

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задание KNN1: Решение задачи классификации методом kNN
Найдите реальные данные для задачи классификации. Зафиксируйте свой выбор в приведённом ниже объекте "Wiki". Перечислите факторы (и укажите единицы их измерения) и поясните смысл переменной отклика. Если число факторов m <= 2, то визуализуйте данные (постройте облако точек). Реализуйте метод kNN для найденных данных. Оцените точность полученного решения с помощью метода кросс-валидации. (Скриншот кросс-валидационнной таблицы включите в отчёт. Поясните, как Вы обеспечили репрезентативность обучающей выборки.) Задайте нескольких новых данных. Если m <= 2, то покажите соответствующие точки на графике (выделите их другим цветом). Определите значение переменной отклика (номер класса) для новых данных.Выполнил: Абдукахаров Бахадыр, студент группы 09-511
Ход работы:
- Веб-сайт с исходными данными и описанием
Ссылка для скачивания файла (чтобы скачать перейдите по ссылке и нажмите Download в правом верхнем углу)
Описание набора данных
Voice Gender
Гендерное распознавание с помощью голосового анализа
Эта база данных была создана для распознания мужского или женского голоса на основе акустических свойств голоса и речи. Набор данных состоит из 3 168 записанных мужских и женских голосовых образцов спикеров. Образцы голоса были предварительно обработаны с помощью акустического анализа в R с помощью библиотек seewave и tuneR. Исследуемый диапазон частот 0 Гц-280 Гц. Подробное описание всех факторов (20 факторов) смотрите на сайте с исходниками.
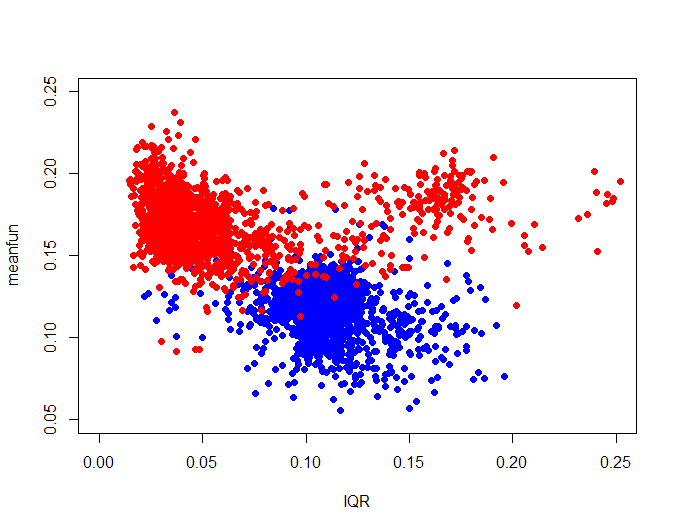
Мы же выберем два фактора путём попарного перебора так, чтобы на графике можно было увидеть два примерно разных облака точек. Факторы:
- IQR: интерквартильный размах — интервал значений частот, содержащий значения между 25-м и 75-м процентилями (в кГц) meanfun: средняя величина базовой частоты. измеряемая по акустическому сигналу (в кГц)
Переменная отклика - один из предполагаемых классов: “male “ – мужчина или “female” – женщина. Классы представлены в соотношении 50:50
- Облако точек
“male” – синие точки
“female” – красные точки
- Равное количество представителей классов удобно для разбиения выборки для обучения и тестирования. Сначала данные были перемешаны. Далее для обучения выделили 75% выборки, остальные 25% - для тестирования. Получили такую кросс-валидационнную таблицу:
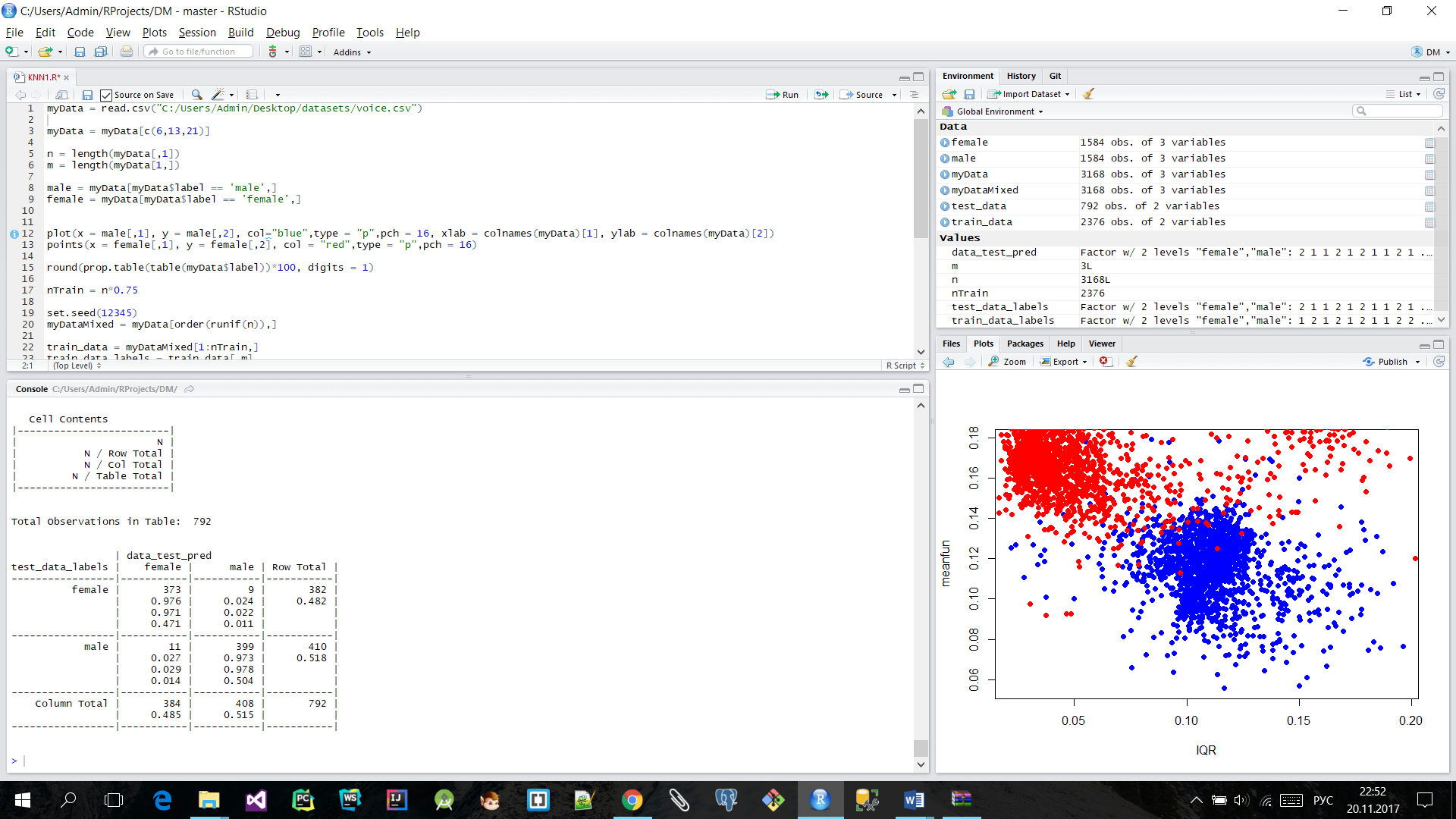
25% нашей выборки составили 792 спикера. Полученное решение из 792 ошиблось 20 раз, это составляет 2.5%, а точность составила 97.5%.
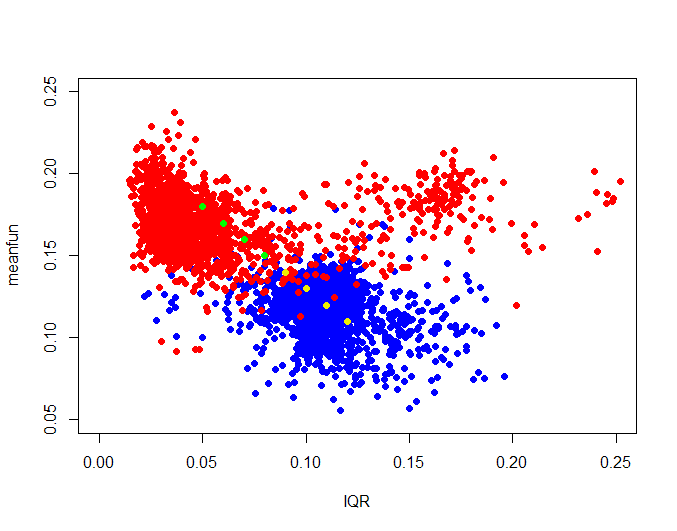
- Задав новые данные, определим переменную отклика и отобразим их на графике. Для новых данных “male” – желтый цвет, “female” – зеленый цвет.
Код программы:
myData = read. csv("C:/Users/Admin/Desktop/datasets/voice. csv")
myData = myData[c(6,13,21)]
n = length(myData[,1])
m = length(myData[1,])
plot(x = myData[myData$label == 'male',1],
y = myData[myData$label == 'male',2],
col = "blue",
type = "p",
pch = 16,
xlab = colnames(myData)[1],
ylab = colnames(myData)[2],
xlim = c(0, 0.25),
ylim = c(0.05, 0.25))
points(x = myData[myData$label == 'female',1],
y = myData[myData$label == 'female',2],
col = "red",
type = "p",
pch = 16)
round(prop. table(table(myData$label))*100, digits = 1)
nTrain = n*0.75
set. seed(12345)
myDataMixed = myData[order(runif(n)),]
train_data = myDataMixed[1:nTrain,]
train_data_labels = train_data[,m]
round(prop. table(table(train_data[m]))*100, digits = 1)
test_data = myDataMixed[(nTrain + 1):n, ]
test_data_labels = test_data[,m]
train_data = train_data[-m]
test_data = test_data[-m]
library("class")
data_test_pred <- knn(train = train_data,
test = test_data,
cl = train_data_labels,
k = round(sqrt(nTrain)))
library(gmodels)
CrossTable(x = test_data_labels, y = data_test_pred, prop. chisq = FALSE)
check = data. frame(0.05,0.18, stringsAsFactors = FALSE)
colnames(check) = c(colnames(test_data))
for(i in 2:8)
{
check[i,] = c(check[(i-1),] + c(0.01, -0.01))
}
points(x = check[,1],
y = check[,2],
col = "white",
type = "p",
pch = 16)
my_check_pred = knn(train = train_data,
test = check,
cl = train_data_labels,
k = round(sqrt(nTrain)))
check[,3] = my_check_pred
points(x = check[check$V3 == "male",1],
y = check[check$V3 == "male",2],
col = "yellow2",
type = "p",
pch = 16)
points(x = check[check$V3 == "female",1],
y = check[check$V3 == "female",2],
col = "green",
type = "p",
pch = 16)
