

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Цель работы – получить представления о возможности библиотеки CCR для организации параллельных вычислений.
Задание на лабораторную работу:
1) разработайте последовательный алгоритм, решающий одну из приведённых ниже задач в соответствии с выданным вариантом задания;
2) разработайте параллельный алгоритм соответствующий варианту последовательного алгоритма;
3) выполните сравнение времени выполнения последовательного и параллельного алгоритмов обработки данных при различных размерностях исходных данных.
Задание: Разработать алгоритм сортировки массива
Для решения задачи сортировки эти три этапа выглядят так:
Сортируемый массив разбивается на две половины меньшего размера Каждая из получившихся половин сортируется отдельно любым алгоритмом. Два упорядоченных массива половинного размера соединяются в один.Листинг
using System;
using System. Collections;
using System. Diagnostics;
using System. Threading;
using System. Collections. Generic;
using ponentModel;
using Microsoft. Ccr. Core;
using Microsoft. Dss. Core. Attributes;
using Microsoft. Dss. ServiceModel. Dssp;
using Microsoft. Dss. ServiceModel. DsspServiceBase;
using W3C. Soap;
using submgr =Microsoft. Dss. bscriptionManager;
namespace labwork11
{
[Contract(Contract. Identifier)]
[DisplayName("labwork11")]
[Description("labwork11 service (no description provided)")]
class labwork11Service : DsspServiceBase
{
/// <summary>
/// Service state
/// </summary>
[ServiceState]
labwork11State _state = new labwork11State();
/// <summary>
/// Main service port
/// </summary>
[ServicePort("/labwork11", AllowMultipleInstances = true)]
labwork11Operations _mainPort = new labwork11Operations();
[SubscriptionManagerPartner]
bscriptionManagerPort _submgrPort = new bscriptionManagerPort();
/// <summary>
/// Service constructor
/// </summary>
///
public labwork11Service(DsspServiceCreationPort creationPort)
: base(creationPort)
{
}
/// <summary>
/// Service start
/// </summary>
///
protected override void Start()
{
//
// Add service specific initialization here
//
base. Start();
Console. WriteLine("Последовательный алгоритм");
//Здесь были типа глобальные переменные
Global. k = 20000;
Global. nc = 2; // число ядер
Global. m = Global. k / Global. nc; //
Global. s = Global. k / Global. nc;
Global. A = new int[Global. k];
// заполнение массива
Random r = new Random();
for (int i = 0; i < Global. k; i++)
Global. A[i] = r. Next(100);
//последовательный алгоритм
Stopwatch sWatch = new Stopwatch();
sWatch. Start();
int step11 = 0;
for (int ii = 0; ii < Global. nc; ii++)
{
for (int i = 0+step11; i < Global. k / Global. nc+step11; i++)
for (int j = 0+step11; j < (Global. k / Global. nc+step11 - i - 1) ; j++)
if (Global. A[j] > Global. A[j + 1])
{
int tmp;
tmp = Global. A[j];
Global. A[j] = Global. A[j + 1];
Global. A[j + 1] = tmp;
}
step11 =ii*Global. k / Global. nc;
}
sWatch. Stop();
Console. WriteLine(" Последовательный алгоритм= {0} .", sWatch. ElapsedMilliseconds. ToString());
for (int i = 0; i < Global. k; i++)
for (int j = 0; j < Global. k - i-1; j++)
if (Global. A[j] > Global. A[j + 1])
{
int tmp;
tmp = Global. A[j];
Global. A[j] = Global. A[j + 1];
Global. A[j + 1] = tmp;
}
Console. WriteLine("Выборка для котроля");
foreach (int number in PrintArray(5,Global. A))
{
Console. Write(number. ToString() + " ");
}
////////////////////////////////////////////////////////////////////// параллельный алгоритм
Console. WriteLine("Конец последовательного алоритма");
Console. WriteLine("Параллельный алгоритм");
// создание массива объектов для хранения параметров
InputData[] ClArr = new InputData[Global. nc];
for (int i = 0; i < Global. nc; i++)
ClArr[i] = new InputData();
// делим количество элементов на nc частей
int step = (Int32)(Global. k / Global. nc);
// заполняем массив параметров
int c = -1;
for (int i = 0; i < Global. nc; i++)
{
ClArr[i].start = c + 1;
ClArr[i].stop = c + step;
c = c + step;
for (int j = ClArr[i].start; j < ClArr[i].stop - 1; j++)
{
int kkk = 0;
ClArr[i].B[kkk] = Global. A[j];
kkk++;
}
}
Dispatcher d = new Dispatcher(Global. nc, "Test Pool");
DispatcherQueue dq = new DispatcherQueue("Test Queue", d);
Port<int> p = new Port<int>();
for (int i = 0; i < Global. nc; i++)
Arbiter. Activate(dq, new Task<InputData, Port<int>>(ClArr[i], p, Mul));
Arbiter. Activate(Environment. TaskQueue, Arbiter. MultipleItemReceive(true, p, 2,
delegate(int[] array)
{
for (int i = 0; i < Global. nc; i++)
{
for (int j = ClArr[i].start; j < ClArr[i].stop - 1; j++)
{
int kkk = 0;
Global. A[j] = ClArr[i].B[kkk];
kkk++;
}
}
}));
Console. WriteLine("Реализация итераторов");
InputData1[] ClArr1 = new InputData1[Global. nc];
for (int i = 0; i < Global. nc; i++)
ClArr1[i] = new InputData1();
// делим количество элементов на nc частей
int step1 = (Int32)(Global. k / Global. nc);
// заполняем массив параметров
int c1 = -1;
for (int i = 0; i < Global. nc; i++)
{
ClArr1[i].start = c1 + 1;
ClArr1[i].stop = c1 + step1;
c1 = c1 + step1;
for (int j = ClArr1[i].start; j < ClArr1[i].stop-1; j++)
{
int kkk = 0;
ClArr1[i].B[kkk] = Global. A[j];
kkk++;
}
}
Dispatcher Disp = new Dispatcher(Global. nc, "Test Pool");
DispatcherQueue taskQ = new DispatcherQueue("Test Queue", Disp);
Port<int> p1 = new Port<int>();
Console. WriteLine("Before Iterator submitted - thread {0}", Thread. CurrentThread. ManagedThreadId);
for (int i = 0; i < Global. nc; i++)
{
Arbiter. ExecuteToCompletion(taskQ, new IterativeTask<Port<int>, InputData1>(p1, ClArr1[i], IteratorExample));
}
Arbiter. MultipleItemReceive(false, p1, 2 , delegate(int[] array)
{
for (int i = 0; i < Global. nc; i++)
{
for (int j = ClArr[i].start; j < ClArr[i].stop - 1; j++)
{
int kkk = 0;
Global. A[j] = ClArr[i].B[kkk];
kkk++;
}
}
Console. WriteLine("Вычисления окончены");
});
Console. WriteLine("After Iterator submitted - thread {0}", Thread. CurrentThread. ManagedThreadId);
}
/// <summary>
/// Handles Subscribe messages
/// </summary>
/// <param name="subscribe">the subscribe request</param>
[ServiceHandler]
public void SubscribeHandler(Subscribe subscribe)
{
SubscribeHelper(_submgrPort, subscribe. Body, subscribe. ResponsePort);
}
public class InputData
{
public int start; //Начало диапазона
public int stop; //Конец диапазона
public int[] B = new int[Global. k / Global. nc];
}
public class InputData1
{
public int start; //Начало диапазона
public int stop;
//Конец диапазона
public int[] B = new int[Global. k / Global. nc];
}
public static System. Collections. Generic. IEnumerable<int>
PrintArray(int firstNumber, int[] arr)
{
// Yield even numbers in the range.
for (int number = 0; number < 8000; )
{
number = number + 1000;
yield return arr[number];
}
}
//Итераторы
IEnumerator<ITask> IteratorExample(Port<int> resp, InputData1 data)
{
Stopwatch sWatch = new Stopwatch();
sWatch. Start();
for (int i = 0 ;i < Global. k/Global. nc; i++)
for (int j = 0; j < Global. k / Global. nc - i - 1; j++)
if (data. B[j] > data. B[j + 1])
{
int tmp;
tmp = data. B[j];
data. B[j] = data. B[j + 1];
data. B[j + 1] = tmp;
}
sWatch. Stop();
Console. WriteLine("P1 Thread {0}: {1}мс", Thread. CurrentThread. ManagedThreadId, sWatch. ElapsedMilliseconds. ToString());
resp. Post(1);
yield break;
}
void Mul(InputData data, Port<int> resp)
{ Stopwatch sWatch = new Stopwatch();
sWatch. Start();
for (int i = 0; i < Global. k / Global. nc; i++)
for (int j = 0; j < Global. k / Global. nc - i - 1; j++)
if (data. B[j] > data. B[j + 1])
{
int tmp;
tmp = data. B[j];
data. B[j] = data. B[j + 1];
data. B[j + 1] = tmp;
}
sWatch. Stop();
Console. WriteLine("№ {0}: Параллельный алгоритм = {1} мс.",
Thread. CurrentThread. ManagedThreadId, sWatch. ElapsedMilliseconds. ToString());
resp. Post(1);
}
}
class Global
{
public static int[] A;
public static int m;
public static int s;
public static int k;
public static int nc;
}
}
Результат работы программы
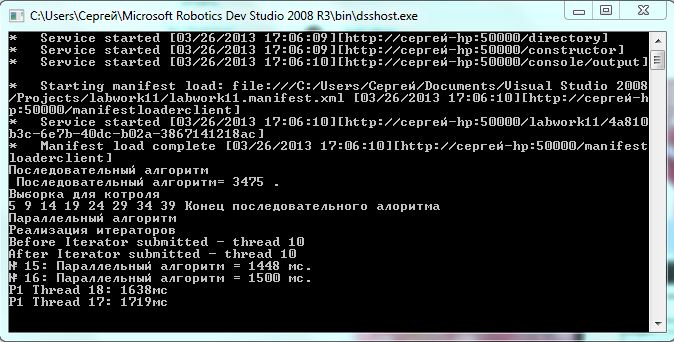
Вывод
Проделав данную работу, я разработал последовательный и параллельный алгоритмы для сортировки массива слиянием.
Как показал ряд опытов, распараллеливание на 2 потока позволяет решать поставленную задачу в 1,5 – 2 раза быстрее (эффективность можно увидеть в тестовом примере), чем при последовательной обработке данных. Также было реализовано распараллеливание с помощью итераторов
Опытным путем установлено, что для малых нагрузок распараллеливание существенной роли не играет, поэтому рациональнее его использовать при больших нагрузках.
