

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Занятие 2. Лабораторная работа №2
Оценки характеристик генеральной совокупности. Случайные ошибки.
Выборочный метод – основной метод, используемый в математической статистике – основан на том, что суждение о свойствах изучаемой генеральной совокупности (иначе говоря, о свойствах распределения изучаемой случайной величины) выносят по некоторой ее части – выборке. Чтобы по выборочным данным можно было судить о свойствах генеральной совокупности, выборка должна быть отобрана случайно. Используется два способа образования выборки:
- повторный отбор, когда каждый элемент, случайно отобранный и обследованный, возвращается в генеральную совокупность и, теоретически, может быть повторно отобран. Например, если в течение некоторого времени на предприятии каждый день опрашивают сотрудника, пришедшего первым.
- бесповторный отбор, когда отобранный элемент не возвращается в общую совокупность. При этом если объем генеральной совокупности велик, любой случайный выбор считают бесповторным.
Оценка параметра ![]() генеральной совокупности одним числом
генеральной совокупности одним числом ![]() называется точечной оценкой. Приведем точечные оценки основных параметров распределения признака в генеральной совокупности:
называется точечной оценкой. Приведем точечные оценки основных параметров распределения признака в генеральной совокупности:
Таблица 2.1. Точечные оценки основных характеристик генеральной совокупности
Параметр (генеральная характеристика) | Оценка (выборочная характеристика) | Функция в Excel |
Генеральная средняя математическое ожидание М(Х) – для бесконечной генер. совок. | Выборочная средняя
| СРЗНАЧ(…) |
Дисперсия дисперсия | Исправленная выборочная дисперсия
| ДИСП(…) |
Доля р элементов в генеральной совокупности, обладающих указанным свойством; Вероятность р появления указанного свойства | Доля в выборке
| СЧЁТЕСЛИ(…)/СЧЁТ(…) |
Мода |
| МОДА(…) |
Медиана |
| МЕДИАНА(…) |
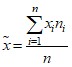
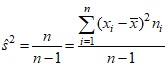
Между признаками выборочной совокупности и соответствующими признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называется ошибкой статистического наблюдения:
- Ошибки регистрации, или технические ошибки, связаны с недостаточной квалификацией наблюдателей, неточностью подсчетов, несовершенством приборов и т. п. Под ошибкой репрезентативности понимают расхождение между выборочной характеристикой и разыскиваемой (истинной) характеристикой генеральной совокупности. Здесь возможны систематические ошибки, связанные с нарушением установленных правил отбора, и случайные ошибки, которые объясняются недостаточно равномерным представлением в выборочной совокупности различных категорий единиц генеральной совокупности.
В результате систематической ошибки выборка может оказаться смещенной, т. к. при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону (например, возраст при анкетировании часто оказывается округлен в меньшую сторону, а стаж работы – в большую). Эта ошибка получила название ошибки смещения. Ее размер может превышать величину случайной ошибки, определить его, как правило, сложно или невозможно. Особенность ошибки смещения состоит в том, что, являясь постоянной частью ошибки репрезентативности, она увеличивается с увеличением объема выборки.
Случайная ошибка с увеличением объема выборки уменьшается. Величину случайной ошибки можно определить.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной , величину стандартной ошибки простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле
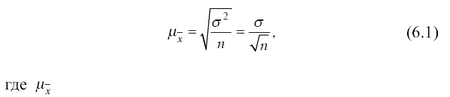
– стандартная ошибка.
Из этой формулы средней (стандартной) ошибки простой случайной выборки видно, что величина зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n (чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
Академик A. M. Ляпунов доказал, что вероятность появления случайной ошибки выборки при достаточно большом ее объеме подчиняется закону нормального распределения. Эта вероятность определяется по формуле
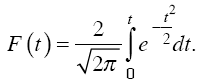
Выборочное наблюдение дает возможность определить среднюю арифметическую выборочной совокупности и величину предельной ошибки этой средней, которая показывает (с определенной вероятностью), насколько выборочная величина может отличаться от генеральной средней в большую или меньшую сторону. Тогда величина генеральной средней будет представлена интервальной оценкой.
Интервал, в который с данной степенью вероятности будет заключена неизвестная величина оцениваемого параметра, называют доверительным, а вероятность Р – доверительной вероятностью. Чаще всего доверительную вероятность принимают равной 0,95 или 0,99. Это означает, что доверительный интервал с заданной вероятностью заключает в себе генеральную среднюю.
Чем больше величина предельной ошибки выборки, тем больше величина доверительного интервала и тем, следовательно, ниже точность оценки. Средняя (стандартная) ошибка выборки зависит от объема выборки и степени вариации признака в генеральной совокупности.
Для генеральной средней ![]() и генеральной доли р(например доля ошибок в совокупности счетов, пример для аудиторов) предельную ошибку выборки (или точность) для генерального среднего и генеральной доли можно представить в виде
и генеральной доли р(например доля ошибок в совокупности счетов, пример для аудиторов) предельную ошибку выборки (или точность) для генерального среднего и генеральной доли можно представить в виде
![]()
где μ - стандартная или средняя ошибка выборки, t – коэффициент доверия, связанный с доверительной вероятностью – вероятностью того, что случайная ошибка репрезентативности на самом деле не превосходит вычисленную предельную ошибку.
В случае большой выборки (n>100) определение предельной ошибки для среднего и доли основано на центральной предельной теореме, вследствие которой среднее и доля при большом числе измерений имеют распределения близкие к нормальному. Поэтому коэффициент доверия t вычисляется по таблицам функции Лапласа 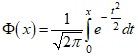 из условия
из условия ![]() . При работе с таблицами Excel для вычисления коэффициента доверия по заданной доверительной вероятности используют функцию НОРМСТОБР, а для определения доверительной вероятности по коэффициенту доверия – функцию НОРМРАСП. Однако следует иметь в виду, что функция НОРМСТОБР(х) возвращает вероятность принятия нормально распределенной случайной величиной значения меньше х, т. е. величину
. При работе с таблицами Excel для вычисления коэффициента доверия по заданной доверительной вероятности используют функцию НОРМСТОБР, а для определения доверительной вероятности по коэффициенту доверия – функцию НОРМРАСП. Однако следует иметь в виду, что функция НОРМСТОБР(х) возвращает вероятность принятия нормально распределенной случайной величиной значения меньше х, т. е. величину 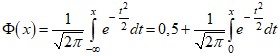 . Таким образом, Р(t)=(НОРМСТРАСП(t)-0,5)*2; обратно, t=НОРМСТОБР(0,5*P(t)+0,5)
. Таким образом, Р(t)=(НОРМСТРАСП(t)-0,5)*2; обратно, t=НОРМСТОБР(0,5*P(t)+0,5)
Стандартная ошибка большой выборки для генеральной средней и генеральной доли рассчитывается в зависимости от условий отбора в соответствии с таблицей:
Таблица 2.2. Расчет стандартных ошибок большой выборки
Повторный отбор (или n<<N, или N=∞) | Бесповторный отбор | |
Для генеральной средней |
|
|
Для генеральной доли |
|
|
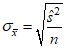
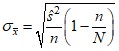
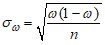
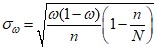
Следует отметить, что предельную ошибку для среднего большой выборки можно рассчитать в Excel также при помощи функции
ДОВЕРИТ(альфа; станд. откл; размер)
Здесь альфа – допустимая вероятность ошибки, т. н. уровень значимости: α=1-γ;
станд. откл. – генеральное среднее квадратическое отклонение, предполагающееся известным, или его оценка ![]() ; размер – текущий объем выборки n.
; размер – текущий объем выборки n.
При помощи формулы предельной ошибки выборки решают следующие задачи:
- Определение доверительного интервала с заданной доверительной вероятностью γ для генерального среднего
Таблица 2.3. Расчет необходимого объема выборки
Повторный отбор (или n<<N, или N=∞) | Бесповторный отбор | |
Для генеральной средней |
|
|
Для генеральной доли |
|
|
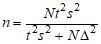
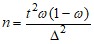
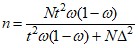
В случае малой выборки (n<30) при отсутствии данных о нормальности распределения признака предельная ошибка для генеральной средней определяется по формуле:
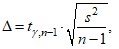
![]() - табличное значение критерия Стьюдента для вероятности γ при числе степеней свободы n-1. В Excel коэффициент доверия для малой выборки рассчитывается при помощи функции СТЬЮДРАСПОБР(вероятность;степени свободы), где за аргумент вероятность принимается уровень значимости α=1-γ.
- табличное значение критерия Стьюдента для вероятности γ при числе степеней свободы n-1. В Excel коэффициент доверия для малой выборки рассчитывается при помощи функции СТЬЮДРАСПОБР(вероятность;степени свободы), где за аргумент вероятность принимается уровень значимости α=1-γ.
Для 30<n<100 причисление выборки к категории «большой» или «малой» индивидуально, зависит от постановки задачи и от дисперсии выборки. Четкой границы между большой и малой выборками в общем случае указать невозможно. Выборка, сделанная из совокупности с небольшим разбросом признака, может считаться большой, тогда как выборка такого же объема, произведенная из более разнородной совокупности, окажется малой.
