
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Каждая диаграмма имеет только одну точку входа и одну точку выхода, но сколько угодно вершин других типов. Вершины соединяются между собой направленными дугами графа (линиями со стрелками).
Синтаксические диаграммы для исходной грамматики:
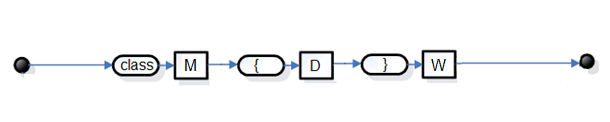
Рис. 1. Синтаксическая диаграмма для S
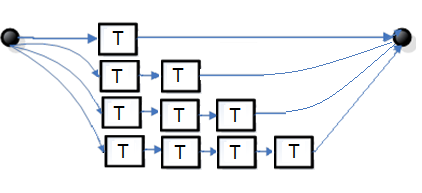
Рис. 2. Синтаксическая диаграмма для D
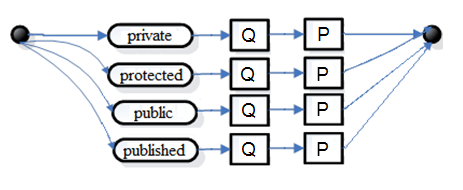
Рис. 3. Синтаксическая диаграмма для T
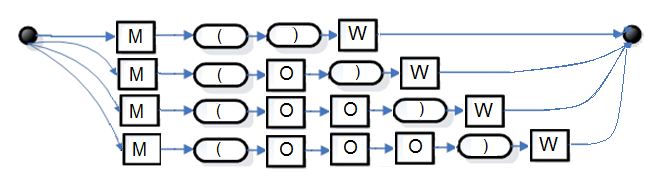
Рис. 4. Синтаксическая диаграмма для P
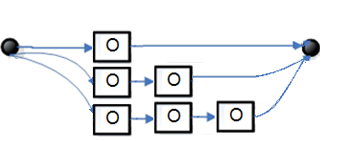
Рис. 5. Синтаксическая диаграмма для P
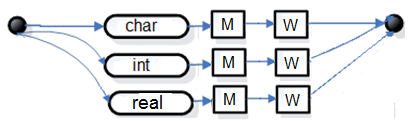
Рис. 6. Синтаксическая диаграмма для O
Рис. 7. Синтаксическая диаграмма для W
![]()
Рис. 8. Синтаксическая диаграмма для Q
Рис. 9. Синтаксическая диаграмма для M
Чтобы построить цепочку символов, соответствующую какому-либо нетерминальному символу грамматики, надо рассмотреть диаграмму для этого символа. Начав движение от точки входа, необходимо двигаться по дугам графа диаграммы через любые вершины вплоть до точки выхода. При этом, проходя через вершину, обозначенную нетерминальным символом, этот символ следует поместить в результирующую цепочку. При прохождении через вершину, обозначенную цепочкой терминальных символов, эти символы также следует поместить в результирующую цепочку. При прохождении через узловые точки диаграммы над результирующей цепочкой никаких действий не выполняется. При попадании в точку выхода диаграммы, построение результирующей цепочки заканчивается.
Результирующая цепочка, в свою очередь, может содержать нетерминальные символы. Чтобы заменить их на цепочки терминальных символов, нужно рассматривать соответствующие им диаграммы до тех пор, пока в цепочке не останутся только терминальные символы. Очевидно, что для того, чтобы построить цепочку символов заданного языка, надо начать рассмотрение с диаграммы со стартового символа грамматики.
9.2. Анализатор для грамматики простого предшествования
Алгоритм синтаксического анализа простого предшествования.
Каждый такт работы анализатора начинается с определения отношения предшествования, которое выполняется для пары, образованной из верхнего символа стека и крайнего левого символа входной строки.
Возможны следующие варианты.
1. Ни одно из отношений не определено. Тогда входная цепочка
отвергается.
2. Для пары символов определено отношение <• или, тогда выполняется перенос.
При переносе анализатор записывает символ <• в стек, если соответствующее отношение выполняется для данной пары, после чего переносит в стек левый символ входной цепочки. Во входной цепочке осуществляется сдвиг (переход) к следующему символу.
3. Для пары определено отношение •>, тогда выполняется свертка.
При выполнении свертки анализатор работает следующим образом.
3.1. Просматривает символы в стеке, пока не обнаружит символ <•. Выделяет подцепочку, состоящую из просмотренных символов (без знака <•). Снимает со стека найденные символы.
3.2. Ищет правило вывода грамматики, правая часть которого совпадает с подцепочкой, выделенной на предыдущем шаге. Если такое правило найдено, то переходят к следующему шагу, иначе – к последнему шагу 4.
3.3. Исключает из стека найденные на первом шаге подцепочку и символ <•. В итоге образуется пара, состоящая из символа на верхушке стека и нетерминального символа из левой части продукции, найденной на шаге 3.2.
3.4. Ищет отношение предшествования, выполняющееся для пары, образованной на предыдущем шаге (это только <• или ). Если ни одно отношение предшествования не выполнено, входная цепочка отвергается.
В противном случае в стек записывается символ <•, если для пары выполнено данное отношение, и символ из левой части продукции. На этом свертка заканчивается.
4. Анализируются цепочки, записанные в стеке и на входной ленте. Если в стеке находится цепочка $ <• S, где S – стартовый символ грамматики, а на входной ленте только маркер конца строки $, то входная цепочка принимается (допускается). В противном случае цепочка отвергается.
9.3. Построение множеств крайних левых и крайних правых символов
Метод предшествования основан на том факте, что отношения предшествования между двумя соседними символами распознаваемой строки соответствуют трем следующим вариантам:
- Bj <• Bi+1, если символ Bi+1 — крайний левый символ некоторой основы (это
отношение между символами можно назвать «предшествует основе» или
просто «предшествует»);
- Bj •> Bi+1, если символ В; — крайний правый символ некоторой основы (это
отношение между символами можно назвать «следует за основой» или просто
«следует»); Bj •= Bi+1, если символы В, и Bi+1 принадлежат одной основе (это отношение
между символами можно назвать «составляют основу»).
На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми (левыми) символами, столбцы — вторыми (правыми) символами отношений предшествования. В клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования.
Матрицу предшествования грамматики сложно построить, опираясь непосредственно на определения отношений предшествования. Удобнее воспользоваться двумя дополнительными множествами — множеством крайних левых и множеством крайних правых символов относительно нетерминальных символов грамматики G(VN, VT, P,S), V = VT![]() VN. Эти множества определяются следующим образом:
VN. Эти множества определяются следующим образом:
- L(A) = {X | 3 A=>*Xz}, AeVN, XeV, zeV* — множество крайних левых симво
лов относительно нетерминального символа А (цепочка z может быть и
пустой цепочкой);
- R(A) = {X | 3 A=>*zX}, AeVN, XeV, zeV* — множество крайних правых
символов относительно нетерминального символа А.
Иными словами, множество крайних левых символов относительно нетерминального символа А — это множество всех крайних левых символов в цепочках, которые могут быть выведены из символа А. Аналогично, множество крайних правых символов относительно нетерминального символа А — это множество всех крайних правых символов в цепочках, которые могут быть выведены из символа А.
Тогда отношения предшествования можно определить так:
![]() , если существует правило
, если существует правило ![]() где
где ![]() ;
;
![]() , если существует правило
, если существует правило ![]() и вывод
и вывод ![]() или существует правило
или существует правило ![]() и выводы
и выводы ![]() , где
, где ![]() ;
;
![]() , если существует правило
, если существует правило ![]() и вывод
и вывод ![]() , где
, где ![]() .
.
Такое определение отношений удобнее на практике, так как не требует построения выводов, а множества L(A) и R(A) могут быть построены для каждого нетерминального символа A![]() VN грамматики G(VN, VT, P,S), V = VT
VN грамматики G(VN, VT, P,S), V = VT![]() VN по очень простому алгоритму.
VN по очень простому алгоритму.
Шаг 1. ![]() A
A![]() VN:
VN:
R0(A) = {X | А->уХ, X![]() V, y
V, y![]() V*},
V*},
L0(A) = {X | A->Xy, X![]() V, y
V, y![]() V}, i := 1.
V}, i := 1.
Для каждого нетерминального символа А ищем все правила, содержащие А в левой части. Во множество L(A) включаем самый левый символ из правой части правил, а во множество R(A) - самый крайний правый символ из правой части.
Переходим к шагу 2.
Шаг 2. ![]() A
A![]() VN:
VN:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
