

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа № 7
Корреляционно-регрессионный анализ с помощью процедур пакета «Анализ данных»
Изучение корреляционных связей сводится в основном к решению следующих задач:
• выявление наличия (или отсутствия) корреляционной связи между изучаемыми признаками. Эта задача может быть решена на основе параллельного сопоставления (сравнения) значений х и у у п единиц совокупности;
• измерение тесноты связи между двумя (и более) признаками с помощью специальных коэффициентов. Эта часть исследования именуется корреляционным анализом;
• определение уравнения регрессии — математической модели, в которой среднее значение результативного признака у рассматривается как функция одной или нескольких переменных — факторных признаков. Эта часть исследования именуется регрессионным анализом.
Последовательность рассмотрения перечисленных задач, естественно, может меняться в каждом конкретном исследовании.
Общий термин «корреляционно-регрессионный анализ» подразумевает всестороннее исследование корреляционных связей, в том числе нахождение уравнений регрессии, измерение тесноты и направления связи, а также определение возможных ошибок, как параметров уравнений регрессии, так и показателей тесноты связи.
Измерить корреляционную связь между признаками х и у и найти форму этой связи, ее аналитическое выражение (математическую модель) — две важные, неразрывные и дополняющие друг друга задачи корреляционно-регрессионного анализа. Найти уравнение регрессии — значит по эмпирическим (фактическим) данным математически описать изменения взаимно коррелируемых величин.
Уравнение регрессии должно определить, каким будет среднее значение результативного признака у при том или ином значении факторного признака х, если остальные факторы, влияющие на у и не связанные с х, не учитывать, т. е. абстрагироваться от них. Другими словами, уравнение регрессии можно рассматривать как связь средней величины результативного признака у со значениями факторного признака х.
Уравнение регрессии можно также назвать теоретической линией регрессии. Рассчитанные по уравнению регрессии значения результативного признака называются теоретическими, обычно обозначаются ![]() (читается: «игрек, выравненный по х») и рассматриваются как функция от х, т. е. ух = f(x).
(читается: «игрек, выравненный по х») и рассматриваются как функция от х, т. е. ух = f(x).
Найти в каждом конкретном случае тип функции, с помощью которой можно наиболее адекватно отразить ту или иную зависимость между признаками х и у, — одна из основных задач регрессионного анализа.
Выбор теоретической линии регрессии часто обусловлен формой эмпирической линии регрессии; теоретическая линия как бы сглаживает изломы эмпирической линии регрессии. Кроме того, необходимо учитывать природу изучаемых показателей и специфику их взаимосвязей.
Для аналитической связи между х и у могут использоваться следующие простые виды уравнений:
а) yх = a0+a1 x (прямая);
б) ух = а0 + а1 х + а2 x2 (парабола 2-го порядка);
в) ух = a0 + a1 * 1/x (гипербола);
г) ух = а0 а1x (показательная функция);
д) yx=a + a1 lgx (логарифмическая функция) и др.
Обычно зависимость, выражаемую уравнением прямой, называют линейной (или прямолинейной), а все остальные — криволинейными.
Выбрав тип функции, по эмпирическим данным определяют параметры уравнения. При этом отыскиваемые параметры должны быть такими, при которых рассчитанные по уравнению теоретические значения результативного признака ух были бы максимально близки к эмпирическим данным.
Для подготовки к лабораторной работе дополнительно рекомендуется использовать материалы ЛР 5.1 и 5.2
В Excel для решения задачи крреляционно-регрессионного анализа также используются процедуры Корреляция и Регрессия из пакета Анализ данных. Процедура Корреляция позволяет получить корреляционную матрицу, содержащую коэффициенты корреляции между различными параметрами.
В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении каждых строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждый столбец во входном диапазоне полностью коррелирует с самим собой. Рассматривается отдельно каждый коэффициент корреляции между соответствующими параметрами. Отметим, что хотя в результате будет получена треугольная матрица, корреляционная матрица симметрична, и коэффициенты корреляции rij =rji.
Процедура Регрессия позволяет построить регрессионное уравнение,
Процедура решает простейшую задачу парной линейной регрессии:
– по заданным значениям ![]() , i =1, 2, …, n строит методом наименьших квадратов линейную функцию регрессии
, i =1, 2, …, n строит методом наименьших квадратов линейную функцию регрессии ![]() ;
;
– вычисляет некоторые статистики для анализа качества аппроксимации.
Исходные данные для функции
— выборочные значения ![]() , i =1, 2, …, n
, i =1, 2, …, n
Основные численные результаты представлены в трёх таблицах под общим заголовком
ВЫВОД ИТОГОВ
Регрессионная статистика | |
Множественный R | |
R-квадрат | |
Нормированный R-квадрат | |
Стандартная ошибка | |
Наблюдения |
Здесь
: 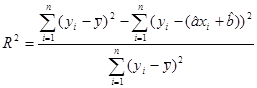
R-квадрат – коэффициент детерминации: ;
![]()
![]()
Стандартная ошибка — стандартная ошибка регрессии: , ;
Наблюдения — количество наблюдений n.
Дисперсионный анализ | |||||
df | SS | MS | F | Значимость F | |
Регрессия | |||||
Остаток | |||||
Итого | |||||
В двух строках таблицы отображаются статистики, относящиеся соответственно к регрессии и к остаткам регрессии:
df — число степеней свободы: ![]() ;
;
SS — сумма квадратов регрессии: ![]() ;
;
MS — среднее суммы квадратов регрессии, сумма квадратов, делённая на число переменных m, в данном случае m = 1.
F — значение критерия Фишера: 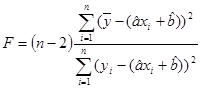 ;
;
Значимость F — вычисленное по выборке значение плотности вероятности распределения Фишера с (1, n-2) степенями свободы;
Следующая таблица — основная таблица, описывающая линию регрессии.
Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |
Y-пересечение | ||||
Переменная X 1 |
Нижние 95% | Верхние 95% | Нижние p% | Верхние p% |
В двух строках таблицы отображаются статистики, относящиеся соответственно к константе b (Y-пересечение) и к коэффициенту a (Переменная X 1) в уравнении линии регрессии y = ax + b:
Коэффициенты — значения коэффициентов соответственно b и a в уравнении линии регрессии y = ax + b;
Стандартная ошибка— стандартная ошибка регрессии: ![]() ,
, ![]() ;
;
t-статистика — вычисленное по выборке значение критерия Стьюдента для проверки значимости коэффициентов (нулевая гипотеза – коэффициент равен нулю): точечная оценка коэффициента, делённая на его стандартную ошибку: ![]() ;
;
P-Значение значение плотности вероятности распределения Стьюдента с (n-2) степенями свободы (малые значения вероятности свидетельствуют в пользу значимости коэффициентов).
Нижние 95%, Верхние 95%, Нижние 90.0%, Верхние 90.0% — соответственно нижние и верхние границы доверительных интервалов для коэффициентов b и a (границы вычисляются с 95% доверительной вероятностью вычисляются по умолчанию, и с p%, заданной пользователем).
