
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Методические указания к выполнению лаборатной работы №2
по курсу «Теория информации и кодирования»
Исследование статистического подхода к оценке информативности
источника и сжатию кода сообщений
Цели работы:
- закрепить знание основ статистического подхода к оценке информативности источника;
- освоить подход к построению, оценке и применения классических статистических кодов;
- познакомиться с современным адаптивным подходом к сжатию сообщений.
Краткие теоретические сведения
Основой ТИК является статистический подход к определению информативности. В частности, мерой информативности источника сообщений является величина энтропии, которая отражает вероятностное разнообразие их элементов: чем такое разнообразие выше, тем больше информации источник в принципе способен отдавать. Вероятностные закономерности являются также основой статистического сжатия сообщений.
Величина энтропии Источника определяется как для случая независимых элементов сообщений (безусловная энтропия), так и с учетом их возможной взаимосвязи (условная энтропия). Безусловная энтропия убывает с ростом неравномерности вероятностного распределения, что делает появление знаков более предсказуемым. Условная энтропия уменьшается, когда связи между знаками позволяют их предсказание по предыстории. Описание расчета и свойств энтропии для наиболее важного случая источника дискретных сообщений приведено в разделах 2 и 3 лекции 3.
* Для непрерывного источника величина полной энтропии ПЭ бесконечна (как бесконечно, например, число точек на отрезке линии), поэтому на практике часто опираются на расчет дифференциальной энтропии ДЭ - отличия ПЭ данного источника от некоторого базового случая. При этом ДЭ может быть в том числе отрицательной. Ее величина определяется характеристиками распределения вероятностей — дисперсией и также формой (для практики наиболее важны случаи равномерного и нормального распределений). Описание энтропии непрерывного источника есть в разделе 4 лекции 3.
Важный теоретический результат заключается в том, что принципиально возможно сжать среднюю длину кода знаков до величины близкой к энтропии. В зависимости от используемых методов это может быть как энтропия безусловная (когда связи между знаками не учитываются), так и условная энтропия разной глубины (при учете таких связей).
Классическое статистичесткое сжатие базируется на предположении, что вероятностные характеристики всех сообщений источника неизменны и заранее изучены. Такой подход называют статическим или «фиксированным». Наибольшее распространение здесь получил метод Хаффмена, где все знаки алфавита источника кодируются по-отдельности. Детальное описание этого метода приведено в разделе 3 лекции 4.
* Более сложной альтернативой является «арифметическое кодирование». Здесь код строится для целого блока символов, что улучшает сжатие ценой роста трудоемкости. Такое кодирование (тоже в «фиксированном» варианте) описано в разделе 5 лекции 4.
Принципиальное ограничение статистичекого кодирования в его классическом варианте состоит в том, что нереально использовать статистическое описание для множества источников (например, файлов различных типов и текстов на разных языках). В этих условиях данный метод обычно применяется в качестве вспомагательного, но распространен очень широко.
Адаптивное статистическое сжатие позволяет автоматически приспосабливаться к любому источнику. Здесь источник и получатель синхронно строят и изменяют код по общему алгоритму. Однако, при этом сохраняется еще один важный недостаток статистических методов: они не учитывают предысторию знаков сообщения. В результате пределом для них остается приближение средней длины кода знака к величине именно безусловной энтропии.
* Описание адаптивного кодирования по Хаффмену приведено в разделе 4 лекции 4. Адаптивный вариант арифметического кодирования использует схожие принципы.
Содержание работы
Настоящая работа включает три раздела, посвященные соответственно:
- анализу информативности источников через анализ его энтропии;
- построению, оценке и применению фиксированного статистического кода;
- знакомству с адаптивным статистическим кодированием.
Индивидуальные варианты исходных данных приведены в табл. В1.
Таблица В1
Статистические характеристики источников сообщений и данные для кодирования
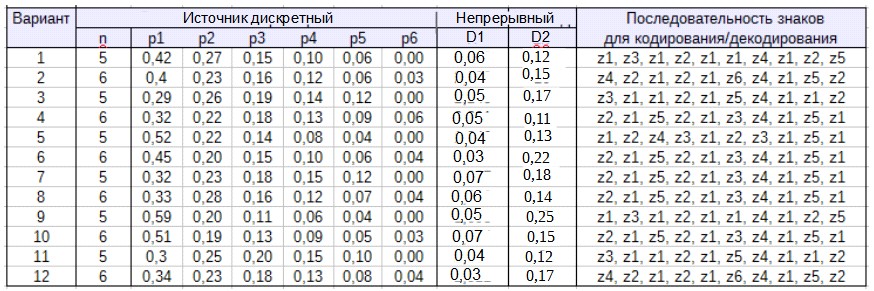
В разделе 1 с помощью электронных таблиц выполняется расчет энтропии дискретного и непрерывного источников по их вероятностным характеристикам, (табл. В1). * Полный вариант работы включает также анализ для непрерывного источника.
В разделе 2 строится таблица кодирования-декодирования по «фиксированному» методу Хаффмена (табл. В1), а также оценивается избыточность кода и выполняется пример его использования для заданной последовательности знаков. * Полный вариант включает дополнительно разбор алгоритма арифметического кодирования.
В разделе 3 выполняется исследование статистических характеристик конкретных сообщений типичных форматов, а также оценка эффективности их сжатия по адаптивному алгоритму Хаффмена. Для этого используются соответствующие демонстрационные программы. * В полном варианте работы предусмотрено изучение адаптивного алгоритма Хаффмена.
Порядок выполнения работы
1) Расчет и анализ энтропии источников сообщений
а) Выполнить анализ для безусловной энтропии дискретного источника сообщений:
- создать электронную таблицу для расчета безусловной энтропии;
- выполнить расчет энтропии для исходного распределения вероятностей (согласно варианту по табл..В1), а также двух дополнительных вариантов, отличающихся в сторону увеличения и уменьшения энтропии. Представить результаты в форме табл.1 (пример оформления отчета в Приложении) и сформулировать резюме;
б)* Выполнить анализ дифференциальной энтропии непрерывного источника сообщений (для равномерного и нормального распределения плотности вероятностей):
- дополнить электронную таблицу необходимыми формулами для расчета ;
- выполнить расчет для значений дисперсии D распределения по варианту из табл. В1. При этом ширина интервала (b-a) для равномерного распределения вычислется как √(12*D). Представить результаты в форме табл.2. (см. Приложение) и сформулировать резюме.
2) Построение, оценка и применение классического статистичесткого кода
а) Построить таблицу кодирования-декодирования по заданным в табл. В1 вероятностям знаков в порядке, который рассмотрен в Лекции 3. Поместить в отчет рисунок с таблицей объединения вероятностей и графом “дерева” кода (см. Рис.1 в Приложении).
б) Подсчитать величину избыточности для случаев исходного кодирования с использованием кодовых страниц (Lk=8 разрядов/знак) и применения построенного кода Хаффмена. Сделать вывод об эффективности кодирования. Записать результаты в отчет.
в) Выполнить кодирование и декодирование цепочки знаков из табл. В1. Подсчитать выборочную среднюю длину кода знака. Объяснить результаты и поместить их в отчет.
г) * Разобраться с кодированием и декодированием арифметическим кодом
3) Ознакомление с адаптивным кодированием по Хаффмену и оценка его эффективности
б) Выполнить оценку безусловной и условной энтропии для файлов разных типов из папки вашего варианта:
- запустить программу StatDemo (из папки лабораторной работы). На примере текстового файла из освоить использование программы. (Пользоваться режимом Файл для выбора и просмотра файла, а также режимом Статистика-Общая для расчета статистики);
- рассчитать выборочные значения энтропии для файлов типа txt, xls, bmp и поместить результаты в табл.3. Объяснить их.
а) Исследовать уровень статистического сжатия кода файлов разных типов:
- запустить демонстрационную программу ArchDemo (из папки лабораторной работы) и задать режим использования адаптивного метода Хаффмена (Haffman adaptive);
- последовательно выполнить сжатие файлов из папки лабораторной работы и записать результаты в форме табл.4 (см. приложение);
- дополнить колонку «Ограничения по энтропии» табл.4 расчетным значением степени сжатия файла Н(0)/Lkисх (для Lkисх = 8 разряд/знак).
в) Оценить эффективность адаптивного метода Хаффмена, сравнив достигнутую степень сжатия с ограничениями по безусловной энтропии (табл.4). Обратить внимание, что в силу адаптивного характера алгоритма в отдельных случаях степень сжатия может быть выше, чем задает ограничение по энтропии. Объяснить результаты и сформулировать резюме.
г) * Разобраться с алгоритмом адаптивного кодирования по Хаффмену.
Вопросы для самоконтроля при подготовке к защите отчета
К разделу 1
1) Разъясните, почему увеличение энтропии источника означает рост его информативности.
2) Запишите и поясните формулы для расчета безусловной энтропии Н(0) и условной Н(1) для дискретного источника информации.
3) Как расчетная величина энтропии может быть использована для оценки возможностей сжатия сообщений.
4) * Запишите и поясните формулы для расчета полной и дифференциальной энтропии.
К разделу 2
1) Поясните, за счет чего достигается сжатие кода при статистическом кодировании.
2) Сформулируйте теорему Шеннона о кодировании источника. Как она доказывается.
3) Чем на практике ограничено применение «фиксированных» статистических кодов.
4) * Поясните на примере алгоритм арифметического кодирования и декодирования.
К разделу 3
1) Каковы преимущества и недостатки адаптивного статистического кодирования
2) Почему возможны случаи, когда степень сжатия файла адаптивным алгоритмом оказывается больше, чем расчетная исходя из его энтропии
3) Поясните связь значений энтропии с типом файлов на примере данных лабораторной
4) * Опишите на примере алгоритм кодирования по адаптивному методу Хаффмена
Приложение
Пример оформления отчета
Отчет о выполнении лабораторной работы №2
по курсу «Теория информации и кодирования»
студентом ___________ (группа ___) в 2017-18 учебном году
по индивидуальному варианту данных №X
(полный вариант выполнения)
Тема: Исследование статистического подхода к оценке информативности
источника и сжатию кода сообщений
Цели работы:
- закрепить знание основ статистического подхода к оценке информативности (особенности расчета информационной энтропии и ее свойства);
- на практике освоить способ построения и применения классического кода Хаффмена как наиболее распространенного статистического кода;
- познакомиться с современным адаптивным подходом к сжатию сообщений.
Раздел 1. Расчет и анализ энтропии источников сообщений
а) С помощью созданной электронной таблицы выполнил расчет безусловной энтропии дискретного источника. Данные приведены в табл.1.
Таблица 1.
Расчет безусловной энтропии источника дискретных сообщений
(объем алфавита N=6 знаков, максимальная энтропия Hmax=log2N=2,585 бит/знак)
Убедился, что энтропия уменьшается с ростом неравномерности распределения вероятностей знаков и стремится к максимуму, когда распределение приближается к равномерному.
б*) С помощью созданной электронной таблицы выполнил расчет дифференциальной энтропии непрерывного источника для важнейших распределений плотности вероятности в зависимости от дисперсии и мат. ожидания. Данные приведены в табл.2.
Таблица 2.
Расчет дифференциальной энтропии источника непрерывных сообщений
Убедился, что дифференциальная энтропия (ДЭ) непрерывного источника:
- может быть как положительной, так и отрицательной и нулевой (разобрался почему);
- при одинаковой дисперсии величина ДЭ для нормального распределения больше, чем для равномерного.
Раздел 2. Построение, оценка и применение классического кода Хаффмена
а) Согласно вероятностям для базового варианта в табл.1 построил таблицу кодирования-декодирования для классического кода Хаффмена (рис.1).
б) Выполнил оценку избыточности кодирования исходя из величины энтропии H=2,487 бит/знак:
- для исходного кодирования при Lkисх=8 разрядов/знак избыточность Dисх = 0,689 (примерно 69%);
- для построенного кода при Lkxфм=2,585 разрядов/знак избыточность Dхфм = 0,038 (примерно 4%).
Таким образом, статистическое кодирование в данном случае дает значительный эффект.
Степень сжатия кода Lkxфм/ Lkисх составляет 0,323 (примерно 32%) - в смысле что осталось.

Рисунок 1. Построение кода Хаффмена
в) Выполнил пример по кодированию-декодированию последовательности из 10 заданных знаков с использованием построенного кода Хаффмена (рис.2).
Рисунок 2. Пример кодирования и декодирования построенным кодом Хаффмена
Разобрался в сути использования правила префиксности при декодировании.
г) * Разобрался с методом арифметического кодирования.
Раздел 3. Ознакомление с адаптивным кодированием и оценка его эффективности
а) Выполнил статистическую обработку и оценку энтропии для заданных файлов распространенных форматов с помощью демонстрационной программы StatDemo. Результаты приведены в табл.3.
Таблица 3.
Результаты оценки информативности на основе учета статистики конкретных сообщений
Убедился, что с ростом глубины учета предыстории знаков энтропия сокращается, что означает увеличение возможностей сжатия в том числе для файлов разных типов.
б) Выполнил эксперименты по сжатию файлов из табл.3 методом адаптивного кодирования по Хаффмену (с помощью демо-программы ArchDemo). Результаты приведены в табл.4.
Таблица 4.
Результаты сжатия адаптивным алгоритмом Хаффмена
Убедился, что адаптивный метод достаточно полно использует возможности статистического сжатия (в смысле близости к ограничениям по энтропии). При этом возможности дополнительного сжатия за счет учета предыстории знаков остаются неиспользованными. В отдельных случаях степень сжатия превосходит ограничение по безусловной энтропии, что может быть связано с адаптацией алгоритма к изменениям статистики знаков по ходу обработки сообщения.
