information from database).
2. Criminality examination (telephone talk analysis, proofs in the court).
3. Possibility of using in the portative devices (mobile phones, etc.)
In such systems some voice phrases or voice words associated to every client. Usually there are two steps of verification system using. First step consist of client registration when one or several example client voice password phrases are recorded by the system. System uses these audio records for training and creation of the so-called client model. The second step is immediately verification process. User speaks his password phrase and system compares it to corresponding client model and to takes the verification decision: to access or reject user. At the same time user somehow identify itself in order that the system was able to choose the necessary client model for compare.
The basic problems facing the researchers of speech analyses and speech processing are:
· Person individual speech characteristic choice by itself voice.
· Articulation timing warping compensation.
Mel Cepstrum coefficients were used as individual features of user speech. And Dynamic Timing Warping algorithm was used for timing difference compensation between two speech descriptions consecutions.
Special classificatory was used for taking of speech verification decision. Different methods based on Neuron Networks and linear decision functions were investigated. Weight coefficients of linear function were calculated by SMO (sequential minimal optimization) algorithm.
Verification system was developed on ANSI C programming language. This allows to porting program system for different DSP (Texas Instruments and Analog Devices DSP in this work).
Testing results of automatic speaker verification system are listed in the work. They show good quality and competitive capacity of developed system comparing to analogous products.
¾¾¾¾¾¨¾¾¾¾¾

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
