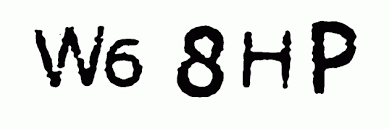Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Курсовая работа
«Сверточные нейронные сети и их применение в распознавании букв на изображении. »
Хромов Михаил, 403 группа
Сверточные нейронные сети
Свёрточная нейронная сеть - специальная архитектура искусственных нейронных сетей, однонаправленная (без обратных связей), принципиально многослойная
В чем отличие от обычной полносвязной нейронной сети?
В обычном перцептроне, который представляет собой полносвязную нейронную сеть, каждый нейрон связан со всеми нейронами предыдущего слоя, причем каждая связь имеет свой персональный весовой коэффициент. В свёрточной нейронной сети в операции свёртки используется лишь ограниченная матрица весов небольшого размера, которую «двигают» по всему обрабатываемому слою (в самом начале — непосредственно по входному изображению), формируя после каждого сдвига сигнал активации для нейрона следующего слоя с аналогичной позицией. То есть для различных нейронов выходного слоя используются одна и та же матрица весов, которую также называют ядром свёртки. Её интерпретируют как графическое кодирование какого-либо признака, например, наличие наклонной линии под определенным углом. Тогда следующий слой, получившийся в результате операции свёртки такой матрицей весов, показывает наличие данного признака в обрабатываемом слое и её координаты, формируя так называемую карту признаков.
Структура сети
Итак, представим, что у нас есть изображение из n*n пикселей. Каждый пиксель – 3 числа (RGB). Первый слой в СНС всегда свёрточный. Берется ядро свертки – обычно это матрица 5х5 и производится операция свертки (поэлементное умножение), получаем на выходе матрицу из (n-4)x(n-4)x3 (так как по 3 числа на каждый пиксель).
Когда картинка проходит через один свёрточный слой, выход первого слоя становится вводным значением 2-го слоя. Сначала вводом были только данные исходного изображения. Но когда мы перешли ко 2-му слою, вводным значением для него стала одна или несколько карт свойств — результат обработки предыдущим слоем.
Чем больше свёрточных слоёв проходит изображение и чем дальше оно движется по сети, тем более сложные характеристики выводятся в картах активации. В конце сети могут быть фильтры, которые активируются при наличии рукописного текста на изображении, при наличии розовых объектов и т. д.
Теперь, когда мы можем обнаружить высокоуровневые свойства, самое крутое — это прикрепление полносвязного слоя в конце сети. Этот слой берёт вводные данные и выводит N-пространственный вектор, где N — число классов, из которых программа выбирает нужный. Например, если мы хотим программу по распознаванию цифр, у N будет значение 10, потому что цифр 10. Каждое число в этом N-пространственном векторе представляет собой вероятность конкретного класса. Например, если результирующий вектор для программы распознавания цифр это [0 0,1 0,1 0,75 0 0 0 0 0,05], значит существует 10% вероятность, что на изображении "1", 10% вероятность, что на изображение "2", 75% вероятность — "3", и 5% вероятность — "9" (конечно, есть и другие способы представить вывод).
Способ, с помощью которого работает полносвязный слой — это обращение к выходу предыдущего слоя (который, как мы помним, должен выводить высокоуровневые карты свойств) и определение свойств, которые больше связаны с определенным классом. Например, если программа предсказывает, что на каком-то изображении собака, у карт свойств, которые отражают высокоуровневые характеристики, такие как лапы или 4 ноги, должны быть высокие значения. Точно так же, если программа распознаёт, что на изображении птица — у неё будут высокие значения в картах свойств, представленных высокоуровневыми характеристиками вроде крыльев или клюва. Полносвязный слой смотрит на то, что функции высокого уровня сильно связаны с определенным классом и имеют определенные веса, так что, когда вы вычисляете произведения весов с предыдущим слоем, то получаете правильные вероятности для различных классов.
Обучение
Метод обратного распространения ошибки можно разделить на 4 отдельных блока: прямое распространение, функцию потери, обратное распространение и обновление веса. Во время прямого распространения, берётся тренировочное изображение — как помните, это матрица N х N х 3 — и пропускается через всю сеть. В первом обучающем примере, так как все веса или значения фильтра были инициализированы случайным образом, выходным значением будет что-то вроде [.1 .1 .1 .1 .1 .1 .1 .1 .1 .1], то есть такое значение, которое не даст предпочтения какому-то определённому числу. Сеть с такими весами не может найти свойства базового уровня и не может обоснованно определить класс изображения. Это ведёт к функции потери. Допустим, первое обучающее изображение — это цифра 3. Ярлыком изображения будет [0 0 0 1 0 0 0 0 0 0]. Функция потери может быть выражена по-разному, но часто используется СКО (среднеквадратическая ошибка), это 1/2 умножить на (реальность — предсказание) в квадрате:
E = ∑1/2(target-output)2
Мы хотим добиться того, чтобы спрогнозированный ярлык (вывод свёрточного слоя) был таким же, как ярлык обучающего изображения (это значит, что сеть сделала верное предположение). Чтобы такого добиться, нам нужно свести к минимуму количество потерь, которое у нас есть. Визуализируя это как задачу оптимизации из математического анализа, нам нужно выяснить, какие входы (веса, в нашем случае) самым непосредственным образом способствовали потерям (или ошибкам) сети. Задача минимизации потерь — отрегулировать веса так, чтобы снизить потерю. Визуально нам нужно приблизиться к самой нижней точке чашеподобного объекта.
Настройки параметров сети
Существующие параметры сети: количество слоев, размерность ядра свёртки для каждого из слоёв, количество ядер для каждого из слоёв, шаг сдвига ядра при обработке слоя, варианты функций потерь, функция по уменьшению размерности (выбор максимума, среднего и т. п.), передаточная функция нейронов, наличие и параметры выходной полносвязной нейросети на выходе свёрточной.
Все эти параметры существенно влияют на результат, но выбираются исследователями эмпирически. Существует несколько выверенных и прекрасно работающих конфигураций сетей, но не хватает рекомендаций, по которым нужно строить сеть для новой задачи.
Компании, которые работают со сверточными нейронными сетями, такие как к примеру, Fine Reader, рассказывают некоторые вещи об устройстве своих сетей, но не раскрывают этих параметров. Примеры настроек можно найти в разных Open Source проектах по распознаванию тех или иных образов на изображении.
Преимущества сверточных нейронных сетей над обычными персептронами
Уменьшение количества обучаемых нейронов, а как следствие, ускорение обучения сети и уменьшение необходимого количества обучающих данных.
Засчет большого количества абстрактных слоев, они обеспечивают частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям.
Удобное распараллеливание вычислений, а, следовательно, возможность реализации алгоритмов работы и обучения сети на графических процессорах.
Недостатки СНС
Слишком много варьируемых параметров сети, непонятно, для какой задачи и вычислительной мощности какие нужны настройки
Применение сверточных нейронных сетей для распознавания текста на изображении
Разработка сверточной нейронной сети
для выделения области расположения символов на изображениях
Для примера возьмем изображения размером 28х44 пикселя. Будет распознавать на них символы.
Входной слой размером 28Ч44 нейронов состоит из 1232 нейронов, не несет какой либо функциональной нагрузки и служит лишь для подачи входного образа в нейронную сеть.
Следом за входным слоем находится первый скрытый слой, который является свёрточным. Этот слой состоит из 6 свёрточных плоскостей. Размер каждой плоскости этого слоя равен 24Ч40=960 нейронов.
Второй скрытый слой является подвыборочным, также состоит из 6 плоскостей, каждая из которых имеет синаптическую маску размером 2Ч2. Размер каждой плоскости этого слоя 12Ч20=240 нейронов, что вдвое меньше, чем размер плоскости предыдущего слоя.
Третий скрытый слой является слоем свёртки. Он состоит из 18 плоскостей размером 16Ч8=128 нейронов.
Четвертый скрытый слой является подвыборочным и состоит из 18 плоскостей размером 4Ч12=48 нейронов.
Пятый скрытый слой состоит из 18 простых сигмоидальных нейронов, по одному на каждую плоскость предыдущего слоя. Роль этого слоя состоит в обеспечении классификации, после того, как выполнено извлечение особенностей и сокращение размерности входа. Каждый нейрон этого слоя полностью связан с каждым нейроном только одной плоскости предыдущего слоя.
Шестой слой является выходным слоем. Он состоит из одного нейрона, который полностью связан со всеми нейронами предыдущего слоя.
В соответствии с решаемой задачей в структуре нейронной сети достаточно одного выхода. Выходное значение нейронной сети находится в интервале [–1; +1], что соответственно означает наличие или отсутствие текста на классифицируемом изображении.
Таким образом, при сканировании входного изображения отклики нейронной сети образуют максимумы в местоположениях областей с текстом. Отклики находятся в диапазоне [–1; +1], в соответствии с выбранной активационной функцией. Размер синаптической маски в сверточных слоях равен 5Ч5 нейронов, в подвыборочных слоях – 2Ч2 нейрона.
Затем идет сегментация найденных областей текста на строки, а строк – на символы. Это в нашем примере будет происходить без участия СНС, а с помощью обычных алгоритмов поиска строк и разбиения на символы с помощью гистограм интенсивности, поэтому пропустим этот этап.
Разработка сверточной нейронной сети
для распознавания символов на изображениях
Для распознавания выделенных символов была разработана сверточная нейронная сеть с 4 скрытыми слоями.
Первый слой является входным и состоит из 28Ч28=841 нейрона.
Второй слой является свёрточным и состоит из шести плоскостей размером 24Ч24=578 нейронов. Третий слой является подвыборочным и также
состоит из 5 плоскостей размером 12Ч12=144 нейронов.
Пятый слой состоит из 126 простых сигмоидальных нейронов. Роль этого слоя – обеспечение классификации, после того, как выполнено извлечение особенностей и сокращение размерности входных данных.
Последний, шестой, слой является выходным слоем и состоит из 43 нейронов (33 букв русского алфавита и 10 цифр).
В качестве активационной функции возьмем гиперболический тангенс.
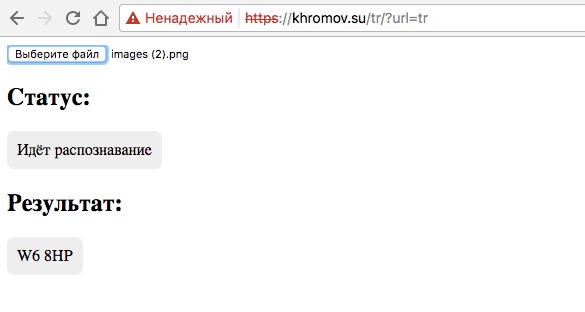
Пример программы, использующий приведенный алгоритм
Программа написана на JavaScript, использующая приведенный выше алгоритм. Доступна с пользовательским интерфейсом по ссылке http:///tr