


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа № 1. Составление частотного словаря документа.
Цель и содержание работы: научить студентов составлять частотный словарь документа и выбирать для поиска информации значимые слова в соответствии с их рангом.
Теоретическое обоснование
Рассмотрим любой текст. Для каждого слова можно подсчитать, сколько раз оно встречается в тексте. Эта величина называется частотой вхождения слова. Из терминов, входящих в документ или в текст, можно составить словарь. Для этого все слова нужно нормализовать и без повторений расположить в алфавитном порядке. Обозначим частоту вхождения слова в текст fi, номер слова – i. Исходный частотный словарь документа представлен в таблице 1. В графа «номер слова» соответствует порядковому номеру слова в словаре. Графа «слово» содержит неповторяющиеся слова. D – количество слов в словаре.
Таблица 1- Исходный частотный словарь
Номер слова (i) | Слово | Частота вхождения слова (f i) |
1 | t1 | f1 |
2 | t2 | f2 |
... | ... | |
i | ti | fi |
... | ... | ... |
D | tD | fD |
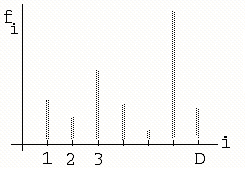
График зависимости fi от i, представленный на рисунке 1, не обнаруживает каких-либо закономерностей, связывающих i и fi.
|
Рисунок 1 – Зависимость частоты вхождения слова от его номера |
Перенумеруем записи в таблице 1 таким образом, чтобы частота вхождения слова в текст была невозрастающей функцией его номера. Для этого порядковый «номер слова», используемый в таблице 1, описывающей исходный частотный словарь, заменим «рангом», или порядковым номером в последовательности убывающих частот слов. В отсортированном таким образом словаре, представленном в таблице 2, частоты вхождения слов удовлетворяют неравенству
|
В результате сортировки получим таблицу 2, в которой записи упорядочены по убыванию параметра fr.
Таблица 2. Отсортированный частотный словарь
Ранг (r) | Слово | Частота вхождения слова (fr ) |
1 | t1 | f1 |
2 | t2 | f2 |
... | ... | |
r | tr | fr |
... | ... | ... |
D | tD | fD |
Отсортированная последовательность образует “ранговое распределение”, в котором обнаруживается взаимосвязь между рангом (r) и частотой (fr). Эта взаимосвязь (закон Ципфа) приближенно описывается одним из следующих выражений:
- аппроскимация с одним параметром (С):
| (1) |
- аппроскимация с двумя параметрами (С,γ):
| (2) |
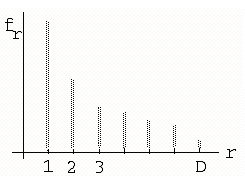
Выражение (1) является формулой гиперболической зависимости, поэтому принято говорить, что закон Ципфа удовлетворяет "гиперболическому ранговому распределению". График рангового распределения представлен на рисунке 2. По оси абсцисс на рисунке 2 отложены значения r – ранга слова (порядкового номера в последовательности убывающих частот слов).
|
Рисунок 2 – Ранговое распределение |
Закон Ципфа приобретает наглядную форму, если от обычных координат перейти к билогарифмическим ![]() . В аналитической форме выражение (1) тогда примет вид:
. В аналитической форме выражение (1) тогда примет вид:
| (3) |
а выражение (2) вид:
| (4) |
Данные выражения описывают прямые линии с одним или с двумя параметрами.
Параметры C и γ можно определить по результатам наблюдений. Для этого воспользуемся методов наименьших квадратов и составим выражение:
| (5) |
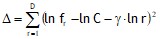
Наилучшая аппроксимация экспериментальных данных прямой линией осуществляется при минимизации ![]() :
:
| (6) |
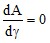 ,
, Это приводит к выражениям:
| (7) |
| (8) |
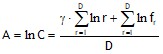 ,
, 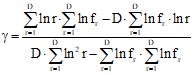
Анализ зависимости частоты слов от ранга для всех известных языков показал, что закон Ципфа универсален. Параметры C и γ, вычисленные для любых текстов, имеют постоянное значение для каждой группы языков.
Таблица 3 - Результаты вычислений при исследовании закона Ципфа
r | tr | fr | lnr | lnfr | lnr* lnfr | ln2r | fрасчет |
1 | t1 | f1 | 0 | lnf1 | 0 | 0 | f1 расчет |
2 | t2 | f2 | ln2 | lnf2 | ln2*lnf2 | ln22 | f2 расчет |
. r . . D | . tr . . tD | . fD . . fD | . lnr . . lnD | . lnfr . . lnfD | . lnr* lnfr . . lnD* lnfD | . ln2r . . ln2D | . fr расчет . . fD расчет |
|
|
|
| Δост |
Анализ зависимости частоты слов от ранга для всех известных языков показал, что закон Ципфа универсален. Наиболее значимые слова находятся в средней части графика зависимости частоты от ранга. Слова, которые встречаются в тексте наиболее часто, в основном, являются предлогами, местоимениями, в английском языке - артиклями. Редко встречающиеся слова для информационного поиска решающего значения не имеют. Основу современных методов автоматического индексирования составляет присваивание весовых характеристик терминам на основе статистических характеристик. Вес термина Tj в документе Ai определяется соотношением:
wij=fj*log(N/Nj),
где ![]() N – число документов в исследуемой совокупности, Nj - число документов, содержащих термин Tj, fj – частота вхождения термина Tj в документ Ai. Значение log(N/Nj) тем меньше, чем чаще слово встречается в исследуемой совокупности документов. Высокие значения wij приобретают наиболее значимые для информационного поиска термины.
N – число документов в исследуемой совокупности, Nj - число документов, содержащих термин Tj, fj – частота вхождения термина Tj в документ Ai. Значение log(N/Nj) тем меньше, чем чаще слово встречается в исследуемой совокупности документов. Высокие значения wij приобретают наиболее значимые для информационного поиска термины.
Методика и порядок выполнения работы
Для выполнения задания воспользуемся текстом одной из книг из списка рекомендованной литературы. Нужно выбрать текст, который начинается на тех страницах, последние цифры которых совпадают с номером зачетной книжки студента. После выбора начала текста следует ограничить объем отрывка текста таким образом, чтобы он содержал 200 слов, включая все слова, в том числе союзы и предлоги. Для каждого слова нужно подсчитать, сколько раз это слово встречается в тексте (документе). После этого из выбранных слов составить частотный словарь и заполнить ими таблицу 1. При заполнении таблицы использовать теоретическое обоснование.
Задания к лабораторной работе № 1
Составить частотный словарь документа, состоящий из не менее, чем 200 слов. Получить таблицы 1 и 2 для вашего задания и график рангового распределения (рисунок 2).
Содержание отчета и его форма
Отчет по лабораторной работе должен состоять из:
1) названия лабораторной работы;
2) ответов на контрольные вопросы;
3) формулировки заданий к лабораторной работе и порядка их выполнения.
Отчет о выполнении лабораторной работы в письменном виде сдается преподавателю.
Вопросы для защиты работы
Каким образом составляется исходный словарь документов? Как составить отсортированный словарь документов?Литература
а) основная литература:
Информационные ресурсы и системы: реализация, моделирование, управление. - М.: ТПК “Альянс”, 2006. , , Информационные системы / Под общей редакцией . - М.: Изд-во Рос. экон. акад., 2009. - 198 с. и др. Справочник по вероятностным расчетам. - М.: МО, 2010.1. Информационные системы в экономике. Под ред. 2-е изд., перераб. и доп. – М.: Юнити-Дана, 2008. – 463 с.
2. , Информационные системы в экономике: Учебник. – 5-е изд. – М.: Издательско-торговая корпорация «Дашков и Ко», 2008. – 395 с.
3. Карминский A. M., Информационные системы в экономике: В 2-х ч. Ч. 1. Методология создания: Учеб. пособие. – М.: Финансы и статистика, 2006. – 336 с: ил.
4. Карминский A. M., Информационные системы в экономике: В 2-х ч. Ч. 2. Практика использования: Учеб. пособие. – М.: Финансы и статистика, 2006. – 240 с: ил.
б) дополнительная литература:
1. Excel 2003. Эффективный самоучитель – СПб.: Наука и Техника, 2005. – 400 с.: ил.
2. Информационные системы и технологии в экономике: Учебник./, , ; Под ред. . – М.: Финансы и статистика, 2003. – 416 с.
3. Информационные технологии в экономике и управлении: Учебник. Второе издание. – СПб.: Изд-во , 2001. – 360 с.
4. Автоматизированные информационные технологии в экономике: Учебник / Под ред. проф. . – М.: ЮНИТИ, 2002. – 399 с.
6. Автоматизированные информационные технологии в экономике: Учебник /Под ред. . – М.: Финансы и статистика, 2001. – 416 с.
