


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК: 007.52; 519.816; 681.3.016
ПРЕДСКАЗАНИЕ НЕИЗВЕСТНЫХ ЗНАЧЕНИЙ НЕПРЕРЫВНЫХ АТРИБУТОВ В БАЗАХ ДАННЫХ*
2
Рассматривается проблема идентификации объектов с учетом случайных помех двух типов, информация о которых хранится в реальных массивах данных. Приводится модель представления данных, учитывающая изменение информации во времени, и алгоритм процедуры для предсказания пропущенных данных. Представлены результаты программного моделирования.
Введение
В докладе продолжается обсуждение проблемы обобщения объектов с учетом необходимости обработки информации, хранящейся в реальных массивах данных, которые могут содержать шум [Бериша, 2005], актуальной в системах автоматического обнаружения знаний в базах данных, логическом выводе, используемых в интеллектуальных системах выявления закономерностей и принятия решений.
С проблемой предсказания отсутствующих (потерянных) и/или искаженных данных, распознавания новых данных автор столкнулся при обработке реальных массивов, связанных с химическим и минералогическим составом торфов [Инишева и др., 1997a; Инишева и др., 1997b]
В работе [Бериша, 2005] излагаются методы обнаружения знаний, использование которых частично позволяет решать задачу обобщения объектов в условиях определенных ограничений (например, независимости признаков, описывающих объект, или дискретности значений признаков).
В данной работе рассматривается случай признаков с непрерывными значениями, и обсуждается вопрос об оценке пропущенных данных.
1. Основные определения и понятия
В общих чертах задача распознавания состоит в следующем.
Исследуется некоторое множество объектов O={O1,..., On}, которые могут быть представлены в интеллектуальной системе (точнее, в базе данных (БД) интеллектуальной системы как ее составной части). Каждый объект характеризуется r признаками: z1, z2, ..., zr (в терминах базы данных − атрибутами) и соответствующими доменами (множествами допустимых значений признаков) D(z1), D(z2), ..., D(zr).
Отметим, что в задаче распознавания O представимо в виде объединения K подмножеств S1, …, SK, называемых классами (класс − совокупность (семейство) объектов, обладающих общими свойствами). Входящие в один тот же класс объекты считаются неразличимыми (эквивалентными), а каждый класс объектов характеризуется некоторым качеством, отличающим его от других классов. Вместе все классы должны составлять исходную совокупность объектов.
Имеется конечный набор O1,..., On объектов из O, о которых известно, каким классам они принадлежат. Это прецеденты или обучающие объекты. Пусть их описания имеют вид q1= (q11, …, q1M ) , q2= (q21, …, q2M) , …, qn = (qn1, …, qnM ) , здесь qij - значение признака Аj для объекта Oi. Требуется по предъявленному набору значений признаков (b1, …, bn), описывающему некоторый объект из O, о котором, вообще говоря, неизвестно какому классу он принадлежит, определить этот класс.
Информация о свойствах объекта может быть получена путем наблюдений, измерений, оценок и т. п. и представлена совокупностью признаков, значения которых выражаются в числовых и/или вербальных шкалах.
С точки зрения поиска закономерностей использование базы данных в качестве обучающего множества вызывает определенные трудности [Бериша, 2005; Буров, 1999], среди которых наиболее важными являются следующие: недостаточность доступной информации, необходимой для определения класса объекта; частичное отсутствие информации, ее «зашумленность» в некотором смысле и/или изменение информации во времени (например, стоимость акции, товара, значение химического (минералогического) состава исследуемого образца [Инишева и др., 1997a; Инишева и др., 1997b] и т. д.); объем данных (примеров объектов) достаточно велик и растет, причем некоторые удачные в прошлом объекты теряют свое качество от времени из-за постоянного развития технологий; процесс оценки и ранжирования объектов занимает достаточно существенное время.
2. Постановка задачи
Пусть по базе данных как по обучающему множеству выделены классы. Требуется оценить отсутствующие значения признаков в выделенных K классах. При этом, не исключается возможность того, что размерность признакового пространства достаточно велика, а значения признаков могут зависеть от времени.
3. Модель представления непрерывных признаков
Будем предполагать, что обрабатываемые атрибуты имеют непрерывные значения (вообще говоря, случайные). Рассмотрим проблему использования объектов обучающей выборки для нахождения общих свойств выделенных K классов и использования этих свойств а) для предсказания неизвестных и/или потерянных значений; б) для распознавания объектов, не входящих в обучающую выборку.
Предположим, что в качестве математической модели значений атрибута x объектов одного класса Si рассматривается линейная авторегрессия со случайными коэффициентами [Кашковский, 2006], описываемая уравнениями
![]() , (3.1)
, (3.1)
где ![]() ,
, ![]() − независимые последовательности независимых одинаково распределенных случайных величин с нулевым средним и единичной дисперсией, k − номер временного интервала (номер «замера» значения признака, номер объекта внутри одного класса) (k=1, 2, …),
− независимые последовательности независимых одинаково распределенных случайных величин с нулевым средним и единичной дисперсией, k − номер временного интервала (номер «замера» значения признака, номер объекта внутри одного класса) (k=1, 2, …), ![]() − постоянные неотрицательные параметры.
− постоянные неотрицательные параметры.
Требуется оценить по наблюдениям признака ![]() вектор параметров
вектор параметров ![]() (штрих означает транспонирование).
(штрих означает транспонирование).
Прежде чем сформулировать основные результаты, прокомментируем данное представление значений атрибута x хранящихся в БД объектов (информации о них).
Модели авторегрессии, используемые для предсказания будущих значений наблюдаемого ряда по настоящим и прошлым значениям, позволяют не только интерпретировать рассматриваемые данные (например, сезонное изменение цен на товары, временное изменение химического состава исследуемых образцов, взятых с одного места (географического)), но и экстраполировать затем ряд на основе найденной модели, т. е. предсказать его будущие значения (отсутствующие для очередного добавленного в класс объекта по какой-либо причине (дороговизна анализа или его невозможность)). Параметр авторегрессии p может означать «глубину предыстории» для анализируемого признака и является, вообще говоря, параметром оптимизации в некотором смысле.
Особенностью такого представления признака является учет его изменения во времени, т. к. в действительности признаки могут быть подвержены действию случайных возмущений и оставаться постоянными только в среднем. Отметим, что модель (3.1) допускает «шумы» двоякой природы без предположения их гауссовости.
Вектор оцениваемых параметров ![]() по сути отражает специфику класса Si. Сформулируем основные результаты.
по сути отражает специфику класса Si. Сформулируем основные результаты.
Представление наблюдений признака ![]() (3.1) равносильно следующему:
(3.1) равносильно следующему: ![]() , где
, где ![]() ,
, ![]() .
.
Введем дополнительные обозначения: ![]() ,
, 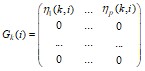 ,
, ![]() , где
, где ![]() − единичная матрица порядка (p−1).
− единичная матрица порядка (p−1).
Теорема. Если уравнение (3.1) имеет стационарное решение, то последовательная оценка по методу наименьших квадратов ![]() сходится в среднеквадратическом к истинному значению вектора параметров
сходится в среднеквадратическом к истинному значению вектора параметров ![]() , а верхняя граница среднеквадратической точности вектора оценки
, а верхняя граница среднеквадратической точности вектора оценки ![]() обратно пропорциональна длительности наблюдений.
обратно пропорциональна длительности наблюдений.
Доказательство теоремы опирается на результаты, полученные в работе [Кашковский, 2006].
Отметим, что при ![]() уравнение (3.1) имеет стационарное решение, если
уравнение (3.1) имеет стационарное решение, если
Алгоритм процедуры получения оценки неизвестного значения признака (атрибута)
Задаем пороговое значение h. Вычисляем момент остановки наблюдений признака x,![]()
где ![]() ,
, ![]() , величина
, величина ![]() удовлетворяет уравнению
удовлетворяет уравнению ![]() .
.
![]()
4. Иллюстративный пример
Рассмотрим пример, где представлены численные значения оценок вектора параметров ![]() , полученных в результате работы последовательной процедуры, основанной на методе наименьших квадратов, а также выборочные значения основных характеристик: h − количество наблюдений, τh − среднее вSd(θ*) − количества наблюденийh (табл.4.1).
, полученных в результате работы последовательной процедуры, основанной на методе наименьших квадратов, а также выборочные значения основных характеристик: h − количество наблюдений, τh − среднее вSd(θ*) − количества наблюденийh (табл.4.1).
Для изучения свойств предложенной процедуры моделировался процесс (3.1) второго порядка
![]() .
.
Таблица 4.1. Выборочные характеристики процедуры
а1 | а2 | h | τh | Sd(θ*) | Sd |
0.1 | 0.5 | 50 | 53.04 | 0.161 | 0.263 |
-0.45 | 0 | 200 | 271.9 | 0.053 | 0.086 |
0.3 | 0.3 | 200 | 273.2 | 0.081 | 0.202 |
Заключение и дальнейшее развитие
Для построения процедуры получения оценки неизвестного значения признака (атрибута) объектов, информация о которых хранится в базе данных, предложена процедура, не требующая жестких ограничений на распределения шумов (таких как требование гауссовости).
Было проведено экспериментальное исследование предложенных процедур оценивания и классификации, которое подтвердило их непротиворечивость и эффективность.
В дальнейшем целесообразно исследовать вопрос эффективности полученных процедур оценивания параметров модели идентификации хранимых данных и их классификации в зависимости от сложности модели (например, порядка авторегрессии р) на реальных массивах данных. Дело в том, что при подгонке статистических данных, например, моделями ARCH(р) приходится обращаться к слишком большим значениям параметра р.
Список литературы
[Бериша, 2005] Бериша В. Н., , Фомина обнаружения знаний в «зашумленных» базах данных // Искусственный интеллект. − 2005. − С. 143-158.
[Буров, 1999] бнаружение знаний в хранилищах данных // Открытые системы. − 1999. − № 5, 6.
[Инишева и др., 1997a] , , Дементьева информационная система «Химия торфов» (АИС «Химия торфов»). Свидетельство об официальной регистрации базы данных № 000, 05.01.1997.
[Инишева и др., 1997b] , , Савичева информационная система «Торфяные ресурсы» (АИС «Торфяные ресурсы»). Свидетельство об официальной регистрации базы данных № 000, 20.01.1997.
[Кашковский, 2006] Кашковский идентификация параметров авторегрессии со случайными коэффициентами // Вестник Томского гос. ун-та. − 2006. − № 000. − C. 105-109.
* Работа выполнена при частичной финансовой поддержке РФФИ (проект № 07-01-00452), РГНФ (проект № 06-06-12603в)
2 634029, Томск, /1, кв. 50, *****@***ru
