

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лекция 4. Измерение информации. Понятие энтропии
Основоположник теории информации Клод Шеннон определил информацию, как снятую неопределенность. Точнее сказать, получение информации - необходимое условие для снятия неопределенности. Неопределенность возникает в ситуации выбора. Задача, которая решается в ходе снятия неопределенности – уменьшение количества рассматриваемых вариантов (уменьшение разнообразия), и в итоге выбор одного соответствующего ситуации варианта из числа возможных.
Представьте, что вы зашли в магазин и попросили продать вам жевательную резинку. Продавщица, у которой, скажем, 16 сортов жевательной резинки, находится в состоянии неопределенности. Она не может выполнить вашу просьбу без получения дополнительной информации. Если вы уточнили, скажем, - «Orbit», и из 16 первоначальных вариантов продавщица рассматривает теперь только 8, вы уменьшили ее неопределенность в два раза (забегая вперед, скажем, что уменьшение неопределенности вдвое соответствует получению 1 бита информации). Если вы, не мудрствуя лукаво, просто указали пальцем на витрине, - «вот эту!», то неопределенность была снята полностью. Опять же, забегая вперед, скажем, что этим жестом в данном примере вы сообщили продавщице 4 бита информации.
Ситуация максимальной неопределенности предполагает наличие нескольких равновероятных альтернатив (вариантов), т. е. ни один из вариантов не является более предпочтительным. Причем, чем больше равновероятных вариантов наблюдается, тем больше неопределенность, тем сложнее сделать однозначный выбор и тем больше информации требуется для этого получить. Минимальная неопределенность равна 0, т. е. эта ситуация полной определенности, означающая что выбор сделан, и вся необходимая информация получена.
Величина, характеризующая количество неопределенности в теории информации обозначается символом H и имеет название энтропия, точнее информационная энтропия.
Энтропия (H) – мера неопределенности, выраженная в битах.
Максимального значения энтропия достигает в данном случае тогда, когда обе вероятности равны между собой и равны Ѕ, нулевое значение энтропии соответствует случаю, когда вероятность одного из двух событий равна 0, то есть существует полная определенность.
Количество информации I и энтропия H характеризуют одну и ту же ситуацию, но с качественно противоположенных сторон. I – это количество информации, которое требуется для снятия неопределенности H.
Когда неопределенность снята полностью, количество полученной информации I равно изначально существовавшей неопределенности H.
При частичном снятии неопределенности, полученное количество информации и оставшаяся неснятой неопределенность составляют в сумме исходную неопределенность. Ht + It = H.
Поэтому в формулах для расчета энтропии H, когда речь идет о полном снятии неопределенности, можно H поменять на I.
В общем случае, энтропия H и количество получаемой в результате снятия неопределенности информации I зависят от исходного количества рассматриваемых вариантов N и априорных вероятностей реализации каждого из них P: {p0, p1, …pN-1}, т. е. H=F(N, P). Расчет энтропии в этом случае производится по формуле Шеннона, предложенной им в 1948 году в статье "Математическая теория связи":
![]()
![]()
интерпретируется как частное количество информации, получаемое в случае
реализации i-ого варианта.
Пример 1. Пусть в некотором учреждении состав работников распределяется так: ѕ - женщины, ј - мужчины. Тогда неопределенность, например, относительно того, кого вы встретите первым, зайдя в учреждение, будет рассчитана следующим рядом действий.
pi | 1/pi | Ii=log2(1/pi), бит | pi*log2(1/pi), бит | |
Ж | 3/4 | 4/3 | log2(4/3)=0,42 | 3/4 * 0,42=0,31 |
М | 1/4 | 4/1 | log2(4)=2 | 1/4 * 2=0,5 |
| H=0,81 бит |
Если же априори известно, что мужчин и женщин в учреждении поровну (два равновероятных варианта), то при расчете по той же формуле мы должны получить неопределенность в 1 бит.
Пример 2. В первой урне имеются 7 белых, 5 черных и 2 синих шара. Во второй урне - 4 белых, 6 черных и 2 синих шара. Наудачу вынимают один шар. Для какой из урн исход более определенный?
Вычислим энтропию для каждого из случаев: шар – из первой урны, шар – из второй урны. Менее определенному исходу соответствует большее значение энтропии.
Для первой урны возможны три состояния : шар может оказаться или белым, или черным, или синим.
Найдем вероятность каждого состояния: белый шар - р0 =7/14=1/2; черный шар – р1 = 5/14; синий шар- р2 = 2/14 =1/7.
Энтропия для первой урны :
![]()
Аналогичные расчеты выполним для второй урны. Вероятности состояний: белый шар - р0 =4/12= 1/3; черный шар – р1 = 6/12 =1/2; синий шар - р2 = 2/12 =1/6.
Энтропия для второй урны :
![]()
Так как энтропия для второй урны меньше, значит исход для нее более определенный (получено меньшее количество информации).
В частном случае, когда все варианты равновероятны, остается зависимость только от количества рассматриваемых вариантов, т. е. H=F(N). В этом случае формула Шеннона значительно упрощается и совпадает с формулой Хартли, которая впервые была предложена американским инженером Ральфом Хартли в 1928 году, т. е. не 20 лет раньше
Подставив в формулу (1) вместо pi его (в равновероятном случае не зависящее от i) значение ![]() , получим:
, получим:
![]()
таким образом, формула Хартли выглядит очень просто:
![]()
Из нее явно следует, что чем больше количество альтернатив (N), тем больше неопределенность (H).
До сих пор мы приводили формулы для расчета энтропии (неопределенности) H, указывая, что H в них можно заменять на I, потому что количество информации, получаемое при полном снятии неопределенности некоторой ситуации, количественно равно начальной энтропии этой ситуации.
Но неопределенность может быть снята только частично, поэтому количество информации I, получаемой из некоторого сообщения, вычисляется как уменьшение энтропии, произошедшее в результате получения данного сообщения.
![]()
Для равновероятного случая, используя для расчета энтропии формулу Хартли, получим:
![]()
Второе равенство выводится на основании свойств логарифма. Таким образом, в равновероятном случае I зависит от того, во сколько раз изменилось количество рассматриваемых вариантов выбора (рассматриваемое разнообразие).
Пример 3. Пусть некто вынимает одну карту из колоды. Нас интересует, какую именно из 36 карт он вынул. Изначальная неопределенность составляет H=log2(36)=5,17 бит. Вытянувший карту сообщает нам часть информации. Определим, какое количество информации мы получаем из этих сообщений:
Вариант A. “Это карта красной масти”.
I=log2(36/18)=log2(2)=1 бит (красных карт в колоде половина, неопределенность уменьшилась в 2 раза).
Вариант B. “Это карта пиковой масти”.
I=log2(36/9)=log2(4)=2 бита (пиковые карты составляют четверть колоды, неопределенность уменьшилась в 4 раза).
“Это одна из старших карт: валет, дама, король или туз”.
I=log2(36)–log2(16)=5,17-4=1,17 бита (неопределенность уменьшилась больше чем в два раза, поэтому полученное количество информации больше одного бита).
Вариант D. “Это одна карта из колоды".
I=log2(36/36)=log2(1)=0 бит (неопределенность не уменьшилась - сообщение не информативно).
Вариант E. “Это дама пик".
I=log2(36/1)=log2(36)=5,17 бит (неопределенность полностью снята).
Условная энтропия
Для двух независимых опытов будем иметь формулу:
![]()
Найдем энтропию сложного опыта 
![]()
![]() в том случае, если опыты не являются независимыми, т. е. если на исход
в том случае, если опыты не являются независимыми, т. е. если на исход ![]() оказывает влияние результат опыта
оказывает влияние результат опыта  .
.
Например, если в ящике всего два разноцветных шара и  состоит в извлечении первого, а
состоит в извлечении первого, а ![]() – второго из них, то
– второго из них, то  полностью снимает неопределенность сложного опыта
полностью снимает неопределенность сложного опыта 
![]()
![]() , т. е. оказывается H(
, т. е. оказывается H(
![]()
![]() ) = H(
) = H( ), а не сумме энтропии.
), а не сумме энтропии.
В этом случае для вычисления энтропии используется формула:
![]() , где где
, где где ![]() есть средняя условная энтропия опыта
есть средняя условная энтропия опыта ![]() при условии выполнении опыта
при условии выполнении опыта  :
:
![]()
Пример 4. В ящике имеются 2 белых шара и 4 черных. Из ящика извлекают последовательно два шара без возврата. Найти энтропию, связанную с первым и вторым извлечениями, а также энтропию обоих извлечений.
Будем считать опытом  извлечение первого шара. Он имеет два исхода: A1 – вынут белый шар; его вероятность p(A1) = 2/6 = 1/3; исход A2 – вынут черный шар; его вероятность p(A2)=1 – p(A1) = 2/3. Эти данные позволяют сразу найти H(
извлечение первого шара. Он имеет два исхода: A1 – вынут белый шар; его вероятность p(A1) = 2/6 = 1/3; исход A2 – вынут черный шар; его вероятность p(A2)=1 – p(A1) = 2/3. Эти данные позволяют сразу найти H( ):
):
H( )= – p(A1)log2 p(A1) – p(A2)log2 p(A2) = –1/3 log21/3 – 2/3 log22/3 = 0,918 бит
)= – p(A1)log2 p(A1) – p(A2)log2 p(A2) = –1/3 log21/3 – 2/3 log22/3 = 0,918 бит
Опыт ![]() – извлечение второго шара также имеет два исхода: B1 – вынут белый шар; B2 – вынут черный шар, однако их вероятности будут зависеть от того, каким был исход опыта
– извлечение второго шара также имеет два исхода: B1 – вынут белый шар; B2 – вынут черный шар, однако их вероятности будут зависеть от того, каким был исход опыта  . В частности:
. В частности:
![]()
Следовательно, энтропия, связанная со вторым опытом, является условной и она равна:
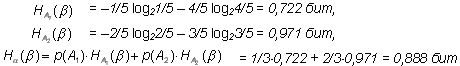
Окончательно получаем H(
![]()
![]() ) = 0,918 + 0,888 = 1,806 бит.
) = 0,918 + 0,888 = 1,806 бит.
Рассмотрим измерение информации с точки зрения алфавитного подхода.
Начнем с самого грубого приближения, то есть предположим, что появление всех знаков (букв) алфавита в сообщении равновероятно. Тогда для английского алфавита ne=27 (с учетом пробела как самостоятельного знака); для русского алфавита nr=34. Из формулы Хартли находим:
I0(e)=log227 = 4,755 бит.
I0(r)=log234 = 5,087 бит
В качестве следующего приближения, уточняющего исходное, попробуем учесть то обстоятельство, что относительная частота, т. е. вероятность появления различных букв в тексте (или сообщении) различна.
Таблица 1. Частота появления букв
Буква | Частота | Буква | Частота | Буква | Частота | Буква | Частота |
пробел | 0,175 | o | 0,090 | е, л | 0,072 | а | 0,062 |
и | 0,062 | т | 0,053 | н | 0,053 | с | 0,045 |
р | 0,040 | в | 0,038 | л | 0,035 | к | 0,028 |
м | 0,026 | д | 0,025 | п | 0,023 | у | 0,021 |
я | 0,018 | ы | 0,016 | з | 0,016 | ъ, ь | 0,014 |
б | 0,014 | г | 0,013 | ч | 0,012 | й | 0,010 |
х | 0,009 | ж | 0,007 | ю | 0,006 | ш | 0,006 |
Для оценки информации, связанной с выбором одного знака алфавита с учетом неравной вероятности их появления в сообщении (текстах) можно воспользоваться формулой
![]()
где pi – вероятность (относительная частота) знака номер i данного алфавита из N знаков. Это и есть знаменитая формула К. Шеннона, с работы которого "Математическая теория связи" (1948) принято начинать отсчет возраста информатики, как самостоятельной науки.
Применение формулы (1.17) к алфавиту русского языка дает значение средней информации на знак I1(r) = 4,36 бит, а для английского языка I1(e) = 4,04 бит, для французского I1(l) = 3,96 бит, для немецкого I1(d) = 4,10 бит, для испанского I1(s) = 3,98 бит. В рассматриваемом приближении по умолчанию предполагается, что вероятность появления любого знака в любом месте сообщения остается одинаковой и не зависит от того, какие знаки или их сочетания предшествуют данному. Такие сообщения называются шенноновскими (или сообщениями без памяти).
Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называются шенноновскими, а порождающий их отправитель – шенноновским источником.
Последующие (второе и далее) приближения при оценке значения информации, приходящейся на знак алфавита, строятся путем учета корреляций, т. е. связей между буквами в словах. Дело в том, что в словах буквы появляются не в любых сочетаниях; это понижает неопределенность угадывания следующей буквы после нескольких, например, в русском языке нет слов, в которых встречается сочетание щц или фъ. И напротив, после некоторых сочетаний можно с большей определенностью, чем чистый случай, судить о появлении следующей буквы, например, после распространенного сочетания пр - всегда следует гласная буква, а их в русском языке 10 и, следовательно, вероятность угадывания следующей буквы 1/10, а не 1/33. В связи с этим примем следующее определение:
Сообщения (а также источники, их порождающие), в которых существуют статистические связи (корреляции) между знаками или их сочетаниями, называются сообщениями (источниками) с памятью или марковскими сообщениями (источниками).
Как указывается в книге Л. Бриллюэна [с.46], учет в английских словах двухбуквенных сочетаний понижает среднюю информацию на знак до значения I2(e)=3,32 бит, учет трехбуквенных – до I3(e)=3,10 бит. Шеннон сумел приблизительно оценить I5(e)  2,1 бит, I8(e)
2,1 бит, I8(e)  1,9 бит. Аналогичные исследования для русского языка дают: I2(r) = 3,52 бит; I3(r)= 3,01 бит.
1,9 бит. Аналогичные исследования для русского языка дают: I2(r) = 3,52 бит; I3(r)= 3,01 бит.
Пример 5. Информационное сообщение объемом 9 Кбайт содержит 12288 символов. Сколько символов содержит алфавит, при помощи которого записано это сообщение (считать, что появление всех символов равноверятно)?
Решение:
Определить информационный вес одного символа.Воспользуемся формулой: i=I/k, где i – информационный вес одного символа, I – объем информационного сообщения, k – количество символов в сообщении.
I=9 Кбайт переведем в биты. Получаем ![]()
Ответ: алфавит содержит 64 символа.
