
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
3. Обязательные задания для выполнения обучающимися
Обучающийся в обязательном порядке должен выполнить один из примеров, перечисленных ниже:
Пример 1. Построение пространственной модели связи объёма реализации одного из продуктов фирмы от нескольких факторных признаков. Пусть имеются некоторые данные об объеме реализации одного из продуктов фирмы. На основании содержательного анализа составлен перечень показателей, которые предполагается включить в модель, и составлена таблица исходных данных (табл. 1.). Задача решается с помощью методов корреляционного и регрессионного анализа.
1. Необходимо составить матрицу парных коэффициентов корреляции и на ее основе дать рекомендации о включении в модель тех или иных факторов.
Решение. Парные коэффициенты корреляции вычисляются на основе формул (1) и (2):
![]() (1),
(1), ![]() (2).
(2).
Таблица 1.
Объем реализации | Время | Реклама | Цена | Цена кон- курента | Индекс потребит. расходов |
у | х1 | х2 | х3 | х4 | х5 |
126 137 148 191 274 370 432 445 367 367 321 307 331 345 364 384 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 4 4,8 3,8 8,7 8,2 9,7 14,7 18,7 19,8 10,6 8,6 6,5 12,6 6,5 5,8 5,7 | 15,0 14,8 15,2 15,5 15,5 16,0 18,1 13,0 15,8 16,9 16,3 16,1 15,4 15,7 16,0 15,1 | 17,0 17,3 16,8 16,2 16,0 18,0 2,02 15,8 18,2 16,8 17,0 18,3 16,4 16,2 17,7 16,2 | 100,0 98,4 101,2 103,5 104,1 107,0 107,4 108,5 108,3 109,2 110,1 110,7 110,3 111,8 112,3 112,9 |
Для того, чтобы вычислить, например, коэффициент корреляции между х2 и х3, формулы необходимо записать в следующем виде:
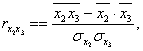
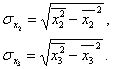
Мы пойдём другим путём. Копируем таблицу в EXCEL.
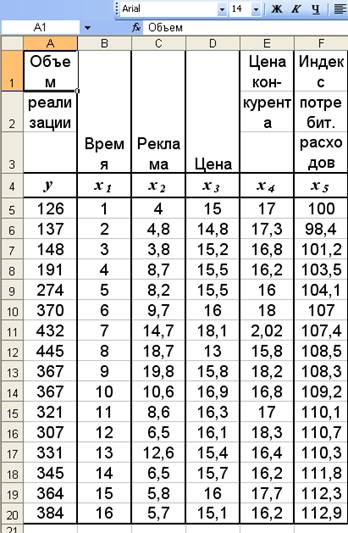
Рис.1. Исходные данные задачи
Воспользуемся надстройкой «Анализ данных» пакета анализа EXCEL.
(см. «EXCEL в науке и практике» с.122.). Команда меню «Данные/ Анализ данных/Корреляция» (рис.2).
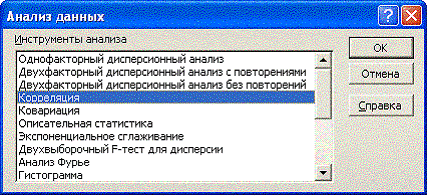
Рис. 2. Меню надстройки «Анализ данных»
В появившемся окне «Корреляция» ввести диапазон данных «у» и все «х» (рис.2.).
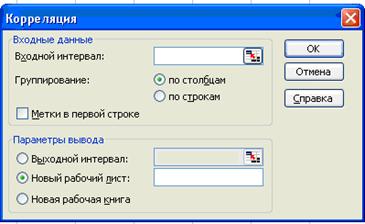
Рис. 3. Окно «Корреляция»
Для этого нужно в окошке входной интервал ввести диапазон данных A4:F20 и так как в сроке A4:F4 текстовые переменные установить птичку в окошке метки в первой строке.

Рис. 3. Окно корреляция с введенным диапазоном данных
Нажать ОК. На новом листе появится матрица парных коэффициентов корреляции (корреляционная матрица). Первый столбец которой указывает на степень корреляционной связи факторов х1-х5 с результативным признаком у. Остальные столбцы указывают на корреляционную зависимость факторов между собой (рис.4.).
у | х1 | х2 | х3 | х4 | х5 | |
у | 1 | |||||
х1 | 0,67798 | 1 | ||||
х2 | 0,64592 | 0,10646 | 1 | |||
х3 | 0,2329 | 0,17372 | -0,0034 | 1 | ||
х4 | -0,3195 | 0,08497 | -0,289 | -0,5183 | 1 | |
х5 | 0,81602 | 0,9602 | 0,27337 | 0,23543 | -0,0027 | 1 |
Рис.4. Матрица парных коэффициентов корреляции
Как видно из рис.4., парный коэффициент корреляции факторов х1-х5 равен 0,96 (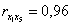 ), что свидетельствует о наличии мультиколлинеарности. Одним из условий регрессионной модели является предположение о линейной независимости объясняющих переменных (факторных признаков), т. е. решение задачи возможно только тогда, когда столбцы и строки исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется мультиколлинеарностью и приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров
), что свидетельствует о наличии мультиколлинеарности. Одним из условий регрессионной модели является предположение о линейной независимости объясняющих переменных (факторных признаков), т. е. решение задачи возможно только тогда, когда столбцы и строки исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется мультиколлинеарностью и приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров
Из этих двух переменных оставим в модели х5 – индекс потребительских доходов, т. к. 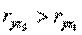 . Да и экономический смысл подсказывает, что в индексе потребительских расходов информации больше, так как он также является функцией времени.
. Да и экономический смысл подсказывает, что в индексе потребительских расходов информации больше, так как он также является функцией времени.
Для этого скопируем табл.1. на новый лист. И на нём удалим столбец с переменной х1. Чтобы удалить столбец с переменной х1 нужно щелкнуть правой кнопкой мыши на названии столбца А и в появившемся меню выбрать – удалить (рис.5.).
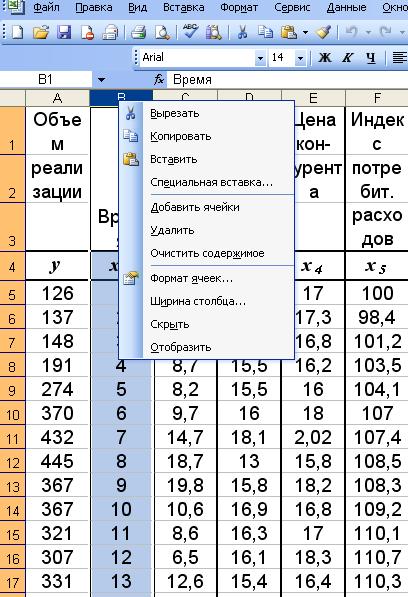
Рис.5. Удаление столбца с фактором х1
Получим табл.2.
Теперь можно преступить к регрессионному анализу. Команда «Данные/Анализ данных/Регрессия». Появится диалоговое окно «Регрессия» в котором нужно ввести входные интервалы х и у и установить птички в окошках «Метки» и «Уровень надёжности 0,95». Установка уровня надёжности 0,95 свидетельствует о выборе уровня значимости 5%.
Таблица 2.
Объем реализации | Реклама | Цена | Цена конкурента | Индекс потребительских расходов |
у | х2 | х3 | х4 | х5 |
126 | 4 | 15 | 17 | 100 |
137 | 4,8 | 14,8 | 17,3 | 98,4 |
148 | 3,8 | 15,2 | 16,8 | 101,2 |
191 | 8,7 | 15,5 | 16,2 | 103,5 |
274 | 8,2 | 15,5 | 16 | 104,1 |
370 | 9,7 | 16 | 18 | 107 |
432 | 14,7 | 18,1 | 2,02 | 107,4 |
445 | 18,7 | 13 | 15,8 | 108,5 |
367 | 19,8 | 15,8 | 18,2 | 108,3 |
367 | 10,6 | 16,9 | 16,8 | 109,2 |
321 | 8,6 | 16,3 | 17 | 110,1 |
307 | 6,5 | 16,1 | 18,3 | 110,7 |
331 | 12,6 | 15,4 | 16,4 | 110,3 |
345 | 6,5 | 15,7 | 16,2 | 111,8 |
364 | 5,8 | 16 | 17,7 | 112,3 |
384 | 5,7 | 15,1 | 16,2 | 112,9 |
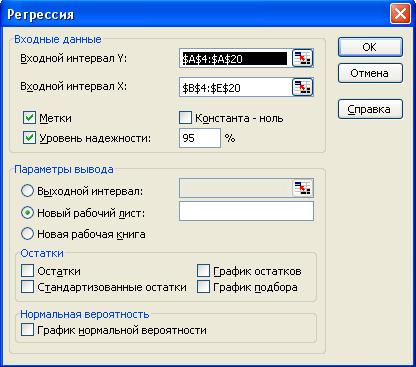
Рис.6. Окно «Регрессия» программы «Анализ данных»
После нажатия ОК, если входные интервалы заданы корректно появится Рис. 7. «Вывод итогов регрессии».
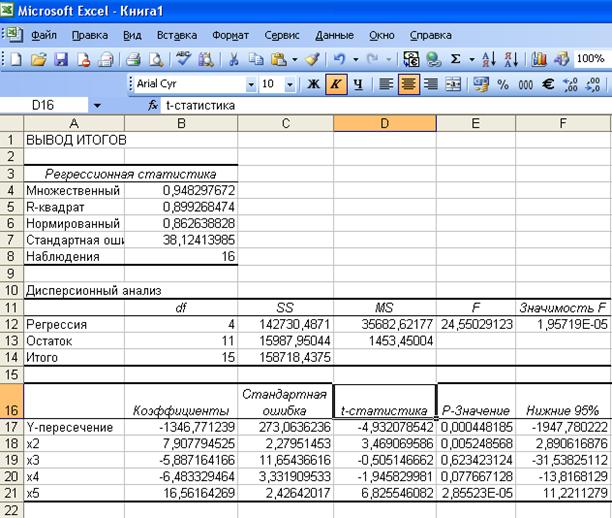
Рис. 7. Вывод итогов регрессии
Как видно из рис.7., полученные итоги характеризуют линейную регрессию вида:
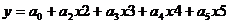
Только, прежде чем воспользоваться полученными результатами, необходимо проверить на значимость значения коэффициентов ![]() , а также проверить на значимость само уравнение регрессии. Проверить на значимость коэффициенты уравнения регрессии означает, что нужно убедиться в том, что значения коэффициентов получены неслучайно и им можно доверять. Другими словами, если коэффициенты уравнения регрессии значимы, то на их основе можно делать прогноз будущих периодов. Осуществляется такая проверка с помощью t-теста Стьюдента. Рассчитывается значение t-статистики и сравнивается с порогом. Как видно из итогов регрессии (рис.7), мы имеем значения соответствующих коэффициентов уравнения регрессии (столбец-коэффициенты), значения t-статистики для каждого коэффициента (столбец t-статистика), значения стандартных ошибок. Нет только пороговых значений для критерия Стьюдента. Их можно найти по таблицам для критерия Стьюдента или же воспользоваться р-значением, которое не должно превышать 0,05 при 5% уровне значимости. Тогда и соответствующий коэффициент будет значим.
, а также проверить на значимость само уравнение регрессии. Проверить на значимость коэффициенты уравнения регрессии означает, что нужно убедиться в том, что значения коэффициентов получены неслучайно и им можно доверять. Другими словами, если коэффициенты уравнения регрессии значимы, то на их основе можно делать прогноз будущих периодов. Осуществляется такая проверка с помощью t-теста Стьюдента. Рассчитывается значение t-статистики и сравнивается с порогом. Как видно из итогов регрессии (рис.7), мы имеем значения соответствующих коэффициентов уравнения регрессии (столбец-коэффициенты), значения t-статистики для каждого коэффициента (столбец t-статистика), значения стандартных ошибок. Нет только пороговых значений для критерия Стьюдента. Их можно найти по таблицам для критерия Стьюдента или же воспользоваться р-значением, которое не должно превышать 0,05 при 5% уровне значимости. Тогда и соответствующий коэффициент будет значим.
После этого нужно провести проверку на значимость выбранного уравнения регрессии. Она осуществляется с помощью F – теста Фишера. Рассчитывается F статистика и сравнивается с порогом. Пороговое значение выбирается по таблицам F распределения Фишера. В программе F, а можно воспользоваться полем «Значимость F». При 5% уровне значимости его значение должно быть меньше 0,05 для того, чтобы выбранное уравнение регрессии было значимым. У нас «Значимость F» =1,96*10-5 т. е. выбранное нами линейное уравнение регрессии значимо.
Таблица3.
Объем реализации | Реклама | Цена конкурента | Индекс потребительских расходов |
у | х2 | х4 | х5 |
126 | 4 | 17 | 100 |
137 | 4,8 | 17,3 | 98,4 |
148 | 3,8 | 16,8 | 101,2 |
191 | 8,7 | 16,2 | 103,5 |
274 | 8,2 | 16 | 104,1 |
370 | 9,7 | 18 | 107 |
432 | 14,7 | 2,02 | 107,4 |
445 | 18,7 | 15,8 | 108,5 |
367 | 19,8 | 18,2 | 108,3 |
367 | 10,6 | 16,8 | 109,2 |
321 | 8,6 | 17 | 110,1 |
307 | 6,5 | 18,3 | 110,7 |
331 | 12,6 | 16,4 | 110,3 |
345 | 6,5 | 16,2 | 111,8 |
364 | 5,8 | 17,7 | 112,3 |
384 | 5,7 | 16,2 | 112,9 |
Из рис.7. видно, что коэффициент а3 при переменной х3 незначим, так как Р-значение=0,62. Следовательно переменную х3 нужно также исключить из модели. Чтобы сохранить промежуточные таблицы, опять копируем табл.2. на лист 3. и удаляем столбец с х3. Получим таблицу 3.
Опять вычисляем регрессию с помощью программы «Анализ данных». Окно программы «Регрессия» будет таким же как на рис.6. только изменится блок ячеек «Входной интервал х». Вывод итогов будет следующим (рис.8).
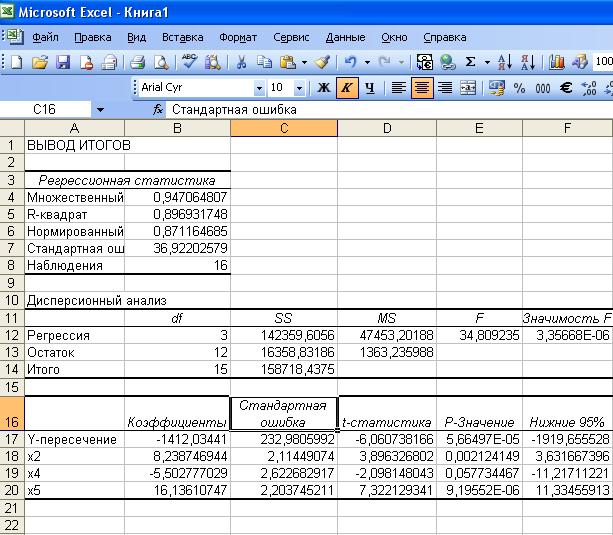
Рис.8. Вывод итогов регрессии
Поскольку а4 всё еще остаётся незначимым, то исключаем х4. Окончательные итоги регрессии приведены на рис.9. Для повышения достоверности полученных результатов, оба теста повторяются с уровнем значимости в 1%. Он устанавливается с помощью уровня надёжности 0,99. В нашем случае коэффициенты уравнения регрессии а2 и а5 , а также само уравнение регрессии будут значимы.
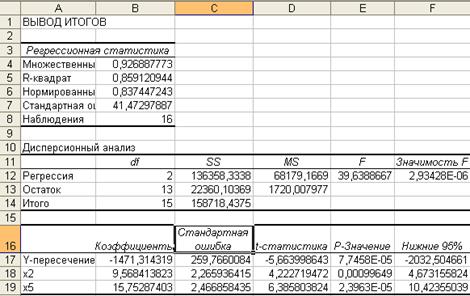
Рис. 9. Вывод итогов регрессии
В результате получим следующую пространственную регрессионную модель.
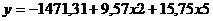
Экономический смысл полученного уравнения регрессии. Если в рекламу вложить миллион рублей, то выручка от реализации продукта увеличится на 9.57 миллионов рублей. Вот почему мы каждый фильм по телевизору смотрим по 3-4 часа. Увеличение индекса потребительских расходов населения на 10% увеличивает выручку от реализации продукта на 1,6 миллиона руб.
По аналогичной методике постройте модель оценки производительности труда по относительным показателям (Пример 3).
Пример 2. Описание объекта
1. В нашем случае объектом исследования являются совокупность фирм, заводов, предприятий. Моделируемым показателем является Y - производительность труда ( тыс. руб / чел ).
2. Экономические показатели (факторы)
Отбор факторов для модели осуществляется в два этапа. На первом идет анализ, по результатам которого исследователь делает вывод о необходимости рассмотрения тех или иных явлений в качестве переменных, определяющих закономерности развития исследуемого процесса, на втором – состав предварительно отобранных факторов уточняется непосредственно по результатам статистического анализа.
Из совокупности экономических показателей мы отобрали следующие :
Зависимый фактор:
У - производительность труда, (тыс. руб.)
Для модели в абсолютных показателях
Независимые факторы:
Х1 - стоимость сырья и материалов ( тыс. руб.)
Х2 - заработная плата ( тыс. руб. )
Х3 - основные промышленно-производственные фонды ( тыс. руб. )
Х4 - отчисления на социальное страхование ( тыс. руб. )
Х5 - расходы на подготовку и освоение производства ( тыс. руб. )
Х6 - расходы на электроэнергию ( тыс. кВт час. )
Данные представлены в таблице 1.
Таблица 1
№ Объекта наблюдения | Y | X1 | X2 | X3 | X4 | X5 | X6 |
1 | 10.6 | 865 | 651 | 2627 | 54 | 165 | 4.2 |
2 | 19.7 | 9571 | 1287 | 9105 | 105 | 829 | 13.3 |
3 | 17.7 | 1334 | 1046 | 3045 | 85 | 400 | 4 |
4 | 17.5 | 6944 | 944 | 2554 | 79 | 312 | 5.6 |
5 | 15.7 | 14397 | 2745 | 15407 | 229 | 1245 | 28.4 |
6 | 11.3 | 4425 | 1084 | 4089 | 92 | 341 | 4.1 |
7 | 14.4 | 4662 | 1260 | 6417 | 105 | 496 | 7.3 |
8 | 9.4 | 2100 | 1212 | 4845 | 101 | 264 | 8.7 |
9 | 11.9 | 1215 | 254 | 923 | 19 | 78 | 1.9 |
10 | 13.9 | 5191 | 1795 | 9602 | 150 | 599 | 13.8 |
11 | 8.9 | 4965 | 2851 | 12542 | 240 | 622 | 12 |
12 | 14.5 | 2067 | 1156 | 6718 | 96 | 461 | 9.2 |
Для модели в относительных показателях
Х1- удельный вес стоимости сырья и материалов в себестоимости продукции
Х2- удельный вес заработной платы в себестоимости продукции
Х3- фондовооруженность одного рабочего, тыс. руб./чел.
Х4- удельный вес отчислений на соц. страхования в себестоимости продукции
Х5- удельный вес расходов на подготовку и освоение производства в себестоимости продукции
Х6- электровооруженность одного рабочего, тыс. кВт./ чел.
Данные представлены в таблице 2.
Таблица 2
№ Объекта наблюдения | Y | X1 | X2 | X3 | X4 | X5 | X6 |
1 | 10.6 | 16,8 | 12,6 | 5,7 | 1,0 | 3,2 | 0,06 |
2 | 19.7 | 33,1 | 4,5 | 8,0 | 0,4 | 2,8 | 0,08 |
3 | 17.7 | 9,9 | 7,7 | 4,6 | 0,6 | 3,0 | 0,08 |
4 | 17.5 | 63,1 | 8,6 | 4,1 | 0,7 | 2,8 | 0,08 |
5 | 15.7 | 32,8 | 6,3 | 8,0 | 0,5 | 2,8 | 0,10 |
6 | 11.3 | 40,3 | 9,9 | 5,2 | 0,8 | 3,1 | 0,08 |
7 | 14.4 | 28,3 | 7,7 | 7,1 | 0,6 | 3,0 | 0,09 |
8 | 9.4 | 25,2 | 14,6 | 7,2 | 1,2 | 3,2 | 0,11 |
9 | 11.9 | 47,3 | 9,9 | 4,5 | 0,7 | 3,0 | 0,13 |
10 | 13.9 | 26,8 | 9,3 | 9,4 | 0,8 | 13,1 | 0,11 |
11 | 8.9 | 25,4 | 14,6 | 6,5 | 1,2 | 3,2 | 0,08 |
12 | 14.5 | 14,2 | 8,0 | 8,5 | 0,7 | 3,2 | 0,13 |
3. Выбор формы представления факторов
В данной работе мы не используем фактор времени, т. е. в нашем случае мы используем статистическую модель. В 1-ом случае мы строим статистическую модель в абсолютных показателях, во 2-м – статистическую модель в относительных показателях. Проанализировав полученные результаты, мы выбираем рабочую статистическую модель.
4. Анализ аномальных явлений
При визуальном просмотре матрицы данных легко улавливается аномалия на пятом объекте в таблице 1,2 . Здесь все факторы завышены в несколько раз. Скорее всего мы сталкиваемся в данном случае с заводом-гигантом . Поэтому данное наблюдение мы отбрасываем. Теперь формируем обновлённую матрицу данных.
Таблица 3
№ Объекта наблюдения | Y | X1 | X2 | X3 | X4 | X5 | X6 |
1 | 10.6 | 865 | 651 | 2627 | 54 | 165 | 4.2 |
2 | 19.7 | 9571 | 1287 | 9105 | 105 | 829 | 13.3 |
3 | 17.7 | 1334 | 1046 | 3045 | 85 | 400 | 4 |
4 | 17.5 | 6944 | 944 | 2554 | 79 | 312 | 5.6 |
6 | 11.3 | 4425 | 1084 | 4089 | 92 | 341 | 4.1 |
7 | 14.4 | 4662 | 1260 | 6417 | 105 | 496 | 7.3 |
8 | 9.4 | 2100 | 1212 | 4845 | 101 | 264 | 8.7 |
9 | 11.9 | 1215 | 254 | 923 | 19 | 78 | 1.9 |
10 | 13.9 | 5191 | 1795 | 9602 | 150 | 599 | 13.8 |
11 | 8.9 | 4965 | 2851 | 12542 | 240 | 622 | 12 |
12 | 14.5 | 2067 | 1156 | 6718 | 96 | 461 | 9.2 |
Таблица 4
№ Объекта наблюдения | Y | X1 | X2 | X3 | X4 | X5 | X6 |
1 | 10.6 | 16,8 | 12,6 | 5,7 | 1,0 | 3,2 | 0,06 |
2 | 19.7 | 33,1 | 4,5 | 8,0 | 0,4 | 2,8 | 0,08 |
3 | 17.7 | 9,9 | 7,7 | 4,6 | 0,6 | 3,0 | 0,08 |
4 | 17.5 | 63,1 | 8,6 | 4,1 | 0,7 | 2,8 | 0,08 |
6 | 11.3 | 40,3 | 9,9 | 5,2 | 0,8 | 3,1 | 0,08 |
7 | 14.4 | 28,3 | 7,7 | 7,1 | 0,6 | 3,0 | 0,09 |
8 | 9.4 | 25,2 | 14,6 | 7,2 | 1,2 | 3,2 | 0,11 |
9 | 11.9 | 47,3 | 9,9 | 4,5 | 0,7 | 3,0 | 0,13 |
10 | 13.9 | 26,8 | 9,3 | 9,4 | 0,8 | 13,1 | 0,11 |
11 | 8.9 | 25,4 | 14,6 | 6,5 | 1,2 | 3,2 | 0,08 |
12 | 14.5 | 14,2 | 8,0 | 8,5 | 0,7 | 3,2 | 0,13 |
4. Анализ матрицы коэффициентов парных корреляций для абсолютных величин
Таблица 5
№ фактора | Y | X1 | X2 | X3 | X4 | X5 | X6 |
Y | 1.00 | 0.52 | -0.22 | -0.06 | -0.23 | 0.44 | 0.12 |
X1 | 0.52 | 1.00 | 0.38 | 0.52 | 0.38 | 0.74 | 0.60 |
X2 | -0.22 | 0.38 | 1.00 | 0.91 | 1.00 | 0.68 | 0.74 |
X3 | -0.06 | 0.52 | 0.91 | 1.00 | 0.91 | 0.86 | 0.91 |
X4 | -0.23 | 0.38 | 1.00 | 0.91 | 1.00 | 0.67 | 0.74 |
X5 | 0.44 | 0.74 | 0.68 | 0.86 | 0.67 | 1.00 | 0.85 |
X6 | 0.12 | 0.60 | 0.74 | 0.91 | 0.74 | 0.85 | 1.00 |
Из таблицы 4 находим тесно коррелирующие факторы. Налицо мультиколлениарность факторов Х2 и Х4 . Оставим только один фактор Х2 . Так же достаточно высокий коэффициент корреляции ( 0.91 ) между факторами Х2 и Х3 . Избавимся от фактора Х3 .
5. Построение уравнения регрессии для абсолютных величин
Проведём многошаговый регрессионный анализ для оставшихся факторов : Х1 , Х2 , Х5 , Х6 .
а) Шаг первый.
Y = 12. 583 + 0 * X1 + 0.043 * X2 + 0.021 * X5 - 0.368 * X6
Коэффициент множественной корреляции = 0.861
Коэффициент множественной детерминации = 0.742
Сумма квадратов остатков = 32.961
t1 = 0.534 *
t2 = 2.487
t5 = 2.458
t6 = 0.960 *
У фактора Х1 t-критерий оказался самым низким. Следовательно фактором Х1 можно пренебречь. Вычеркнем этот фактор.
б) Шаг второй.
Y = 12.677 - 0.012 * X2 + 0.023 * X5 - 0.368 * X6
Коэффициент множественной корреляции = 0.854
Коэффициент множественной детерминации = 0.730
Сумма квадратов остатков = 34.481
t2 = 2.853
t5 = 3.598
t6 = 1.016 *
У фактора Х6 t-критерий оказался самым низким. Следовательно фактором Х6 можно пренебречь. Вычеркнем этот фактор.
в) Шаг третий.
Y = 12.562 - 0.005 * X2 + 0.018 * X5
Коэффициент множественной корреляции = 0.831
Коэффициент множественной детерминации = 0.688
Сумма квадратов остатков = 39.557
t2 = 3.599
t5 = 4.068
В результате трёхшаговой регрессии мы получили рабочее уравнение.
6. Анализ матрицы коэффициентов парных корреляций для относительных величин
Таблица 5
№ фактора | Y | X1 | X2 | X3 | X4 | X5 | X6 |
Y | 1.00 | 0.14 | -0.91 | 0.02 | -0.88 | -0.01 | -0.11 |
X1 | 0.14 | 1.00 | -0.12 | -0.44 | -0.17 | -0.09 | 0.02 |
X2 | -0.91 | -0.12 | 1.00 | -0.12 | 0.98 | -0.01 | -0.38 |
X3 | 0.02 | -0.44 | -0.12 | 1.00 | 0.00 | 0.57 | 0.34 |
X4 | -0.88 | -0.17 | 0.98 | 0.00 | 1.00 | 0.05 | -0.05 |
X5 | -0.01 | -0.09 | -0.01 | 0.57 | 0.05 | 1.00 | 0.25 |
X6 | -0.11 | 0.02 | -0.38 | 0.34 | -0.05 | 0.25 | 1.00 |
В таблице выявляем тесно коррелирующие факторы. Таким образом, не трудно заметить достаточно высокий коэффициент корреляции между факторами Х2 и Х4. Избавимся от Х2
7. Построение уравнения регрессии для относительных величин
а) Шаг первый.
Y = 25,018+0*Х1+
Коэффициент множественной корреляции = 0,894
Коэффициент множественной детерминации = 0.799
Сумма квадратов остатков = 26,420
t1 = 0,012*
t2 = 0,203*
t3 =0.024*
t4 =4.033
t5 = 0.357*
t6 = 0.739 *
У фактора Х1 t-критерий оказался самым низким. Следовательно фактором Х1 можно пренебречь. Вычеркнем этот фактор.
б) Шаг второй.
Y = e ^3.141 * X2^(-0.722) * X5^0.795 * X6^(-0.098)
Коэффициент множественной корреляции = 0.890
Коэффициент множественной детерминации = 0.792
Сумма квадратов остатков = 0.145
t2 = 4.027
t5 = 4.930
t6 = 0.623 *
У фактора Х6 t-критерий оказался самым низким. Следовательно фактором Х6 можно принебречь. Вычеркнем этот фактор.
в) Шаг третий.
Y = e ^3.515 * X2^(-0.768) * X5^0.754
Коэффициент множественной корреляции = 0.884
Коэффициент множественной детерминации = 0.781
Сумма квадратов остатков = 0.153
t2 = 4.027
t5 = 4.930
В результате трёхшаговой регрессии мы получили рабочее уравнение :
Y =
Экономический смысл модели :
При увеличении расходов на подготовку и освоение производства производительность труда будет увеличиваться. Это означает что на данных предприятиях есть резервы для расширения производства, для введения новых технологий и инноваций с целью увеличения прибыли.
При увеличении заработной платы производительность труда будет снижаться. Это, скорее всего , будет происходить из-за того, что рабочие на данных предприятиях получают и так высокие зарплаты, либо фонд заработной платы используется по максимуму и дальнейший его рост приведёт к непредвиденным расходам.
8. Сравнительный анализ линейной и степенной моделей
Сравнивая линейную и степенную регрессионную модель видим, что статистические характеристики степенной модели превосходят аналогичные характеристики линейной модели. А именно : коэффициент множественной детерминации у степенной модели равен 0.781, а у линейной - 0.688 . Это означает, что факторы, вошедшие в степенную модель, объясняют изменение производительности труда на 78.1 %, тогда как факторы, вошедшие в линейную модель, - на 68,8 %; сумма квадратов остатков степенной модели ( 0.153 ) значительно меньше суммы квадратов остатков линейной модели ( 39.557 ). Следовательно значения полученные с помощью степенной модели близки к фактическим.
