


Прогнозный интервал получился достаточно большой, что и следовало ожидать исходя из неудовлетворительной точности линейной модели в данной задаче.
Прогнозирование на основе парных нелинейных моделей, которые заменой переменных сводятся к линейной модели, можно произвести, применив формулы (2.21)-(2.23) к линеаризованному виду нелинейной модели. Если исследуемая переменная не участвовала в заменах переменных, то полученный прогнозный интервал является конечным результатом прогнозирования. Если же мы произвели замену исследуемой переменной, то с помощью обратной замены мы должны будем вычислить прогнозный интервал для исходной исследуемой переменной.
Построим прогноз по данным нашего Примера 1 на основе построенной в п.2.7 парной показательной модели, у которой характеристики точности были выше, чем у линейной. В линеаризованном виде показательную модель можно записать в виде:
![]() .
.
Построим дополнительную вспомогательную таблицу:
Таблица 5
x1 | 5,0 | 10,0 | 15,0 | 20,0 | 25,0 | 30,0 | 35,0 |
z | 0,69 | 1,25 | 1,61 | 2,48 | 3,09 | 3,69 | 3,74 |
zр | 0,71 | 1,26 | 1,81 | 2,37 | 2,92 | 3,47 | 4,02 |
е | -0,013 | -0,006 | -1,203 | 0,120 | 0,173 | 0,217 | -0,287 |
Значение точечного прогноза для переменной z = ln y будет равно:
![]() .
.
Для построения прогнозного интервала вычислим стандартную ошибку линеаризованной модели:
![]() ,
,
а с её использованием размах прогнозного интервала для z:
![]() .
.
Таким образом, мы получаем прогнозный интервал:
![]() .
.
Для определения прогнозного интервала исходной исследуемой переменной применим обратную замену:
![]() .
.
В итоге получим прогнозный интервал для исходной исследуемой переменной с использованием показательной модели:
![]() .
.
Длина интервала получилась меньше, чем длина прогнозного интервала, построенного с использованием линейной модели, чего и следовало ожидать, учитывая лучшие характеристики качества показательной модели по сравнению с линейной.
Однако, величина прогнозного интервала осталась достаточно большой, то есть прогноз остался достаточно грубым. Одним из способов улучшения качества модели, а значит, качества прогнозирования является введение в рассмотрение дополнительных факторных переменных, влияющих на исследуемый признак.
Тема 3. Модель множественной регрессии
Общий вид линейной модели множественной регрессии
Линейная модель множественной регрессии имеет вид:
![]() , (3.1)
, (3.1)
где ![]() - расчётные значения исследуемой переменной,
- расчётные значения исследуемой переменной, ![]() - факторные переменные. Каждый из коэффициентов уравнения
- факторные переменные. Каждый из коэффициентов уравнения ![]() имеет следующую экономическую интерпретацию: он показывает, насколько изменится значение исследуемого признака при изменении соответствующего фактора на 1 при неизменных прочих факторных переменных.
имеет следующую экономическую интерпретацию: он показывает, насколько изменится значение исследуемого признака при изменении соответствующего фактора на 1 при неизменных прочих факторных переменных.
Фактическое значение исследуемой переменной тогда представимо в виде:
![]() (3.2)
(3.2)
Для адекватности модели необходимо, чтобы случайная величина е, являющаяся разностью между фактическими и расчётными значениями, имела нормальный закон распределения с математическим ожиданием равным нулю и постоянной дисперсией у2.
Имея n наборов данных наблюдений, с использованием представления (2.2), мы можем записать n уравнений вида:
![]() , (3.3)
, (3.3)
где ![]() - значения исследуемой и факторных переменных в i-м наблюдении, а еi – отклонение фактического значения yi от расчётного значения yрi, которое может быть рассчитано с помощью (2.1) по значениям факторных переменных
- значения исследуемой и факторных переменных в i-м наблюдении, а еi – отклонение фактического значения yi от расчётного значения yрi, которое может быть рассчитано с помощью (2.1) по значениям факторных переменных ![]() в i-м наблюдении.
в i-м наблюдении.
Систему уравнений (2.3) удобно исследовать в матричном виде:
![]() , (3.4)
, (3.4)
где Yв – вектор выборочных данных наблюдений исследуемой переменной (n элементов), Xв – матрица выборочных данных наблюдений факторных переменных (![]() элементов), А – вектор параметров уравнения (m+1 элементов), а E – вектор случайных отклонений (n элементов):
элементов), А – вектор параметров уравнения (m+1 элементов), а E – вектор случайных отклонений (n элементов):
 (3.5)
(3.5)
Оценка параметров модели с помощью МНК. Отбор факторов
При построении модели множественной регрессии возникает необходимость оценки
(вычисления) коэффициентов линейной функции, которые в матричной форме записи обозначены вектором A. Формулу для вычисления параметров регрессионного уравнения методом наименьших квадратов (МНК) по данным наблюдений приведём без вывода:
![]() . (3.6)
. (3.6)
При m = 1 соотношение (3.6) принимает вид (2.5). Нахождение параметров с помощью соотношения (3.6) возможно лишь тогда, когда между различными столбцами и различными строками матрицы исходных данных X отсутствует строгая линейная зависимость (иначе не существует обратная матрица). Это условие не выполняется, если существует линейная или близкая к ней связь между результатами двух различных наблюдений, или же если такая связь существует между двумя различными факторными переменными. Линейная или близкая к ней связь между факторами называется мультиколлениарностью. Чтобы избавиться от мультиколлениарности, в модель включают один из линейно связанных между собой факторов, причём тот, который в большей степени связан с исследуемой переменной.
На практике чтобы избавиться от мультиколлениарности мы будем проверять для каждой пары факторных переменных выполнение следующих условий:
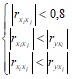 . (3.7)
. (3.7)
То есть коэффициент корреляции между двумя факторными переменными должен быть меньше 0,8 и, одновременно, меньше коэффициентов корреляции между исследуемой переменной и каждой из этих двух факторных переменных. Если хотя бы одно из условий (3.7) не выполняется, то в модель включают только один из этих двух факторов, а именно, тот, у которого модуль коэффициента корреляции с Y больше.
Пример. Будем считать, что торговое предприятие из Примера 1 находится в г. Барнауле, x1 – температура воздуха в г. Барнауле. Дополним данные наблюдений значениями факторной переменной x3 – значениями температуры воздуха в г. Новосибирске в период наблюдений:
Таблица 6
y | x1 | x2 | x3 |
2 | 5,0 | 20 | 4 |
3,5 | 10,0 | 20 | 8 |
5 | 15,0 | 20 | 14 |
12 | 20,0 | 20 | 21 |
22 | 25,0 | 20 | 23 |
40 | 30,0 | 25 | 30 |
42 | 35,0 | 50 | 32 |
Проверим наличие мультиколлениарности между факторными переменными, произведём отбор факторов и найдём параметры линейной модели множественной регрессии. Для нахождения коэффициентов парной корреляции можно воспользоваться формулой (2.1). Поскольку вычисления будут достаточно громоздкими,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
