
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Доклад/ Технические науки – Информатика, вычислительная техника и автоматизация
УДК 004.81
определение структуры предметной модели обучаемого на основе учебного текста
Шосткинский институт Сумского Государственного Университета
На сегодняшний день наиболее известными способами представления знаний об обучаемом являются стереотипная и оверлейная модели. Первая используется для адаптации к группам, вторая позволяет полностью индивидуализировать обучение, являясь «функцией усвояемости» на концептном графе предметной области. Зависимость от структуры учебного материала не позволяет сделать ее универсальной для всех систем. Кроме того, если предметная область большая, то ручной способ построения является трудоемким. Т. о. возникает задача автоматизированного способа построения структуры предметной модели обучаемого (оверлейной модели), которую удобнее представить в виде графа.
Так как она основана на учебном материале, можно воспользоваться результатами исследований в области автоматического структурирования массивов текста. Однако обзор литературы [1,2,3] и др. показал, что в общем случае эта проблема пока не имеет однозначного и эффективного решения.
Решение нашей задачи по сравнению с общей облегчено тем, что для обучения обычно предоставляется размеченный текст. Он разделен на разделы и подразделы, выделены основные понятия и упражнения, определено функциональное назначение отдельных фрагментов. Т. о. автоматизированное создание графа предметной области на размеченном текстовом материале выглядит более оптимистично.
Пусть задана нормативная модель обучаемого в виде множества 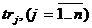 ключевых слов, представляющих требования к знаниям и умениям.
ключевых слов, представляющих требования к знаниям и умениям.
Концептом ![]() назовем неделимый элемент предметной области, предназначенный для изучения обучаемым и оцениваемый системой. Формально концепт можно представить в виде кортежа
назовем неделимый элемент предметной области, предназначенный для изучения обучаемым и оцениваемый системой. Формально концепт можно представить в виде кортежа ![]() , где
, где ![]() - уникальный идентификатор,
- уникальный идентификатор, ![]() - ключевое слово, определяемое концептом (может отсутствовать),
- ключевое слово, определяемое концептом (может отсутствовать), ![]() - список ключевых слов, которые встречаются в тексте концепта.
- список ключевых слов, которые встречаются в тексте концепта.
Пусть учебный текст состоит из множества 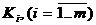 концептов. Воспользуемся логичной упорядоченностью текста и пронумеруем концепты в порядке следования. Построим ориентированный граф
концептов. Воспользуемся логичной упорядоченностью текста и пронумеруем концепты в порядке следования. Построим ориентированный граф ![]() концептов предметной области на основе связи по ключевым словам. Для этого определим множество связей
концептов предметной области на основе связи по ключевым словам. Для этого определим множество связей ![]() .
.
Концепты ![]() и
и ![]() находятся в отношении
находятся в отношении ![]() («для изучения
(«для изучения ![]() необходимо знать
необходимо знать ![]() »), если ключевое слово
»), если ключевое слово ![]() концепта
концепта ![]() находится в списке ключевых слов
находится в списке ключевых слов ![]() концепта
концепта ![]() . В матрице инцидентности таким парам поставим в соответствие значение 1, обратному отношению поставим в соответствие значение -1.
. В матрице инцидентности таким парам поставим в соответствие значение 1, обратному отношению поставим в соответствие значение -1.
Предметная модель обучаемого может быть представлена как функция на множестве связанных концептов. Предоставление индивидуальных фрагментов материала для изучения является одной из главных ее задач. При этом сформированный фрагмент должен быть: 1) тематически связан с некоторым понятием или группой понятий; 2) находиться в зоне ближайшего развития обучаемого; 3) по необходимости дополнен корректирующим материалом.
Для выявления фрагментов (первое условие) воспользуемся идеей «островной кластеризации», предложенным в работе [3] для тематической группировки больших корпусов текстов и сведения их в иерархическую структуру. Модифицируем его следующим образом.
Входные данные: ![]() //Граф концептов и множество ключевых слов
//Граф концептов и множество ключевых слов
Выходные результаты: ![]() // Множество подграфов-островов
// Множество подграфов-островов
Назначим концепты, определяющие ключевые слова, центрами островов.
![]()
{![]() // Назначить концепт центром острова
// Назначить концепт центром острова
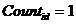 // Посчитать количество концептов острова
// Посчитать количество концептов острова
![]() // Занести идентификатор концепта во множество центров
// Занести идентификатор концепта во множество центров
![]() } // Исключить концепт из множества свободных концептов
} // Исключить концепт из множества свободных концептов
Составим рекурсивную функцию обхода подграфа центра.
Функция ![]()
![]() // Вычислить множество инцидентных концептов
// Вычислить множество инцидентных концептов
Если ![]() , то
, то
{![]()
Если связь ![]() единственна для
единственна для ![]() , то
, то
{![]() // Занести
// Занести ![]() в остров родителя
в остров родителя ![]()
![]() // Увеличить количество концептов острова
// Увеличить количество концептов острова
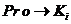 // Удалить
// Удалить ![]() из множества свободных концептов
из множества свободных концептов
![]() } // Применить функцию
} // Применить функцию ![]() к
к ![]()
Если связь ![]() не единственна для
не единственна для ![]() , то
, то
{![]() // Определить множество концептов-родителей для
// Определить множество концептов-родителей для ![]()
![]() // Найти максимальное
// Найти максимальное ![]() для этого множества
для этого множества
![]() // Занести
// Занести ![]() в остров с идентификатором
в остров с идентификатором ![]()
![]() // Увеличить счетчик количества концептов
// Увеличить счетчик количества концептов
} // Удалить ![]() из множества свободных концептов
из множества свободных концептов
} // Конец функции
Отнесем свободные концепты к островам.
![]()
{![]() }
}
Может оказаться так, что некоторые острова будут маленькими. В этом случае следует склеить их с более крупным и подходящим по смыслу островом. Ограничим минимальное количество концептов острова величиной ![]() .
.
![]() , где
, где ![]() // Для всех островов, размеры которых
// Для всех островов, размеры которых ![]()
// Присоединим их к ближайшему острову среди родителей и потомков
{![]() // Вычислить номер ближайшего острова
// Вычислить номер ближайшего острова
![]() // Присоединить текущий остров к найденному соседу
// Присоединить текущий остров к найденному соседу
![]() // Изменить количество концептов
// Изменить количество концептов
![]() } // Удалить
} // Удалить ![]() маленького острова из списка островов
маленького острова из списка островов
В результате получим множество тематических островов, каждый из которых можно считать смысловым фрагментом.
Второе и третье условие обеспечивают индивидуализацию обучения. Они реализуются путем коррекции фрагментов на основании таких параметров модели обучаемого, как уровень знаний, список ошибок, способность к обучению и т. д.
Литература:
1. , , Паничева классификация терминов в русскоязычном корпусе текстов по корпусной лингвистике // Труды 9ой Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции», - RCDL’2007. http://www. dialog-21.ru/dialog2007/
2. Ермаков онтологического инжиниринга в системах извлечения знаний из текста // Компьютерная лингвистика и интеллектуальные технологии: труды Международной конференции Диалог’2008. – Москва, Наука, -2008.
3. Киселев кластеризации текстов, учитывающий совместную встречаемость ключевых терминов, и его применение к анализу тематической структуры новостного потока, а также ее динамики / , , // Интернет-математика 2005. Автоматическая обработка веб-данных, - М. -2005. - с. 412-435.
