
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Обозначим через А конечный алфавит, через М множество имен, имеющее мощность не более счетной.
Определение 1. Пара (символ алфавита, имя) называется клеткой и обозначается ![]() . Символ
. Символ ![]() называется состоянием клетки,
называется состоянием клетки, ![]() – именем клетки.
– именем клетки.
Определение 2. Множество клеток ![]() , в котором нет двух клеток с одинаковыми именами, называется клеточным множеством.
, в котором нет двух клеток с одинаковыми именами, называется клеточным множеством.
Определение 3. Конечное клеточное множество W = {![]() ,
, ![]() , …,
, …, ![]() } называется словом.
} называется словом.
Слово можно представить в наглядной геометрической форме, если множество имен M интерпретировать точками пространства. Слово W = {![]() ,
, ![]() ,
, ![]() ,
, ![]() } имеет линейную форму и располагается в одномерной целочисленной решетке. Имена клеток являются координатами узлов этой решетки, а узлы помечены символами алфавита А – состояниями клеток. Слово W = {
} имеет линейную форму и располагается в одномерной целочисленной решетке. Имена клеток являются координатами узлов этой решетки, а узлы помечены символами алфавита А – состояниями клеток. Слово W = {![]() ,
, ![]() ,
, ![]() ,
, ![]() } располагается в двумерной решетке, как показано на рис. 1.
} располагается в двумерной решетке, как показано на рис. 1.
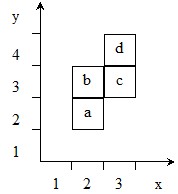
Рис. 1. Пример двумерного слова.
Далее слова будем представлять помещенными в целочисленную прямоугольную решетку размерности n, n = 1, 2, …. Тогда множество имен можно представить в виде M = ![]() , где N = {1, 2, …}.
, где N = {1, 2, …}.
Определение 4. Два слова ![]() и
и ![]() пересекаются, если в них есть одинаковые клетки (с одинаковыми именами и состояниями) и множество
пересекаются, если в них есть одинаковые клетки (с одинаковыми именами и состояниями) и множество ![]() является словом.
является словом.
Определение 5. Два слова ![]() и
и ![]() равны, если для каждой клетки слова
равны, если для каждой клетки слова ![]() найдется точно такая же клетка в слове
найдется точно такая же клетка в слове ![]() и слова
и слова ![]() и
и ![]() состоят из одинакового количества клеток.
состоят из одинакового количества клеток.
Определение 6. Слово ![]() входит в слово
входит в слово ![]() , если для каждой клетки слова
, если для каждой клетки слова ![]() найдется точно такая же клетка в слове
найдется точно такая же клетка в слове ![]() и слово
и слово ![]() состоит из такого количества клеток, что оно меньше или равно количеству клеток в слове
состоит из такого количества клеток, что оно меньше или равно количеству клеток в слове ![]() .
.
Определение 7. Процесс поиска вхождений слова ![]() в слове
в слове ![]() называется сопоставлением. Поиск всех непересекающихся вхождений слова
называется сопоставлением. Поиск всех непересекающихся вхождений слова ![]() в слове
в слове ![]() называется глобальным сопоставлением.
называется глобальным сопоставлением.
Для формулирования задачи сопоставления с двумерным образцом шаблон представим в виде списка клеток в локальной прямоугольной системе координат
V = {![]() ,
, ![]() , …,
, …, ![]() }, где
}, где ![]() (i =
(i = ![]() ), обрабатываемое слово представим перечислением
), обрабатываемое слово представим перечислением ![]() клеток прямоугольной матрицы
клеток прямоугольной матрицы
W = { ![]() ,
, ![]() , …,
, …, ![]() ,
,
![]() ,
, ![]() , …,
, …, ![]() ,
,
….,
![]() ,
, ![]() , …,
, …, ![]() }, где
}, где ![]() (i =
(i = ![]() , j =
, j = ![]() ).
).
Задача сопоставления образца V и слова W состоит в поиске двухкоординатных позиций вхождения V в слово W.
Будем называть буквы ![]() образца V, координаты
образца V, координаты ![]() которых равны, столбцом образца, буквы
которых равны, столбцом образца, буквы ![]() образца V, координаты
образца V, координаты ![]() которых равны, строкой.
которых равны, строкой.
Обозначим через m – максимальный индекс столбца образца, через n – максимальный индекс строки образца, количество букв образца в j-й строке через ![]() , количество букв образца в i-м столбце через
, количество букв образца в i-м столбце через ![]() , максимальный индекс буквы образца в j-й строке через
, максимальный индекс буквы образца в j-й строке через ![]() , минимальный индекс в j-й строке через
, минимальный индекс в j-й строке через ![]() , максимальный индекс буквы образца в i-ом столбце через
, максимальный индекс буквы образца в i-ом столбце через ![]() , минимальный индекс в i-м столбце через
, минимальный индекс в i-м столбце через ![]() .
.
Введенные обозначения рассмотрим для образца V = {![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() }, изображенного на рис. 2.
}, изображенного на рис. 2.
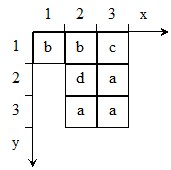
Рис. 2. Пример двумерного образца V в локальной
прямоугольной системе координат
Для двумерного образца V: n = 3, m = 3, ![]() =3,
=3, ![]() =2,
=2, ![]() =2,
=2, ![]() =1,
=1, ![]() =3,
=3, ![]() =3,
=3, ![]() =1,
=1, ![]() =3,
=3, ![]() =2,
=2, ![]() =3,
=3, ![]() =2,
=2, ![]() =3,
=3, ![]() =1,
=1, ![]() =1,
=1, ![]() =1,
=1, ![]() =3,
=3, ![]() =1,
=1, ![]() =3.
=3.
Также мы будем полагать, что существует способ получения буквы образца (обрабатываемого слова) по координатам x, y, и будем рассматривать образцы, столбцы (строки) которых представляют собой слова, не содержащие пробелов.
2. ПРЯМОЙ ПОДХОД К СОПОСТАВЛЕНИЮ
Поиск вхождения двумерного образца начинается с сопоставления обрабатываемого слова с 1-й строкой образца. При успешном результате сопоставления необходимо сопоставить 2-ю строку образца с соответствующей подстрокой следующей строки обрабатываемого слова и т. д., пока не будут успешно сопоставлены все строки образца или не будет достигнут конец строки обрабатываемого слова. При обнаружении отвергающего символа (символ образца называется отвергающим, если в процессе сопоставления он не совпал с очередным символом обрабатываемого слова; с тем же основанием отвергающим называется и соответствующий символ обрабатываемого слова) процесс сопоставления с двумерным образцом снова начинается с поиска вхождения 1-й строки образца в позиции на единицу большей позиции обнаружения частичного вхождения. Если вхождение образца при просмотре слова слева направо обнаружить не удалось, выполняется поиск вхождения образца со следующей строки слова и т. д., пока не будет обнаружено вхождение или не будет достигнута последняя строка обрабатываемого слова.
При каждой новой итерации построчного сопоставления образца с соответствующими буквами обрабатываемого слова сравниваются не более ![]() символов, так что суммарное количество проверок при сканировании образца в горизонтальном направлении относительно одной фиксированной строки обрабатываемого слова не превосходит
символов, так что суммарное количество проверок при сканировании образца в горизонтальном направлении относительно одной фиксированной строки обрабатываемого слова не превосходит ![]() . Тогда общее количество проверок при сканировании образца в горизонтальном направлении по всем строкам обрабатываемого слова не превосходит
. Тогда общее количество проверок при сканировании образца в горизонтальном направлении по всем строкам обрабатываемого слова не превосходит ![]() . Количество сравнений максимально, когда отвергающим символом является буква образца с координатами
. Количество сравнений максимально, когда отвергающим символом является буква образца с координатами ![]() .
.
Однако на практике подобные ситуации встречаются редко. Средняя эффективность равна ![]() , так как отвергающие символы, как правило, приходятся не на последнюю букву последней строки образца, а гораздо раньше. Очевидно, что реальная эффективность прямого подхода к сопоставлению зависит от реальных свойств – как двумерного образца, так и обрабатываемого слова.
, так как отвергающие символы, как правило, приходятся не на последнюю букву последней строки образца, а гораздо раньше. Очевидно, что реальная эффективность прямого подхода к сопоставлению зависит от реальных свойств – как двумерного образца, так и обрабатываемого слова.
Алгоритм, реализующий прямой подход, приведен на рис. 3.
j := 1;
t := 1;
sb := 0;
tb := 0;
while ( (tb <= r – n) и (sb <= p - m) ) {
while ((sb <= p - m) и (j <= n) ) {
i = Xminj;
s = sb + i
while ( i <= Xmaxj ) {
if (A(i, j) == B(s, t) ) {
i := i + 1;
s := s + 1;
} else { // несовпадение
sb := sb + 1;
j := 1;
continue 2; // Продолжаем внешний цикл
}
}
j := j + 1;
t := t + 1;
}
if (j > n) { // проверка успешности сопоставления
// Область вхождения (sb+1, tb+1)-(sb+1+m, tb+1+n)
break;
}
j := 1;
sb := 0;
tb := tb + 1;
}
достижении
Прежде чем перейти к рассмотрению
В предлагаемом алгоритме образец движется вдоль прямоугольной матрицы обрабатываемого слова слева направо до ее правой границы, однако фактическое сравнение символов выполняется начиная с букв самого правого столбца образца. При успешном сопоставлении букв образца самого правого столбца в порядке снизу вверх выполняется сопоставление предыдущего столбца снизу вверх и т. д. При достижении правой границы обрабатываемого слова процесс сканирования рестартует с левой границы слова и со смещением на одну строку вниз.
Первыми таким образом сравниваются символы A(m, ![]() ) и B(s+m, t+
) и B(s+m, t+![]() ). Если они не совпадают и B(s+m, t+
). Если они не совпадают и B(s+m, t+![]() ) не встречается среди букв
) не встречается среди букв ![]() строки образца, то можно сдвинуть образец по горизонтали на (
строки образца, то можно сдвинуть образец по горизонтали на (![]() -
-![]() ) позиций вправо, т. к. можно быть уверенным, что ни одна из начинающихся с одной из первых (
) позиций вправо, т. к. можно быть уверенным, что ни одна из начинающихся с одной из первых (![]() -
-![]() ) позиций подстрок (t+
) позиций подстрок (t+![]() ) строки обрабатываемого слова не совпадает с
) строки обрабатываемого слова не совпадает с ![]() строкой образца.
строкой образца.
Следующими сравниваются A(m, ![]() ) и B(s+fm+m, t+
) и B(s+fm+m, t+![]() ).
).
При обнаружении отвергающих символов A(m, j), где ![]() <= j <=
<= j <= ![]() и B(s+m, t+j), и при отсутствии среди букв j строки образца буквы B(s+m, t+j), образец сдвигается по горизонтали на
и B(s+m, t+j), и при отсутствии среди букв j строки образца буквы B(s+m, t+j), образец сдвигается по горизонтали на ![]() позиций вправо.
позиций вправо.
Пусть отвергающими оказались символы A(m, ![]() ) и B(k, l). Как уже говорилось, если B(k, l) не содержится нигде в
) и B(k, l). Как уже говорилось, если B(k, l) не содержится нигде в ![]() строке образца, шаблон можно сдвинуть на f
строке образца, шаблон можно сдвинуть на f![]() позиций вправо. С другой стороны, если B(k, l) присутствует в образце, и A(m-v,
позиций вправо. С другой стороны, если B(k, l) присутствует в образце, и A(m-v, ![]() ) – его самое правое вхождение в
) – его самое правое вхождение в ![]() строке, то образец можно сдвинуть лишь на v позиций вправо, совмещая A(m-v,
строке, то образец можно сдвинуть лишь на v позиций вправо, совмещая A(m-v, ![]() ) с B(k, l). Поиск можно продолжить сравнением A(m,
) с B(k, l). Поиск можно продолжить сравнением A(m, ![]() ) с B(k+v, l), то есть индекс отвечающий за движение в горизонтальном направлении по обрабатываемому слову увеличиваем на v.
) с B(k+v, l), то есть индекс отвечающий за движение в горизонтальном направлении по обрабатываемому слову увеличиваем на v.
Если A(m, ![]() ) и B(k, l) совпадают, нужно сравнивать все символы в m столбце образца и с соответствующими символами k столбца обрабатываемого слова, пока весь подстолбец обрабатываемого слова не будет сопоставлен со столбцом образца или пока не встретится несовпадение. Когда вхождение m столбца будет определено, необходимо перейти к сопоставлению m-1 столбца образца с соответствующими символами k-1 столбца обрабатываемого слова и т. д.
) и B(k, l) совпадают, нужно сравнивать все символы в m столбце образца и с соответствующими символами k столбца обрабатываемого слова, пока весь подстолбец обрабатываемого слова не будет сопоставлен со столбцом образца или пока не встретится несовпадение. Когда вхождение m столбца будет определено, необходимо перейти к сопоставлению m-1 столбца образца с соответствующими символами k-1 столбца обрабатываемого слова и т. д.
Если отвергающим оказался, скажем, символ A(i, j), то мы знаем, что суффикс j-й строки образца A(i+1,j)… A(Xmaxj, j) равен подстроке обрабатываемого слова B(k - Xmaxj +i+1, l)… B(k, l), и A(i, j) не равен B(k - Xmaxj +i, l). Теперь, если самым правым вхождением B(k - Xmaxj +i, l) в j строку образца снова является, скажем, A(Xmaxj - v, j), образец можно сдвинуть по горизонтали на i - Xmaxj +v символов вправо, так что A(Xmaxj - v, j) окажется на одной позиции с B(k - Xmaxj +i, l). Процедуру поиска следует продолжить сравнением A(m, ![]() ) с соответствующим символом, в данном случае с B(k + i - Xmaxj +v, l). Приращение индекса отвечающего за движение в горизонтальном направлении по обрабатываемому слову с позиции несовпадения до следующей пробной позиции равно, таким образом, (k + i - Xmaxj +v)-( k - Xmaxj +i) = v. Заметим, что приращение тоже, что и в случае обнаружения отвергающего символа в самом правом столбце образца.
) с соответствующим символом, в данном случае с B(k + i - Xmaxj +v, l). Приращение индекса отвечающего за движение в горизонтальном направлении по обрабатываемому слову с позиции несовпадения до следующей пробной позиции равно, таким образом, (k + i - Xmaxj +v)-( k - Xmaxj +i) = v. Заметим, что приращение тоже, что и в случае обнаружения отвергающего символа в самом правом столбце образца.
Если A(Xmaxj - v, j) находится правее A(i, j), то значение i - Xmaxj +v отрицательно и совмещение A(Xmaxj - v, j) с B(k + i - Xmaxj +v, l) оказывается излишним, поскольку повлечет за собой шаг назад. В этих обстоятельствах образец лучше сдвинуть на одно место вправо и сравнивать A(m, ![]() ) с B(k+1, l). Для этого следует увеличить индекс отвечающий за движение в горизонтальном направлении по обрабатываемому слову на (k+1)-( k - Xmaxj +i) = Xmaxj +1-i.
) с B(k+1, l). Для этого следует увеличить индекс отвечающий за движение в горизонтальном направлении по обрабатываемому слову на (k+1)-( k - Xmaxj +i) = Xmaxj +1-i.
Приращения v, используемые для перемещения по обрабатываемому слову в горизонтальном направлении, вычисляются заранее для каждой строки образца отдельно и хранятся в таблицах delta[n]. В процессе поиска доступ к таблице j строке образца delta[j] осуществляется по отвергающим символам обрабатываемого слова, поэтому размер каждой таблицы равен мощности используемого алфавит символов.
При формировании таблицы delta[j] вход для символа w равен fj-i, где A(i, j) – самое правое вхождение w в j строку образца, и равен fj, если w не содержится в j строке образца, то есть:
delta[j][w] = min {v : v = fj или (0 <=v < fj и A(Xmaxj-v, j) = w)}
Таблица delta[j] для алфавита ОМЕГА инициализируется следующим образом:
for j = 1 to n do
for w = 1 to ОМЕГА
delta[j][w] = fj
for j = 1 to n do
for i = Xminj to Xmaxj
delta[j][A(i, j)] = Xmaxj – i
Отсюда видно, что время инициализации n таблиц delta равно O(n(ОМЕГА+fj)).
Проиллюстрируем работу одной таблицы delta для строки образца x = ABCDB.
w A B C D E F G H...
delta[w] 4 0 2 1 5 5 5 5 ...
Несовпадение возникает при yi = A
x - образец A B C D B
y - текст. . . L M N A B C D B. . .
i
Следующими сравниваются символы xm и yi+skip[A], то есть yi+4.
образец A B C D B
текст . . . L M N A B C D B. . .
i i+4
Ниже приведен алгоритм сопоставления двумерного образца с прямоугольной матрицей символов – обрабатываемое слово.
i = m;
s = m;
tb := 0; // Глоб. индекс смещения в верт. направлении по обрабатываемому слову
while ( tb <= r - n ) {
while ( (s >0) и (i > 0) и (s <= p) ) {
j = Ymaxi;
t = tb + j
// сканирование i столбца образца в направлении снизу вверх
while ( (t > 0) и (j >= Ymini) ) {
if (A(i, j) == B(s, t) ) {
j: = j – 1;
t:= t – 1;
} else { // несовпадение
if (i > delta[j][B(s, t)] ) {
s := fj+1-i;
} else {
s := s + delta[j][B(s, t)];
}
i = m;
continue 2; // Продолжаем внешний цикл
}
}
// Переход к сканированию предыдущего столбца образца
i := i –1;
s := s – 1;
}
if ( i < 1 ) { // Проверка успешности сопоставления
// Область вхождения (s+1, tb+1)-(s+1+m, tb+1+n)
break;
}
// Переход к следующей строке сканирования обрабатываемого слова
i := m;
s := m;
tb := tb + 1;
}
