

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
а + а * Е => а + а * I => а + а * а
1т !т
б) Е => Е* Е => Е + Е* Е => 1+ Е* Е => а + Е* Е =>
lm lm lm /т 1т
а + I * Е => а + а * Е => а + а * / => а + а* а
lm 1т 1т
Заметим, что эти левые порождения различаются. Данный пример не доказывает теорему, но демонстрирует, как различия в деревьях разбора влияют на выбор шагов в левом порождении. □
Теорема 5.29. Для каждой грамматики G = (V, Т, Р, S) и w из Т' цепочка w имеет два разных дерева разбора тогда и только тогда, когда w имеет два разных левых порождения из S.
Доказательство. (Необходимость) Внимательно рассмотрим построение левого порождения по дереву разбора в доказательстве теоремы 5.14. В любом случае, если у двух деревьев разбора впервые появляется узел, в котором применяются различные продукции, левые порождения, которые строятся, также используют разные продукции и, следовательно, являются различными.
(Достаточность) Хотя мы предварительно не описали непосредственное построение дерева разбора по левому порождению, идея его проста. Начнем построение дерева с корня, отмеченного стартовым символом. Рассмотрим порождение пошагово. На каждом шаге заменяется переменная, и эта переменная будет соответствовать построенному крайнему слева узлу дерева, не имеющему сыновей, но отмеченному этой переменной. По продукции, использованной на этом шаге левого порождения, определим, какие сыновья должны быть у этого узла. Если существуют два разных порождения, то на первом шаге, где они различаются, построенные узлы получат разные списки сыновей, что гарантирует различие деревьев разбора. □
5.4.4. Существенная неоднозначность
Контекстно-свободный язык L называется существенно неоднозначным, если все его грамматики неоднозначны. Если хотя бы одна грамматика языка L однозначна, то L является однозначным языком. Мы видели, например, что язык выражений, порождаемый грамматикой, приведенной на рис. 5.2, в действительности однозначен. Хотя данная грамматика и неоднозначна, этот же язык задается еще одной грамматикой, которая однозначна — она изображена на рис. 5.19.
Мы не будем доказывать, что существуют неоднозначные языки. Вместо этого рассмотрим пример языка, неоднозначность которого можно доказать, и объясним неформально, почему любая грамматика для этого языка должна быть неоднозначной:
L = {a"bncmdm | п> 1, т > 1} U {апЬтстсГ | п> 1, т > 1}.
Из определения видно, что L состоит из цепочек вида a+b+c+d+, в которых поровну символов а и Ь, а также cud, либо поровну символов а и d, а также Ьис.
L является КС-языком. Очевидная грамматика для него показана на рис. 5.22. Для порождения двух видов цепочек в ней используются два разных множества продукций.
Эта грамматика неоднозначна. Например, у цепочки aabbccdd есть два следующих левых порождения.
S => АВ => аАЬВ => aabbB => aabbccBd => aabbccddIm Im Im Im Im
S => С => aCd => aaDdd => aabDcdd => aabbccddlm Im lm lm Im
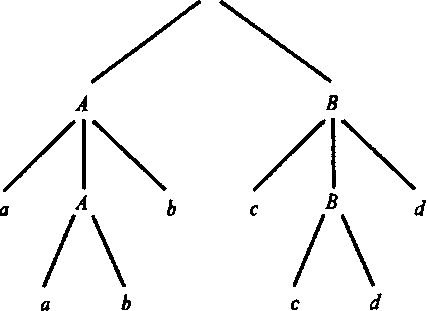
Соответствующие деревья разбора показаны на рис. 5.23.
S | -» | АВ | С |
А | -» | аАЬ | ab |
В | cBd|cd | |
С | aCd | aDd | |
D | -» | bDc | be |
Рис. 5.22. Грамматика для существенно неоднозначного языка
![]()
![]()
![]()
Л
а) б)
Рис. 5.23. Два дерева разбора для aabbccdd
Доказательство того, что все грамматики для языка L неоднозначны, весьма непросто, однако сущность его такова. Нужно обосновать, что все цепочки (за исключением конечного их числа), у которых поровну всех символов, должны порождаться двумя различными путями. Первый путь — порождение их как цепочек, у которых поровну символов а и b, а также с и d, второй путь — как цепочек, у которых поровну символов а и d, как ибис.
Например, единственный способ породить цепочки, у которых поровну а и Ь, состоит в использовании переменной, подобной А в грамматике, изображенной на рис. 5.22. Конечно же, возможны варианты, но они не меняют картины в целом, как это видно из следующих примеров.
- Некоторые короткие цепочки могут не порождаться после изменения, например, базисной продукции А —» ab на А —» aaabbb. Мы могли бы организовать продукции так, чтобы переменная А делила свою работу с другими, например, используя переменные А, и Л2, из которых А/ порождает нечетные количества символов а, а А2— четные: AjaA2b\ ab; А2 aAjb | ab. Мы могли бы организовать продукции так, чтобы количества символов а и Ь, порождаемые переменной А, были не равны, но отличались на некоторое конечное число. Например, можно начать с продукции S—>AaB и затем использовать А —» аАЬ | а для порождения символов а на один больше, чем Ь.
В любом случае, нам не избежать некоторого способа порождения символов а, при котором соблюдается их соответствие с символами Ь.
Аналогично можно обосновать, что должна использоваться переменная, подобная В, которая порождает соответствующие друг другу символы с и d. Кроме того, в грамматике должны быть переменные, играющие роль переменных Си Д порождающих соответственно парные а и d и парные b и с. Приведенные аргументы, если их формализовать, доказывают, что независимо от изменений, которые можно внести в исходную грамматику, она будет порождать хотя бы одну цепочку вида a"bncn<f двумя способами, как и грамматика, изображенная на рис. 5.22.
5.4.5. Упражнения к разделу 5.4
Рассмотрим грамматику S —» aS | aSbS | е. Она неоднозначна. Докажите, что для цепочки aab справедливо следующее:а) для нее существует два дерева разбора;
б) она имеет два левых порождения;
в) она имеет два правых порождения.
(!) Докажите, что грамматика из упражнения 5.4.1 порождает те, и только те цепочки из символов а и Ь, у которых в любом префиксе символов а не меньше, чем Ь. (*!) Найдите однозначную грамматику для языка из упражнения 5.4.1. (!!)В грамматике из упражнения 5.4.1 некоторые цепочки имеют только одно дерево разбора. Постройте эффективную проверку, является ли цепочка однойиз указанных. Проверка типа "проверить все деревья разбора, чтобы увидеть, сколько их у данной цепочки" не является достаточно эффективной.
(!) Воспроизведем грамматику из упражнения 5.1.2:5 -» А\В А OA | Е В 05 | 16 |Ј
а) докажите, что данная грамматика неоднозначна;
б) найдите однозначную грамматику для этого же языка и докажите ее однозначность.
(*!) Однозначна ли ваша грамматика из упражнения 5.1.5? Если нет, измените ее так, чтобы она стала однозначной. Следующая грамматика порождает префиксные выражения с операндами х иу и операторами +, - и *:Е-ч> + ЕЕ\* ЕЕ\-ЕЕ\х\у
а) найдите левое и правое порождения, а также дерево разбора для цепочки
+ *-хуху;
б) (!) докажите, что данная грамматика однозначна.
Резюме
- Контекстно-свободные грамматики. КС-грамматика— это способ описания языка с помощью рекурсивных правил, называемых продукциями. КС-грамматика состоит из множества переменных, терминальных символов, стартовой переменной, а также продукций. Каждая продукция состоит из головной переменной и тела— цепочки переменных и/или терминалов, возможно, пустой. Порождения и языки. Начиная со стартового символа, мы порождаем терминальные цепочки, повторяя замены переменных телами продукций с этими переменными в голове. Язык КС-грамматики— это множество терминальных цепочек, которые можно породить; он называется КС-языком. Левые и правые порождения. Если мы всегда заменяем крайнюю слева (крайнюю справа) переменную, то такое порождение является левым (правым). Каждая цепочка в языке КС-грамматики имеет, по крайней мере, одно левое и одно правое порождения. Выводимые цепочки. Любой шаг порождения дает цепочку переменных и/или терминалов. Она называется выводимой цепочкой. Если порождение является левым (правым), то цепочка называется левовыводимой (правовыводимой). Деревья разбора. Дерево разбора — это дерево, показывающее сущность порождения. Внутренние узлы отмечены переменными, листья— терминалами или е. Для каждого внутреннего узла должна существовать продукция, голова которой является отметкой узла, а отметки сыновей узла, прочитанные слева направо, образуют ее тело. Эквивалентность деревьев разбора и порождений. Терминальная цепочка принадлежит языку грамматики тогда и только тогда, когда она является кроной, по крайней мере, одного дерева разбора. Таким образом, существование левых порождений, правых порождений и деревьев разбора является равносильным условием того, что все они определяют в точности цепочки языка КС-грамматики. Неоднозначные грамматики. Для некоторых грамматик можно найти терминальную цепочку с несколькими деревьями разбора, или (что равносильно) с несколькими левыми или правыми порождениями. Такая грамматика называется неоднозначной. Исключение неоднозначности. Для многих полезных грамматик, в частности, описывающих структуру программ в обычных языках программирования, можно найти эквивалентные однозначные грамматики. К сожалению, однозначная грамматика часто оказывается сложнее, чем простейшая неоднозначная грамматика для данного языка. Существуют также некоторые КС-языки, обычно специально сконструированные, которые являются существенно неоднозначными, т. е. все грамматики для этих языков неоднозначны. Синтаксические анализаторы. Контекстно-свободная грамматика является основным понятием для реализации компиляторов и других процессоров языков программирования. Инструментальные средства, вроде YACC, получают на вход КС-грамматику и порождают синтаксический анализатор — часть компилятора, распознающую структуру компилируемых программ. Определения типа документа. Развивающийся стандарт XML для распределения информации посредством Web-документов имеет нотацию, называемую DTD, для описания структуры таких документов. Для этого в документ записываются вложенные семантические дескрипторы. DTD является, по существу, КС-грамматикой, язык которой — это класс связанных с этим определением документов.
Литература
Контекстно-свободная грамматика была впервые предложена Хомским как способ описания естественных языков в [4]. Бэкус и Наур вскоре использовали подобную идею для описания машинных языков Фортран [2] и Алгол [7]. В результате КС-грамматики иногда называются "формами Бэкуса-Наура", или БНФ.
Неоднозначность в грамматиках была выделена в качестве проблемы почти одновременно Кантором [3] и Флойдом [5]. Существенная неоднозначность была впервые указана Гроссом [6].
О приложениях КС-грамматик в компиляции рекомендуем прочитать в [1]. DTD описаны в документе о стандартах XML [8].
- А. V. Aho, R. Sethi, and J. D. Ullman, Compilers: Principles, Techniques, and Tools, Addison-Wesley, Reading MA, 1986. (, Сети P., Ульман Дж. Компиляторы: принципы, технологии и инструменты. — М.: Издательский дом "Вильяме", 2001.) J. W. Backus, "The syntax and semantics of the proposed international algebraic language of the Zurich ACM-GAMM conference", Proc. Intl. Conf. on Information Processing (1959), UNESCO, pp. 125-132. D. C. Cantor, "On the ambiguity problem of Backus systems", J. ACM 9:4 (1962), pp. 477-479. N. Chomsky, "Three models for the description of language", IRE Trans, on Information Theory 2:3 (1956), pp. 113-124. (Хомский H. Три модели для описания языка. — Кибернетический сборник, вып. 2. — М.: ИЛ, 1961. — С. 237-266.) R. W. Floyd, "On ambiguity in phrase-structure languages", Comm. ACM 5:10 (1962), pp. 526-534. M. Gross, "Inherent ambiguity of minimal linear grammars", Information and Control 7:3 (1964), pp. 366-368. P. Naur et al., "Report on the algorithmic language ALGOL 60", Comm. ACM3:5 (1960), pp. 299-314. См. также Comm. ACM6A (1963), pp. 1-17. (Алгоритмический язык Алгол 60,—M.: Мир, 1965.) World-Wide-Web Consortium, http://www. w3.org/TR/REC-xml (1998)
1 Будем употреблять также термины "регулярные операции" и "регулярные операторы", принятые в русскоязычной литературе. — Прим. ред.
2 Термин "замыкание Клини" связан с именем , который ввел понятие регулярного
выражения и, в частности, эту операцию.
4 В UNIX точка в регулярных выражениях используется для совершенно другой цели — представления любого знака кода ASCII.
5 Преимущество обозначения [: digit: ] состоит в том, что если вместо кода ASCII используется другой, в котором коды цифр расположены не по порядку, то [: digi t: ] все так же будет обозначать [0123456789], тогда как [0-9] будет представлять все символы, коды которых находятся в промежутке между кодами для 0 и для 9 включительно.
6 Как следствие, отметим, что любой язык коммутирует со своей итерацией: LZ,* = Ь'Ь. Это свойство не противоречит тому, что в общем случае конкатенация не является коммутативной.
7 Для простоты отождествим регулярные выражения с их языками, чтобы не повторять фразу "язык выражения" перед каждым регулярным выражением.
8 В русскоязычной литературе в свое время был принят термин "лемма о разрастании". Однако, на наш взгляд, -'накачка" точнее отражает суть происходящего. — Прим. ред.
9 Иными словами, это двоичные записи простых чисел. — Прим. ред. 148 ГЛАВА 4. СВОЙСТВА РЕГУЛЯРНЫХ ЯЗЫКОВ
10 Под "Т" подразумевается прописная буква греческого алфавита "тау", следующая за буквой "сигма".
11 Обсуждение алгоритмов транзитивного замыкания можно найти в книге А. V. Aho, J. Е. Hopcroft, and J. D. Ullman, Data Structures and Algorithms, Addison-Wesley, 1984. (A. Axo, Дж. Хопкрофт, Дж. Ульман. Структуры данных и алгоритмы, М.: Издательский дом "Вильяме", 2000.)
12 Методы анализа, с помощью которых можно выполнить эту задачу за время О(п), обсуждаются в книге А. V. Aho, R. Sethi, and J. D. Ullman, Compiler Design: Principles, Tools, and Techniques, Addison-Wesley, 1986. (A. Ахо, P. Сети, Дж. Ульман. Компиляторы: принципы, инструменты и технологии, М.: Издательский дом "Вильяме", 2001.)
13 Нужно помнить, что один и тот же блок может формироваться несколько раз, начиная с разных состояний. Однако разбиение состоит из различных блоков, так что каждый блок встречается в разбиении только один раз.
14 В действительности, именно эта возможность подстановки строки вместо переменной независимо от контекста и породила название "контекстно-свободная" (context-free). Существует более мощный класс грам-матик, называемых "контекстно-зависимыми" (context-sensitive), в которых подстановки разрешены, только если определенные строки находятся слева и/или справа от заменяемой переменной. В современной практике контекстно-зависимые грамматики большого значения не имеют.
14 Наше обсуждение нахождения подпорождений из больших порождений предполагало, что мы имели дело с переменными второй выводимой цепочки некоторого порождения. Однако идея применима к переменной на любом шаге порождения.
15 Иногда введение признака <х> несет в себе больше информации, чем просто имя х для признака. Однако мы не рассматриваем в примерах эту возможность.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
