

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Методические указания к написанию 3 раздела курсовой работы
В рамках третьего раздела курсовой работы, необходимо осуществить прогноз развития вопроса, обозначенной в теме (например, прогнозирование численности населения России на 2017 год).
В качестве исходных данных выступает массив показателей, представленных в разделе 2 курсовой работы, за число периодов кратных 16 периодов (лет или месяцев). Например, за период с 1999 года по 2015 год.
На основании этих данных строится график зависимости показателя от времени.
Прогнозирование будет осуществляться на основании модели тренда.
Для решения поставленной задачи, в порядке первого приближения, намечаются типы функций, которые могут отобразить имеющиеся во временном ряду изменения.
В Microsoft Excel трендовые модели строятся на основе диаграмм, представляющих уровни динамики. Несмотря на то, что для эмпирического временного ряда могут быть построены гистограмма, линейчатая диаграмма, график, точечная диаграмма и диаграмма с областями, рекомендуем использовать только точечную диаграмму, как наиболее лаконичную форму графического изображения временного ряда.
Для построения линии тренда необходимо выделить на диаграмме временной ряд и выбрать в контекстном меню (вызывается щелчком правой клавиши мыши) команду «Добавить линию тренда». Будет вызвано диалоговое окно «Линия тренда», содержащее вкладку «Тип» на которой задается тип тренда:
линейный; логарифмический; полиномиальный (от 2-й до 6-й степени включительно); степенной; экспоненциальный, скользящее среднее (с указанием периода сглаживания от 2 до 15).Поскольку нас интересует аналитическое выражение регрессионной зависимости, не следует рассматривать последний тип тренда (скользящее среднее). Кроме того, при подборе уравнения не следует рассматривать полиномы выше 3-го порядка (из-за существенной осцилляции таких моделей).
Используя возможности, предоставляемые вкладкой «Параметры», имеет смысл показать на диаграмме величину коэффициента детерминации R2 (в Microsoft Excel его называют достоверностью аппроксимации), показать уравнение линии тренда, а также задать необходимость рассчитать прогнозное значение временного ряда в 2017 году (18 периоде).
Пример построения графика зависимости (рис. 1).
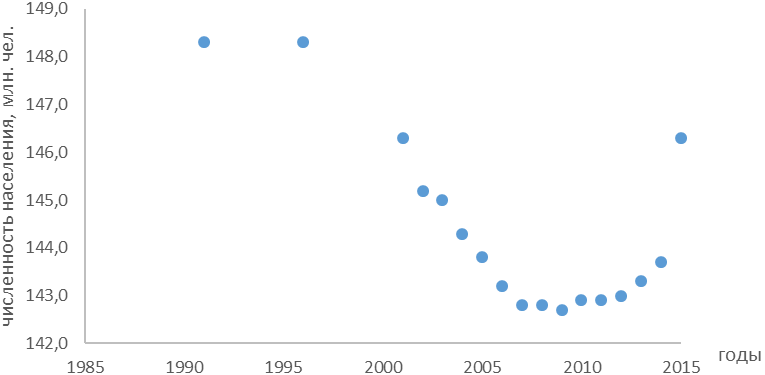
Рисунок 1 – Динамика численности населения за 1992-2015 гг.
Результаты перебора уравнений следует привести в таблице, отразив в ней рассчитанные табличным процессором значения коэффициентов детерминации R2, в соответствии с нижеприведённым образцом (табл. 1.).
Таблица 1- Результаты перебора уравнений регрессии
Вид уравнения | Уравнение | Коэффициент детерминации R2 |
Экспоненциальное | y = 146,43e-0,002x | RІ = 0,3693 |
Линейное | y = -0,2265x + 146,44 | RІ = 0,3696 |
Логарифмическое | y = -1,881ln(x) + 148,11 | RІ = 0,6332 |
Полином 2-го порядка | y = 0,0646x2 - 1,3898x + 150,12 | RІ = 0,9414 |
Полином 3-го порядка | y = 0,0019x3 + 0,013x2 - 1,0071x + 149,47 | RІ = 0,9505 |
Степенное | y = 148,12x-0,013 | RІ = 0,6318 |
Из таблицы 1 видно, что наибольшее значение коэффициента детерминации соответствует уравнению полинома 3-го порядков функции (RІ = 0,9505) и уравнению полинома 2-го порядка функции (RІ = 0,9414). Для проверки возьмем полином 3-порядка.
На рис. 2 показана динамика изменения численности населения во времени (исходные данные примера): линия тренда, соответствующая полиному 3-го порядка, аппроксимирующий заданный временной ряд, а также параметры уравнения тренда и коэффициент детерминации.
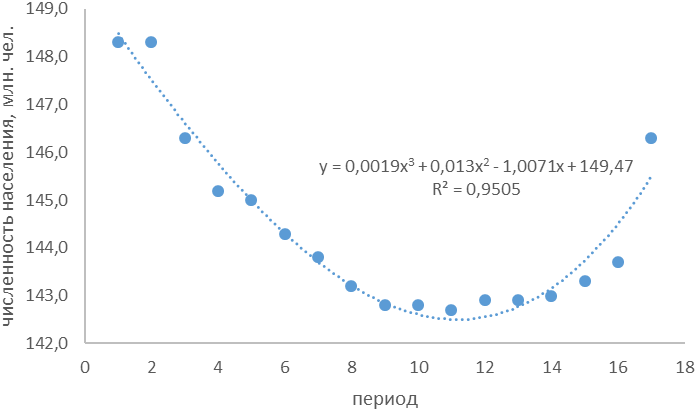
Рисунок 2 – Временной ряд численности населения
После нахождения уравнения регрессии, необходимо провести статистический анализ результатов. Этот анализ заключается:
1) в проверке значимости всех коэффициентов регрессии;
2) в проверке адекватности уравнения регрессии.
Надо понимать, что табличный процессор Microsoft Excel не является специализированной программой для статистической обработки информации. Поэтому Excel не даёт пользователю возможности оценить значимость коэффициентов уравнения регрессии и принять решение об исключении незначимых коэффициентов. Кроме того, табличный процессор выдаёт единственный критерий для проверки адекватности модели - коэффициент детерминации R2.
Это обстоятельство существенно обесценивает Microsoft Excel как инструмент обработки рядов динамики, однако, этот недостаток можно игнорировать и использовать другие приёмы проверки адекватности модели, например, анализ остатков на подчинение их распределения нормальному закону (часто называемому законом Гаусса).
Студенту предлагается вынести суждение о существенности или несущественности расхождения между эмпирическим и теоретическим (нормальным) распределениями на основе критерия согласия ч2 (хи-квадрат) Пирсона. Исходя из числа степеней свободы k = n – 1 и рассчитанных теоретических частот нормального распределения, имеющаяся в Excel статистическая функция ХИ2ТЕСТ рассчитывает вероятность Р(ч2).
При Р(ч2) > 0,5 считается, что эмпирическое и теоретическое распределения близки, при 0,2< Р(ч2) < 0,5 совпадение признают удовлетворительным, в остальных случаях - недостаточным.
Для реализации этого приёма средствами Microsoft Excel следует (для функции, показавшей максимальное значение коэффициента детерминации R2):
1) рассчитать остатки - разности между наблюдаемыми уi и предсказанными yipacч;
построить вариационный ряд распределения остатков с равными закрытыми интервалами, разбив ряд на 7-8 групп, дополнив полученную групповую таблицу столбцами «Частота», и «Середина интервала»; рассчитать среднее арифметическое взвешенное остатков и стандартное отклонение; на основе вышеназванных параметров вычислить значения функции плотности нормального распределения (используя статистическую функцию НОРМРАСП); рассчитать теоретические частоты нормального распределения; используя статистическую функцию ХИ2ТЕСТ, рассчитать вероятность Р(ч2); оценив полученное значение вероятности Р(ч2), сформулировать вывод о подчинении распределения остатков нормальному закону, и, как следствие, вывод об адекватности выбранной модели тренда.Продемонстрируем пример такого расчёта, в соответствии с изложенным алгоритмом:
Расчёт остатков:Параллельно столбцу с заданными (наблюдаемыми) значениями (у;), построим:
- столбец значений (yipacч) по уравнению регрессии, показавшему наилучшие значения R2; столбец значений остатков (уi - yipacч).
Рассчитанные, по выбранному уравнению тренда, значения численности населения представлены в таблице 3. Там отражены исходные данные и рассчитанные значения остатков.
Таблица 3 - Временной ряд численности населения yi, значения yipacч., рассчитанные по управлению полиномом 3-его порядка, и остатки (уi - yipacч.)
№ п/п | yi | yipacч. | уi - yipacч |
1 | 148,3 | 148,5 | -0,2 |
2 | 148,3 | 147,5 | 0,8 |
3 | 146,3 | 146,6 | -0,3 |
4 | 145,2 | 145,8 | -0,6 |
5 | 145,0 | 145,0 | 0,0 |
6 | 144,3 | 144,3 | 0,0 |
7 | 143,8 | 143,7 | 0,1 |
8 | 143,2 | 143,2 | 0,0 |
9 | 142,8 | 142,8 | 0,0 |
10 | 142,8 | 142,6 | 0,2 |
11 | 142,7 | 142,5 | 0,2 |
12 | 142,9 | 142,5 | 0,4 |
13 | 142,9 | 142,7 | 0,2 |
14 | 143,0 | 143,1 | -0,1 |
15 | 143,3 | 143,7 | -0,4 |
16 | 143,7 | 144,5 | -0,8 |
17 | 146,3 | 145,4 | 0,9 |
Таблица 4 – Ранжированный по остаткам (yi - yipacч.) временной ряд численности населения для случая аппроксимации полиномом третьего порядка.
№ п/п | yi | yipacч. | уi - yipacч |
16 | 143,7 | 144,5 | -0,8 |
4 | 145,2 | 145,8 | -0,6 |
15 | 143,3 | 143,7 | -0,4 |
3 | 146,3 | 146,6 | -0,3 |
1 | 148,3 | 148,5 | -0,2 |
14 | 143,0 | 143,1 | -0,1 |
9 | 142,8 | 142,8 | 0,0 |
8 | 143,2 | 143,2 | 0,0 |
6 | 144,3 | 144,3 | 0,0 |
5 | 145,0 | 145,0 | 0,0 |
7 | 143,8 | 143,7 | 0,1 |
13 | 142,9 | 142,7 | 0,2 |
10 | 142,8 | 142,6 | 0,2 |
11 | 142,7 | 142,5 | 0,2 |
12 | 142,9 | 142,5 | 0,4 |
2 | 148,3 | 147,5 | 0,8 |
17 | 146,3 | 145,4 | 0,9 |
Обнаружив наибольшее и наименьшее значения (уi - yipacч), рассчитаем ширину интервала для вариационного ряда, состоящего из восьми групп, по формуле:
h=[(yi - yiрасч)max - (yi - yiрасч)min]/8
При построении вариационного ряда остатков, представляющего собой групповую таблицу, требуется обозначить верхнюю и нижнюю границы каждого из восьми интервалов. Так, например, для первого интервала, нижняя граница будет равна (yi - yiрасч)min, а верхняя граница (yi - yiрасч)min + h. Верхняя граница первого интервала, естественно, является нижней границей второго интервала.
Таблица 5 представляет собой фрагмент экрана табличного процессора, демонстрирующий подготовку данных для анализа остатков на нормальность распределения.
Таблица 5 – Вариационный ряд остатков и процедура анализа их распределения*
A | B | C | D | E | F | G | Н | 1 |
интервал | граница интервала | Набл. частоты | середина интервала | Квадрат отклонения | плотность норм | Теор. частоты округл. | 2 | |
нижняя | верхняя | |||||||
1 | -0,8 | -0,6 | 1 | -0,7 | 0,60 | 7,38395E-16 | 0 | 3 |
2 | -0,6 | -0,4 | 1 | -0,5 | 0,25 | 8,85818E-09 | 0 | 4 |
3 | -0,4 | -0,2 | 2 | -0,3 | 0,09 | 0,00085795 | 0 | 5 |
4 | -0,2 | 0,0 | 2 | -0,1 | 0,01 | 0,670874138 | 2 | 6 |
5 | 0 | 0,2 | 5 | 0,1 | 0,01 | 4,235279847 | 15 | 7 |
6 | 0,2 | 0,4 | 3 | 0,3 | 0,09 | 0,215866382 | 1 | 8 |
7 | 0,4 | 0,6 | 1 | 0,5 | 0,25 | 8,8828E-05 | 0 | 9 |
8 | 0,6 | 0,8 | 2 | 0,7 | 0,49 | 2,95105E-10 | 0 | 10 |
18 | 11 | |||||||
12 | ||||||||
сумма частот | среднее арифметическая | стандартное отклонение | Вероятность Р(ч2) | 13 | ||||
17 | 0,1 | 0,10 | 0 | 14 |
* в таблице значения приводить с точностью 4 знака после запятой.
Можно видеть, что ячейки A3 - А10 содержат номера интервалов (от 1 до 8), ячейки В3 - В10 отображают нижние границы, а ячейки С3 - С10 - верхние границы соответствующих интервалов.
Столбец D - «Наблюдаемые частоты» - заполняется по результатам рассмотрения ранжированного ряда остатков: в ячейках D3 - D10 указано число значений этого ряда, попавших в соответствующий интервал.
В массиве Е3:Е10 рассчитываются середины соответствующих интервалов как полусумма верхней и нижней границ: например, в ячейке Е3 содержится формула =(В3+С3) / 2.
В ячейке D14 рассчитывается сумма наблюдаемых частот, то есть содержится формула =СУММ(Б3: D10) - как для промежуточного контроля (сумма частот, в нашем случае, равна 17), так и для дальнейших расчётов.
3) Расчёт средней арифметической взвешенной остатков и стандартного отклонения
В ячейке Е14 рассчитывается средняя арифметическая полученного вариационного ряда, то есть содержится формула = СУММПРОИЗВ(D3:D10;Е3:Е10)/D15.
Обратите внимание на процедуру расчёта:
наблюдаемая частота для соответствующего интервала умножается на значение середины интервала; произведения суммируются; делятся на сумму частот.В ячейках F3-F10 рассчитываются квадраты отклонений середин соответствующих интервалов от средней арифметической, например, для F3: (Е3-Е14)^2, для F4: (Е4-Е14)^2 и т. д.
В ячейке F14 рассчитывается стандартное отклонение остатков по законам вариационных рядов. Формула в ячейке F14: =КОРЕНЬ(СУММПРОИЗВ(D3:D10;F3:F10)/D14).
Обратите внимание на процедуру расчёта:
4) Вычисление значений функции плотности нормального распределения с использованием статистической функции НОРМРАСП
В массиве G3:G10 рассчитываются значения функции плотности нормального распределения в соответствии с формулой: =НОРМРАСП(X;Среднее;Станд. откл;Интеграль-ная).
Раскроем синтаксис этой функции: здесь X - значение середины интервала, для которого вычисляется плотность нормального распределения; Среднее - средняя арифметическая вариационного ряда; Станд. откл - стандартное отклонение вариационного ряда; Интегральная - логическая величина (устанавливают «0» - если требуется рассчитать дифференциальную функцию распределения или «1»- если требуется рассчитать интегральную функцию). Таким образом, в ячейке G3 рассчитывается функция: =НОРМРАСП(ЕЗ;Е14;F14;0)
Соответственно, в ячейке G4 рассчитывается функция: =НОРМРАСП(Е4;Е14;F14;0)
Расчёт теоретических частот нормального распределенияВ массиве Н3:Н10 по значениям
а) плотности нормального распределения для каждого интервала,
b) ширины интервала
с) суммы частот вариационного ряда
рассчитываются теоретические частоты нормального распределения.
Так, например, в ячейке Н3 размещена формула: =G3*h*D14, где h - ширина интервала.
Ячейки Н3 – Н10 форматированы как числовые, без десятичных знаков. Это позволяет видеть округлённые значения теоретических частот и сравнить их с наблюдаемыми частотами (для наглядности).
В ячейке Н11 размещена формула =СУММ(Н3:Н10) - для наглядности и промежуточного контроля. Сумма теоретических частот, в нашем случае, должна быть равна 17, хотя, из-за ошибок округления, может незначительно отличаться.
Расчёт вероятности Р(ч2) с использованием статистической функции ХИ2ТЕСТ
В ячейке Н14 размещена формула: = XH2TECT(D3:D10;Н3: Н10).
Рассчитанное в этой ячейке значение Р(ч2) должно принадлежать интервалу от 0 до 1. Таким образом, Exel, с помощью функции ХИ2ТЕСТ производит сравнение массивов наблюдаемых и теоретических частот распределения.
Оценка рассчитанного значения вероятности Р(ч2)
При Р(ч2) > 0,5 считается, что:
а) эмпирическое и теоретическое распределения частот близки;
b) признаётся, что распределение остатков подчиняется нормальному закону;
с) делают вывод об адекватности выбранной модели тренда.
При 0,2< Р(ч2) < 0,5
а) совпадение признают удовлетворительным;
b) делают вывод об адекватности выбранной модели тренда (с оговоркой о значении вероятности Р(ч2)).
При Р(ч2) < 0,2
а) совпадение признают недостаточным;
b) делают вывод о неадекватности выбранной модели тренда;
с) приступают к анализу остатков для другой модели, даже если рассчитанный для неё коэффициент детерминации R2 меньше, чем для отвергнутой модели.
Результаты обработки учащийся представляет в соответствующем разделе пояснительной записки к курсовой работе в следующем виде:
заданный временной ряд отображают в виде точечной диаграммы, отразив на ней график (выбранной в результате анализа) линии тренда, уравнение тренда и коэффициент детерминации R2; приводят таблицу с результатами перебора уравнений регрессии (пример - таблица 1); приводят таблицу, иллюстрирующую проведённую учащимся процедуру анализа остатков (пример - таблица 2) формулируют выводы, в которых следует показать выбранное аналитическое выражение линии тренда, коэффициент детерминации, охарактеризовать вид этого уравнения, подтвердить адекватность уравнения (упомянув результаты анализа остатков), привести результат расчёта прогнозного значения показателя на 2017 год (18 период).