
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема 7. Работа со статической памятью и очередями FIFO.
Принцип работы статической памяти, ее интерфейс. Блочная и распределенная память ПЛИС. Генерация IP блока памяти в программе Coregen. Принцип организации очереди FIFO на основе статической памяти. Интерфейс FIFO. Типы FIFO: Standard FIFO и First Word Fall Through FIFO. Генерация IP блока FIFO в программе Coregen.
Общие принципы функционирования аппаратной памяти
В современном мире существует множество различных архитектур и типов аппаратной памяти. Жесткие магнитные диски, оперативная память компьютера (ОЗУ), флеш память и тд. – все это разные виды электронной памяти. Они имеют разные параметры и свои предназначения. Например, жесткие диски могут хранить информацию очень больших объемов, не требуют внешнего питания для хранения информации (энергонезависимые), но при этом время доступа к информации очень велико. Поэтому, чтобы обеспечить высокую производительность компьютера, жесткие диски не используются для хранения исполняемого процессором кода. Вместо этого в качестве оперативной памяти используется быстрая динамическая память типа DDR. Ее объем, как правило, меньше чем объем жесткого диска, но при этом она на порядок быстрее. Также память DDR энергозависима, т. е. она может сохранять информацию только, пока компьютер включен, но это не является проблемой, ибо оперативная память компьютера постоянно обновляется и не хранит какой-либо архивной информации. Другой пример – флеш память. Ее быстродействие выше чем у жесткого магнитного диска, при этом она также энергонезависима, и уже существуют устройства типа жестких дисков, но использующие в качестве носителя информации флеш память. При этом 1 Гбайт на флеш памяти намного дороже 1 Гбайт памяти на магнитном диске.
По какой бы технологии не была бы сконструирована память, для каждой применимы следующие параметры: объем, быстродействие, энергозависимость, цена. Также концептуально все типы памяти будут иметь примерно одинаковый интерфейс, включающий следующие сигналы.
- Входная шина данных, по которой данные загружаются в память. Выходная шина данных, по которой данные считываются из памяти. Адресная шина, определяющая к каким ячейкам памяти происходит обращение. Управляющая шина, включающая сигналы, определяющие тип операции (чтение/запись).
Static RAM
В дальнейшем нас будет интересовать технология Static CMOS RAM – статическая КМОП память с произвольным доступом. Это энергозависимая память, которой для поддержания сохранности данных требуется внешнее питание. Именно по этой архитектуре построена конфигурационная память ПЛИС фирмы Xilinx, и поэтому их надо заново конфигурировать при каждом включении. Существует другая фирма, производящая ПЛИС, под названием Actel. Они выпускают ПЛИС с конфигурационной памятью, построенной по технологии Flash. Поэтому их FPGA не требуют конфигурации при каждом включении – их можно запрограммировать один раз, и их конфигурационная память Flash сохранит все данные даже в выключенном состоянии. Однако, так уж получилось, что технология производства кремниевых чипов по технологии Flash на 2-3 поколения отстает от технологии CMOS. Это значит, что если самые современные ПЛИС Xilinx (построенные на CMOS) на момент 2013 года используют технологию 22 нм, то фирма Actel способна производить свои FPGA (построенные на Flash), используя лишь тех процесс 65 нм. А это означает, что в среднем FPGA фирмы Xilinx будут иметь примерно в 9 раз больше логических вентелей на единицу площади кристалла.
Вернемся к Static CMOS RAM. Давайте поясним, что это такое. CMOS – значит, что память выполнена с использованием CMOS транзисторов. RAM – это random access memory, т. е. память с произвольным доступом. Это значит, что производительность памяти не зависит от последовательности обращений к ее ячейкам. То есть мы можем читать/писать ее ячейки в любом порядке по любым адресам на каждом такте. В отличие от RAM существуют типа памяти с последовательным доступом. Пример – видео кассета VHS на магнитной ленте. Используя ленту, вы можете последовательно просмотреть весь фильм, но невозможно посмотреть 5 секунд вначале фильма, а потом бес перемотки 5 секунд в середине. А перемотка – это уже серьезная потеря производительности.
Static означает, что память статическая, и информация, раз записанная туда, сохраняется в течение неограниченно долгого времени (при условии сохранения питания) и не требует постоянной перезаписи (или регенерации), как в случае с динамической памятью DDR. В отличие от статической памяти, построенной на транзисторах, динамическая DDR память использует принцип сохранения битов информации в конденсаторах. Конденсаторы имеют фундаментальное свойство разряжаться с течением времени, поэтому чтобы сохранить информацию, записанную на них, аппаратный контроллер DDR памяти периодически перезаписывает содержащуюся там информацию – отсюда и название: динамическая.
Статическая память синхронна (т. е. работает по тактовому сигналу) и имеет также очень простой интерфейс:
COMPONENT static_ram
PORT (
clk : IN STD_LOGIC; -- тактовый сигнал
rst : IN STD_LOGIC; -- сигнал сброса
en : IN STD_LOGIC; -- сигнал разрешения работы (опционально)
we : IN STD_LOGIC; -- write enable, сигнал определяющий операцию записи или чтения
addr : IN STD_LOGIC_VECTOR(3 DOWNTO 0); -- шина адреса ячейки
din : IN STD_LOGIC_VECTOR(15 DOWNTO 0); -- входная шина данных
dout : OUT STD_LOGIC_VECTOR(15 DOWNTO 0) -- выходная шина данных
);
END COMPONENT;

Работа памяти происходит по переднему фронту тактового сигнала CLK. Сигнал разрешения работы EN опционален. Если его нет в интерфейсе, то считается, что память всегда готова к работе, и на очередном такте ее поведение определяется сигналом разрешения записи WE. Если он равен 1, то на текущем такте значение, присутствующее на входной шине данных DIN, записывается в ячейку память с адресом, указанным на адресной шине ADDR. Если WE равен 0, то идет транзакция чтения, входная шина данных игнорируется, а на выходную шину данных DOUT выставляется значение, сохраненное в ячейке памяти, адресуемой ADDR. Значение DOUT устанавливается с некоторой задержкой относительно переднего фронта тактового сигнала (по которому началась транзакция), поэтому внешняя схема считывает данные из памяти на следующем после выставления ADDR такте. На i такте мы выставляем адрес, а на i+1 такте считываем значение из памяти. Если EN присутствует в интерфейсе, то работа памяти определяется следующей таблицей.
EN | WE | Операция |
1 | 0 | Чтение |
1 | 1 | Запись |
0 | 0 | Память не работает |
0 | 1 | Память не работает |
Еще раз повторим, что при транзакции записи ADDR и DIN выставляются одновременно на одном и том же такте, и значение DIN записывается в ячейку ADDR. На следующем и последующих тактах как ADDR, так и DIN могут меняться, т. е. каждый такт можно записывать в память новое значение по новому произвольному адресу.
При транзакции записи ADDR выставляется на текущем такте, а считывать данные
Однопортовая и двупортовая память
Описанный выше интерфейс статической памяти относится к типу однопортовой памяти (Single Port RAM). Бывает еще двупортовая память (Dual Port RAM). Двупортовая память предоставляет еще один интерфейс к тем же самым ячейкам памяти. Получается, мы имеем два независимых порта, для независимого доступа к одним и тем же ячейкам памяти. Например, через один порт можно данные записывать, а через другой считывать. Либо записывать данные через оба порта. При этом могут быть коллизии, когда идет одновременная запись в одну и ту же ячейку памяти, для их разрешения предусмотрены разные настройки, типа приоритета порта.
Важно понимать, что за каждых из одного или двух портов стоит вполне конкретная аппаратная схема, перемещающая данные между ячейками памяти и ее внешним интерфейсом. Можно сделать память и с тремя портами, просто в этом часто нет надобности.
Блочная и распределенная память
Внутри ПЛИС Xilinx есть специальный аппаратный ресурс – блочная память или BRAM (Block RAM). Для FPGA Spartan 6 это набор из специальных аппаратных блоков статической памяти, каждый объемом 18 Кбит. Эти блоки выполнены аппаратно, т. е. часть логики кристалла зафиксирована под память, и не может быть использована по другому назначению. Количество таких блоков зависит от конкретного типа кристалла ПЛИС и может быть до нескольких сотен. Каждый блок имеет два аппаратных порта, которые могут работать на разных тактовых частотах.
Другой ресурс, который можно использовать как память – это сами конфигурационные блоки ПЛИС. Из конфигурационных блоков можно собрать логическую схему статической памяти. Тогда биты информации, хранящиеся в такой памяти будут «размазаны» или «распределены» по большей (по сравнению с BRAM, организованным локально) площади кристалла, и такая память будет называться распределенной памятью (Distributed RAM).
Сравнивая блочную и распределенную память, надо сказать следующее:
- Блочная память – это быстрые аппаратные блоки, способные работать на частотах до 500 МГц, что намного больше предельной частоты работы распределенной памяти. Блочная память – дорогостоящий ресурс. Количество ее ограничено. При этом, если требуется объем памяти меньший чем объем одного блока (18 Кбит), то все равно будет использован весть блок, и неиспользованная его часть просто пропадет. При этом распределенная память может быть создана конкретного объема: ни одного лишнего конфигурационного блока не будет задействовано. При использовании блочной памяти ее разные порты могут работать на разных частотах. Это удобно использовать для синхронизации между разными клоковыми доменами.
Схемы как блочной так и распределенной памяти создаются с использованием программы Xilinx Coregen. В ней можно выбрать необходимый тип памяти, объем, ширины шин данных, особенности и интерфейса. После создания IP блока, работать с памятью надо через интерфейс, подобный рассмотренному выше. Надо сказать, что в VHDL есть возможность описать массив ячеек статической памяти с помощью сигналов типа массив и стандартных операторов, но я предостерегаю от использования этого подхода, т. к. в этом случае сложно контролировать реальную аппаратную реализацию полученной после синтеза схемы. Используя же Coregen вы будете точно знать, что вы получаете.
Очереди FIFO
На основе статической памяти можно легко построить очень нужную структуру, называемую очередь FIFO.
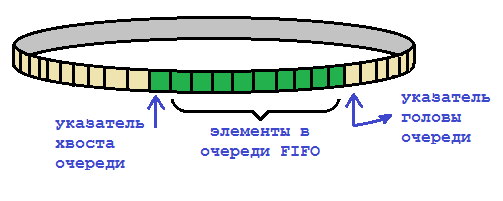
Очередь FIFO (First In, First Out) представляет собой циклический буфер, где будут храниться помещаемые в очередь данные. Есть два указателя: указатель на «голову» очереди (head) и указатель на «хвост» очереди (tail). С этим объектом связаны две операции: помещение в очередь нового элемента и извлечение из очереди самого старого элемента. Новый записываемый элемент помещается в ячейку, на которую указывает head, затем этот указатель перемещается на следующую ячейку памяти буфера. Выбираются элементы из очереди по указателю tail, после того, как элемент выбран из очереди, указатель tail так же передвигается вперед к следующей ячейке. Обычно глубина FIFO и разрядность указателей являются числами степени двойки. Например, если разрядность указателей head и tail – это 8, то глубина FIFO будет 256 элементов.
Цикличность буфера обеспечивается автоматически. При последовательном увеличении значения указателя однажды возникает перенос, а сам указатель при этом обнуляется (после указаего следующее значение будет 0).
Теперь, когда мы знаем, что есть два указателя, легко определить всякие информационные сигналы:
- FIFO пусто, если значения указателей «голова» и «хвост» равны. Число элементов хранимых в FIFO можно вычислить отняв от значения «головы» значение указателя «хвоста». Если получится отрицательное число, то нужно еще прибавить глубину FIFO. FIFO полное, если число хранимых элементов на единицу меньше, чем глубина FIFO.
Возможно, последнее утверждение нуждается в пояснении. Например, глубина FIFO 256 элементов. Мы запишем в него 255 элементов, но читать из FIFO пока не будем. Тогда «голова»=255, а «хвост»=0. Сейчас FIFO полное. Если в него записать еще один элемент, то значение «головы» станет 0 (возникает перенос) и получится, что и «голова» и «хвост» становятся одинаковыми и равными нулю. Все, FIFO опять стало пустым? Конечно, это ошибка логики. Нельзя допускать запись в полное FIFO и чтение/выборку элемента из пустого FIFO. Обычно это контролируется на уровне аппаратной схемы «внутри» блока самого FIFO. Если FIFO оказалось полным, а внешняя схема все равно хочет произвести в нее запись, то в FIFO просто ничего не запишется.
Интерфейс FIFO
Очередь FIFO всегда используется для однонаправленной передачи данных. Есть сторона, в которую данные записываются, и есть сторона, откуда данные считываются. Часто FIFO создаются на основе двупортовой памяти BRAM. Как вы помните, каждый порт этой памяти может работать на свой частоте, а значит и FIFO может работать на двух разных частотах. Часто очереди FIFO используются для передачи данных между разными клоковыми доменами.
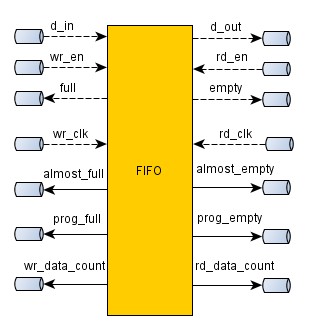
Схемы FIFO мы всегда будем создавать с помощью программы Coregen. В самом базовом виде у FIFO будет следующий интерфейс.
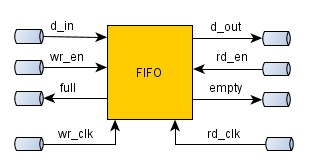
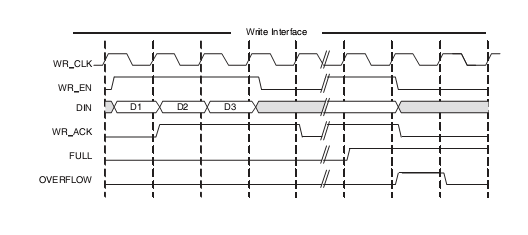
Сигналы d_in и d_out – это входная и выходная шины данных. Их разрядность может быть произвольной и задается в программе Coregen. Сигнал wr_en и full используется для записи данных в FIFO: если на очередном такте wr_en = 1, а full = 0, то значение на шине d_in запишется в очередь. Если же wr_en = 1, а при этом очередь полная (full=1), то данные в очередь не записываются и просто теряются. Вы, как разработчики аппаратных схем, должны следить за тем, чтобы НИКОГДА не выставлять сигнал wr_en на том же самом такте, когда full=1.
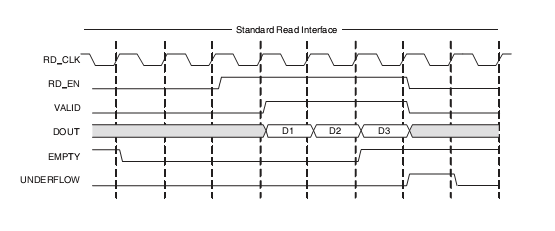
Сигналы rd_en и empty используются для чтения данных из FIFO. Если на текущем такте сигнал rd_en = 1, а empty = 0, данные будут прочитаны из FIFO. При этом есть два варианта. При создании FIFO в Coregen вы определяете тип FIFO: Standard FIFO или First Word Fall Through. При использовании типа Standard FIFO очередные данные появляются на выходной шине d_out на следующем такте после выставления сигнала rd_en. На i-ом такте вы выставляете сигнала rd_en, а на i+1 такте считываете данные с шины d_out.
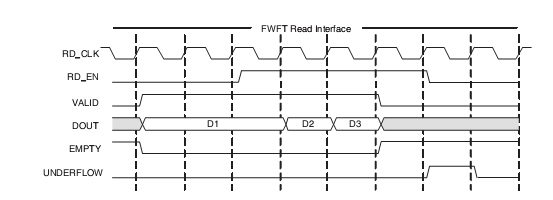
При использовании типа First Word Fall Though FIFO очередь уже заранее считала очередное значение из своего массива памяти и держит его в регистре, соединенным с выходной шиной данных d_out. Это означает, что очередное правильное данное уже присутствуют на выходе FIFO, и при выставлении сигнала rd_en FIFO считает следующее данное из своего массива памяти и на следующем такте поместит его на выходную шину данных. Поэтому считывать очередное значение из FIFO в этом режиме необходимо одновременно (т. е. на том же самом такте) с выставлением сигнала rd_en. На i-ом такте вы выставляете сигнала rd_en, и на этом же i-ом такте считываете данные с шины d_out.
Если в обоих случаях при выставлении сигнала rd_en очередь оказывается уже пустой (empty = 1), то ничего из FIFO не считывается, и вы получаете ошибку в потоке данных. Вы, как разработчики аппаратных схем, должны следить за тем, чтобы НИКОГДА не выставлять сигнал rd_en на том же самом такте, когда empty=1.
Если используется асинхронное FIFO, у которого каждая сторона работает на своей частоте, но в интерфейсе FIFO будут присутствовать соответствующие порты – wr_clk и rd_clk. При этом сигналы d_in, wr_en и full будут синхронны с частотой wr_clk, а d_out, rd_en и empty должны быть синхронны с частотой rd_clk. Если обе стороны FIFO работают на одной частоте, то соответственно будет только один порт для тактового сигнала.
Сказанное иллюстрируют следующие временные диаграммы.
Запись в FIFO:
Чтение из очереди типа Standard FIFO
Чтение из очереди типа First Word Fall Through FIFO
Интерфейс FIFO. Дополнительные сигналы
Рассмотренные выше сигналы всегда присутствуют в интерфейсе FIFO. В принципе их достаточно, чтобы эффективно работать с очередями. Однако, иногда бывает удобнее конструировать внешнюю схему, если интерфейс FIFO включает в себя еще некоторые дополнительные сигналы.
Сигнал almost_full выставляется очередью, когда в FIFO остается всего одна пустая ячейка. Если на текущем такте almost_full = 0, то на следующем такте 100% безопасно записывать очередное данные в очередь. Это очень удобно при конструировании автоматов, записывающих данные в FIFO. Сигнал prog_full выставляется в единицу, когда количество данных в очереди достигло некоторого порога, определяемого при создании FIFO (в Coregen), либо с помощью еще одного дополнительного сигнала интерфейса (тут не показан) – prog_full_threshold.
Также сигнал almost_empty выставляется, когда в очереди остается только 1 элемент. А сигнал prog_empty = 1, когда количество данных в очереди становится меньше некоторого порога.
Сигналы wr_data_count и rd_data_count определяют количество слов данных, записанных в FIFO, и видимых со стороны записи и чтения соответственно. Различаются эти сигналы только в случае использования асинхронного FIFO.
Асинхронное FIFO
Часто оказывается, что запись и чтение происходят с использованием разных тактовых частот. Мы не можем на прямую сравнивать или делать какие-то арифметические операции с указателями «голова» и «хвост», так как в этом случае они храняться в разных клоковых доменах (clock domains). Просто пересинхронизировать группу (8-ми битные счетчики указателей голова и хвост) сигналов в другой домен не есть хороший вариант. Главная проблема здесь – не все биты шины могут перейти в другой клоковый домен одновременно, а значит двоичное число на шине может быть искажено.
С другой стороны, понятно, что и «хвост» и «голова» могут изменяться только на единицу за один раз. То есть они считают последовательно. Этот факт как раз и делает возможным использование специальных счетчиков - счетчиков Грея. Код Грея — специальная система счисления, в которой два соседних значения различаются только в одном разряде.
Методика использования кодов Грея может быть следующая. Значение счетчика указателя, например, головы FIFO перекодируется в код Грея и пересекает клоковый домен с помощью группы синхронизаторов (каждый – это два последовательных триггера). При этом не все биты могут быть зафиксированы верно: в новом клоковом домене в некоторых битах зафиксируются новые значения числа на шине, а в некоторых – старые значения. Однако, для кода Грея изменения в соседних числах счетчика происходят только в одном бите, значит только в одном бите и может произойти коллизия. Только один изменяющийся сейчас бит может быть принят не верно. В этом случае принимающий домен просто считает предыдущее число на шине, а верное, следующее число он считает на следующем такте своей частоты. Такая ошибка даже и ошибкой не считается, ведь она не приводит к аварии FIFO.
Принятый код Грея может быть перекодирован обратно в обычную двоичную систему счисления и тут уже мы имеем верное значение обоих указателей в одном клоковом домене. Теперь можно их сравнивать, вычислять число элементов в FIFO и так далее. В принципе, FIFO может изначально держать указатели «головы» и «хвоста» в кодах Грея. Вообще использование кодов Грея в асинхронных FIFO очень распространено, так как действительно позволяет решить проблему пересечения клокового домена для потока данных.
Пример на чтение из FIFO с записью в BRAM и одновременным чтением из BRAM с
записью в TX_FIFO
ДЗ
RX -> TXКонтрольные вопросы
Принцип работы и интерфейс статической памяти. Варианты построение памяти в FPGA. Двупортовая память. Принцип работы и интерфейс схемы очереди FIFO. Интерфейс и режимы работы FIFO: Standard FIFO и FWFT FIFO.Литература
Точчи, Уидмер. «Цифровые системы. Теория и практика». Глава 11 (стр 761)