
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Procedure Udal (Var Left: Adres1; Var Elem: <Тип_элементов_очереди>);
Var
Q: Adres1;
Begin
Elem := Left^.Element; {1-й этап алгоритма выбора}
{10} Q := Left; {2-й этап алгоритма выбора}
{11} Left := Left^.Adrcled; {3-й этап алгоритма выбора}
Dispose(Q) {4-й этап алгоритма выбора}
End;
В. Организация очереди
Пусть в программе имеется описание типа, приведенное в примере 7.7.
Организация очереди основана на использовании операции занесения элемента в очередь
Пример 7.18.
Организация очереди. Ввод исходного текста в очередь. Признак окончания текста – точка. Используется процедура Dobavl занесения элемента в очередь (см. пример 7.16).

Рисунок 7.16 содержит схематические пояснения к примерам 7.16 – 7.18. Номерами на данном рисунке обозначены действия над очередью FIFO, соответствующие номерам операторов в данных примерах.
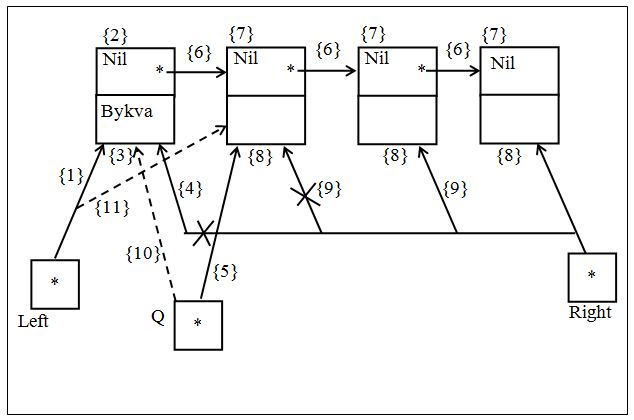
Рисунок 7.16 – Схематические пояснения к примерам 7.16 – 7.18
7.4. Таблицы
7.4.1. Общие сведения
В настоящее время широко используются автоматизиованные информационные системы (АИС). Их назначение: хранение большого числа сведений, прием новых сведений и выдача хранимых сведений по запросам. Обычно сведения предоставляются записями.
Основная задача при создании АИС – организация выдачи по запросу любой из записей, независимо от того, какая запись выдавалась перед ней.
Для организации АИС используются структуры данных, называемые таблицами. В таблице каждой записи соответствует свое имя. Таким образом, таблица – это набор именованных записей. Имя записи называется ключом записи.
Для организации эффективного поиска записи необходимо, чтобы над ключами можно было реализовать операции сравнения (=, <, >), поэтому желательно, чтобы ключи были упорядоченными.
В качестве ключей наиболее удобно использовать целые положительные числа или строки символов одинаковой длины.
Над таблицей определены следующие операции:
- поиск в таблице записи с заданным ключом; включение в таблицу записи с заданным ключом (если в таблице уже есть запись с таким ключом, то старая запись заменяется на новую); исключение из таблицы записи с заданным ключом.
7.4.2. Способы организации таблиц
Возможны следующие способы организации таблиц.
Однонаправленный списокТаблица представляется с помощью однонаправленного списка. Каждое звено списка должно содержать ключ записи, текст записи, ссылку на следующее звено.
Достоинства способа:
а) эффективное использование памяти машины (дополнительная информация в звене – только ссылка на следующее звено);
б) простой алгоритм перебора записей для поиска нужной записи;
в) простота включения в таблицу заведомо новой записи – как новое звено в конец списка.
Недостаток способа – большое время поиска нужной записи за счет следующих факторов:
а) при наличии в таблице N записей для поиска нужной необходимо просмотреть в среднем N/2 элементов списка;
б) если в таблице нет записи с нужным ключом, то нужно просмотреть все N записей.
Однонаправленный список с упорядоченными записямиЗаписи в списке следуют по возрастанию их ключей.
Достоинства способа: меньшее время поиска записи по сравнению со способом 1). Поиск записи требует в среднем просмотра N/2 записей, независимо от того, есть эта запись в таблице или нет.
Недостаток: усложняется процедура включения новой записи в таблицу.
Однонаправленный список с отдельным хранением текста записиИспользуется для ускорения поиска записи. Тексты записей хранятся отдельно от ключей. При ключе хранится только ссылка на текст записи.
Схематическое представление таблицы в виде списка с отдельным хранением текста записи имеет вид, который представляет рисунок 7.17.
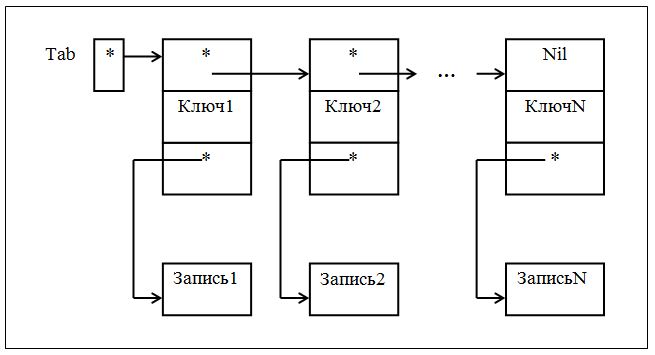
Рисунок 7.17 – Схематическое представление таблицы
в виде списка с отдельным хранением текста записи
Представление в виде массива
Каждый элемент таблицы является записью, содержащей два поля – ключ записи и ссылку на текст записи. Такие элементы обьединяются не в список, а в одномерный массив.
Пример 7.19.
Объявление типа таблицы при использовании массива записей, содержащих два поля – ключ записи и ссылку на текст записи.
Type
Index = 1..N;
Text = <Тип_текста_записи>;
Adr = ^Text;
Element = Record
Kl: Integer; {Ключ}
Adrzap: Adr
End;
Mas = Array [Index] Of Element;
Var
Tabl: Mas;
Схематическое представление таблицы в виде массива иллюстрирует рисунок 7.18.
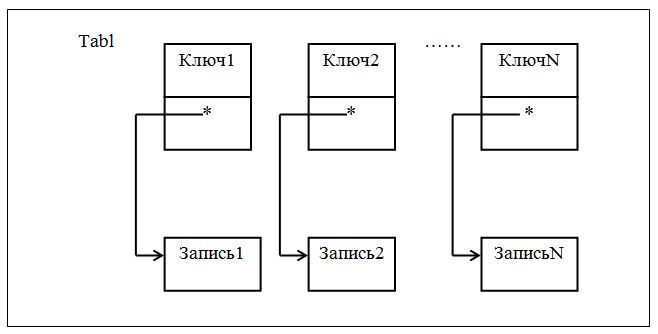
Рисунок 7.18 – Схематическое представление таблицы в виде массива
Для организации эффективного поиска в таблице, реализованной описываемым способом, необходимо, чтобы элементы массива были упорядочены по возрастанию ключей.
Задача поиска записи с заданным ключом сводится к задаче нахождения элемента массива Tabl, в котором содержится этот ключ. Если определен индекс I этого элемента, то искомая запись является значением переменной Tabl[I].Adrzap^.
Для поиска элемента с заданным ключом используется метод половинного деления (дихотомический поиск). Его сущность заключается в следующем.
Берется средний элемент массива с индексом (номером) N/2. Если искомый ключ К меньше чем ключ в элементе с номером N/2, то требуемый элемент находится в первой половине массива, в противном случае – во второй. На следующем этапе нужная половина массива опять делится пополам и определяется, в какой из половин находится соответствующий элемент и так далее. Процесс завершается, если на очередном шаге серединный компонент текущей зоны поиска содержит заданный ключ (требуемая запись найдена) или если зона поиска оказалась пустой (записи с нужным ключом в таблице нет).
Так как на каждом шаге зона поиска уменьшается в два раза, то для завершения поиска требуется не более
![]()
шагов. Таким образом, эффект способа по сравнению со способами 1 и 2 быстро возрастает с ростом N.
Пример 7.20.
Логическая функция Poisk поиска нужного ключа в таблице, реализующая метод дихотомического поиска. Функция Poisk возвращает значение True, если нужный ключ в таблице есть, и False в противном случае. Функция Poisk имеет два параметра: К – искомый ключ, Nomer – номер элемента массива Tabl, в котором хранится нужный ключ К (в параметр-переменную Nomer функция устанавливает значение индекса (номера элемента) массива Tabl, содержащего нужный ключ).
Пусть имеется объявление по примеру 7.19.
Function Poisk (K: Integer; Var Nomer: Index): Boolean;
Var
Lev, Prav: Integer; {Левая и правая границы зоны поиска}
B: Boolean;
I: I ndex;
Begin
Lev := 1;
Prav := N; {N – размер таблицы Tabl}
B := False;
Nomer := 0; {Если в Nomer остается значение ноль, значит, искомого ключа в Tabl нет}
Repeat
I := (Lev + Prav) Div 2;
If K = Tabl[I].Kl Then
Begin
B := True;
Nomer := I
End
Else
If K < Tabl[I].Kl Then
Prav := I - 1
Else
Lev := I+1
Until B Or (Lev > Prav); {Искомый ключ найден или пустая зона (нет нужного ключа)}

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
