

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2000 год
Нижегородский государственный технический университет
Кафедра “Электроника и сети ЭВМ”
Лабораторная работа №1.
Эффективное кодирование
Выполнил:
студент группы: 98-В-1
Проверил:
г. Нижний Новгород
2000 год
Цель работы.
Изучить способы эффективного кодирования информации по методам Шеннона-Фано и Хаффмана.
Теоретическая часть.
Задачи эффективного кодирования заключаются в следующем :
Запоминание максимального количества информации в ограниченной памяти. Обеспечение максимальной пропускной способности источника сообщений.Максимальное количество информации I, которое может передаться сигналом, определяется по формуле (1)
![]()
где my - количество состояний сигнала.
Фактический объем переносимой информации определяется энтропией его множества сообщений Н. В связи с тем, что в основном в передаваемом наборе сообщений присутствуют типичные последовательности, сообщения передаются с относительной избыточностью D (2).
![]()
Для уменьшения избыточности символов необходимо применить эффективное кодирование. Эффективным называется способ кодирования, при котором :
Не возникает потери информации. Требуется минимальное количество кодовых символов.Для выполнения второго условия используются неравномерные коды, где длина кодового слова обратно пропорциональна вероятности его появления в сообщении.
Использование эффективного кодирования целесообразно, если вероятности появления различных букв существенно различаются, так как при этом энтропия множества букв (блоков) существенно меньше их информационной емкости.
Эффективное кодирование достигается благодаря учету априорных статистических характеристик источника информации.
Предельные возможности эффективного кодирования определяются (3)
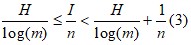
Теоретический расчет.
Для расчетов примем вероятность появления ‘1’ равной 0.26
Метод Шеннона-Фано.
Расчет для n=2
# | Вероятность | Код | ||
0 | 0.5476 | 1 | ||
1 | 0.1924 | 0 | 1 | |
2 | 0.1924 | 0 | 0 | 1 |
3 | 0.0676 | 0 | 0 | 0 |
Расчет для n=3
# | Вероятность | Код | |||
0 | 0.4053 | 1 | 1 | ||
1 | 0.1424 | 1 | 0 | ||
2 | 0.1424 | 0 | 1 | 1 | |
4 | 0.1424 | 0 | 1 | 0 | |
3 | 0.05 | 0 | 0 | 1 | 1 |
5 | 0.05 | 0 | 0 | 1 | 0 |
6 | 0.05 | 0 | 0 | 0 | 1 |
7 | 0.018 | 0 | 0 | 0 | 0 |
Расчет для n=4
# | Вероятность | Код | ||||||
0 | 0.2998 | 1 | 1 | |||||
1 | 0,105 | 1 | 0 | 1 | ||||
2 | 0,105 | 0 | 0 | 0 | ||||
4 | 0,105 | 0 | 1 | 1 | ||||
8 | 0,105 | 0 | 1 | 0 | 1 | |||
3 | 0,037 | 0 | 1 | 0 | 0 | |||
5 | 0,037 | 0 | 0 | 1 | 1 | |||
6 | 0,037 | 0 | 0 | 1 | 0 | 1 | ||
9 | 0,037 | 0 | 0 | 1 | 0 | 0 | ||
10 | 0,037 | 0 | 0 | 0 | 1 | 1 | ||
12 | 0,037 | 0 | 0 | 0 | 1 | 0 | ||
7 | 0,013 | 0 | 0 | 0 | 0 | 1 | 1 | |
11 | 0,013 | 0 | 0 | 0 | 0 | 1 | 0 | |
13 | 0,013 | 0 | 0 | 0 | 0 | 0 | 1 | |
14 | 0,013 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
15 | 0,00456 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Средние длины кодовых слов равны:
n=2; L=1.712
n=3; L=2.525
n=4; L=3.363
Метод Хаффмана.
Граф Хаффмана для n=2.
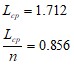
Граф Хаффмана для n=3.
Алгоритм кодирования методом Хаффмана.
Буквы алфавита сообщений вписываются в основной столбец в порядке убывания вероятностей. Две последние буквы объединяются в одну вспомогательную букву, которой приписывается суммарная вероятность. Вероятности букв, не участвовавших в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания в дополнительном столбце, а две последние объединяются. Процесс продолжается до тех пор, пока не получим единственную вспомогательную букву с вероятностью, равной единице.
Для составления кодовой комбинации, соответствующей данному сообщению, необходимо проследить путь перехода сообщения по строкам и столбцам таблицы.
Алгоритм кодирования методом Шеннона-Фано.
Буквы алфавита сообщений вписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним 0. Каждая из полученных групп в свою очередь разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Анализ предельных возможностей кодирования.
По формуле (4) рассчитывается H(x)=0.827
![]()
График возможностей кодирования для различных случаев представлен ниже.
Вывод: эффективность кодирования информации улучшается с увеличением размера блока.
