
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 519.233
© 2013
исследование точности идентификации асимметричной логистической модели гомпертца
Для описания нелинейной социально-экономической динамики предложена логистическая функция Гомпертца с правой асимметрией. В широком диапазоне сочетаний параметров и мощности помехи на тестовых выборках оценена точность идентификации растущей и падающей моделей Гомпертца с левой и правой асимметрией по двум предложенным методикам. Приведен пример получения точечных и интервальных оценок точности параметров модели и прогноза для реальной динамики с помощью тестовых выборок.
Ключевые слова: логистическая кривая Гомпертца с левой и правой асимметрией, точечные и интервальные оценки точности, критерии точности прогноза, моделирование, продолжительность жизни
В эконометрической литературе в качестве примера нелинейных функций регрессии часто приводится логистическая модель Гомпертца. Данной функцией в настоящее время пользуются при моделировании динамики роста опухолей, сотовой телефонии, численности населения, потребительских товаров длительного пользования, инноваций в сельском хозяйстве и др. [1, 2].
Существуют две формы записи функции Гомпертца: (1) принята в отечественной литературе, (2) – в зарубежной:
![]() , (1)
, (1)
![]() , (2)
, (2)
где ![]() - время,
- время, ![]() - обозначение для тренда,
- обозначение для тренда, ![]() - параметры моделей.
- параметры моделей.
Далее будем рассматривать только вторую форму записи. В ней параметр ![]() отвечает за уровень насыщения, параметр
отвечает за уровень насыщения, параметр ![]() - за скорость роста кривой. Точка перегиба для функции Гомпертца определятся выражениями:
- за скорость роста кривой. Точка перегиба для функции Гомпертца определятся выражениями:
![]() ,
, ![]() .
.
Поскольку ордината точки перегиба составляет менее половины уровня насыщения, то данная функция является асимметричной слева (до точки перегиба стадия роста короче, чем после точки перегиба).
Предложим расширение модели Гомпертца (2): преобразуем модель (1) так, чтобы получить кривую с правой асимметрией (точка перегиба правее точки половины уровня насыщения):
![]() , где
, где ![]() ,
, ![]() (3)
(3)
Модель логистического тренда в общем случае запишется в виде ![]() , где k – номера наблюдений (
, где k – номера наблюдений (![]() – номера наблюдений,
– номера наблюдений, ![]() - период дискретизации – месяц, квартал, год),
- период дискретизации – месяц, квартал, год), ![]() - значения ряда,
- значения ряда, ![]() - тренд,
- тренд, ![]() - стохастическая компонента.
- стохастическая компонента.
В литературе чаще всего рассматриваются методы идентификации модели Гомпертца с трендом в записи (1). Эти методы применяют линеаризующие преобразования (логарифмирование) при условии включения в модель мультипликативной стохастической компоненты [3].
Для записи (2) применяют, как правило, алгоритм Гаусса-Ньютона (нелинейный МНК) при включении в модель аддитивной стохастической компоненты.
Методы идентификации модели Гомпертца применялись лишь для конкретных выборок социально-экономической динамики и не были протестированы в широком диапазоне сочетаний параметров и мощности помехи по отношению к исходному ряду. Между тем, в [4] предложена методология оценки точности идентификации моделей с использованием тестовых выборок.
Мощность стохастической компоненты меняется в диапазоне значений коэффициента шум-сигнал ![]() . При этом анализу будет подвергаться выборка наблюдений ряда динамики
. При этом анализу будет подвергаться выборка наблюдений ряда динамики ![]() , где
, где ![]() ,
, ![]() - детерминированная компоненты (исходный незашумленный ряд),
- детерминированная компоненты (исходный незашумленный ряд), ![]() - операторы математического ожидания и среднеквадратического отклонения соответственно.
- операторы математического ожидания и среднеквадратического отклонения соответственно.
В качестве критериев оценки точности моделирования и прогнозирования, как правило, используют коэффициент детерминации ![]() и MAPE-оценку соответственно [5]. MAPE-оценка мало чувствительна к ошибкам прогноза больших значений. В то же время, ее расчет затруднителен, если значения наблюдений ряда близки к нулю. Также этот критерий чувствителен к любому случайному выбросу в выборке, поскольку при расчете осуществляется деление на абсолютное значение ряда.
и MAPE-оценку соответственно [5]. MAPE-оценка мало чувствительна к ошибкам прогноза больших значений. В то же время, ее расчет затруднителен, если значения наблюдений ряда близки к нулю. Также этот критерий чувствителен к любому случайному выбросу в выборке, поскольку при расчете осуществляется деление на абсолютное значение ряда.
Поэтому вместо MAPE-оценки используют второй коэффициент Тейла ![]() . Данный коэффициент более устойчив к случайным выбросам, чем MAPE-оценка, поскольку при расчете используются сглаженные значения – суммы квадратов наблюдений исходного и модельного рядов. Тем не менее, этот критерий также рассчитывается по абсолютным значениям ряда. Следовательно, при наличии растущего логистического тренда в знаменателе получим гораздо большую величину, чем при наличии падающего логистического тренда, в то время как числитель останется примерно одинаковым (поскольку рассчитывается как сумма квадратов отклонений модельного ряда от исходного).
. Данный коэффициент более устойчив к случайным выбросам, чем MAPE-оценка, поскольку при расчете используются сглаженные значения – суммы квадратов наблюдений исходного и модельного рядов. Тем не менее, этот критерий также рассчитывается по абсолютным значениям ряда. Следовательно, при наличии растущего логистического тренда в знаменателе получим гораздо большую величину, чем при наличии падающего логистического тренда, в то время как числитель останется примерно одинаковым (поскольку рассчитывается как сумма квадратов отклонений модельного ряда от исходного).
Данную ситуацию позволяет исправить критерий, предложенный [6]:
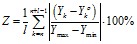 .
.
В отличие от MAPE-оценки и второго коэффициента Тейла, данный критерий использует для расчета не только прогнозную часть выборки: минимальное и максимальное значения берутся по всей выборке. При условии большого диапазона изменения наблюдений исходного ряда, данный критерий позволяет устранить разницу в оценивании прогноза для растущих и падающих трендов.
К расчету критериев по тестовым выборкам можно подходить по-разному.
В первой методике расчета осуществляется сравнение рассчитываемых модельных значений ряда ![]() с зашумленными наблюдениями
с зашумленными наблюдениями ![]() . Тем самым рассчитаем, какими будут показатели точности, если указанный метод будет применяться на реальных выборках с таким же соотношением шум-сигнал.
. Тем самым рассчитаем, какими будут показатели точности, если указанный метод будет применяться на реальных выборках с таким же соотношением шум-сигнал.
Можно сравнивать модельные значения ряда ![]() и с исходными (детерминированными, генерированными) и с уровнями
и с исходными (детерминированными, генерированными) и с уровнями ![]() (вторая методика). Тем самым определяется, насколько точно была найдена предложенная модель по зашумленной выборке.
(вторая методика). Тем самым определяется, насколько точно была найдена предложенная модель по зашумленной выборке.
Проведем исследование точности идентификации модели Гомпертца с аддитивной стохастической компонентой на тестовых выборках:
с левой асимметрией ![]() ,
,
с правой асимметрией ![]() .
.
Заметим, что в модели добавлены параметры C, которые обеспечивают ненулевую горизонтальную асимптоту логистической кривой.
Рассмотрим случай растущего логистического тренда. Тестовые выборки логистического тренда Гомпертца генерировались объемом в 24 наблюдения и прогнозом на 8 наблюдений. Исходные значения параметров приведены в табл. 1.
Таблица 1
Исходные значения параметров для генерации тестовых выборок
Параметр | Минимальное значение | Максимальное значение |
| 10 | 10 |
| 50 | 50 |
| 0,2 | 0,8 |
| 5 | 15 |
Дисперсия генерируемой помехи задавалась с помощью коэффициента шум/сигнал ![]() , который варьировался от 0 до 0,3.
, который варьировался от 0 до 0,3.
Для модели с левой асимметрией рассмотрим три метода идентификации: метод Левенберга-Марквардта, алгоритм RPROP и генетический алгоритм [7, 8, 9].
Для каждого ![]() результаты усреднялись по 1800 выборкам, всего было сгенерировано по 12600 выборок для каждого метода.
результаты усреднялись по 1800 выборкам, всего было сгенерировано по 12600 выборок для каждого метода.
Рассчитывались значения оценок параметров и меры точности по двум методикам, представленным ранее: точность моделирования оценивалась с помощью коэффициента детерминации ![]() , а точность прогнозирования – с помощью второго коэффициента Тейла
, а точность прогнозирования – с помощью второго коэффициента Тейла ![]() . Результаты оценки точности моделирования и прогнозирования для логистической модели Гомпертца с левой асимметрией представлены на рис. 1 и 2.
. Результаты оценки точности моделирования и прогнозирования для логистической модели Гомпертца с левой асимметрией представлены на рис. 1 и 2.
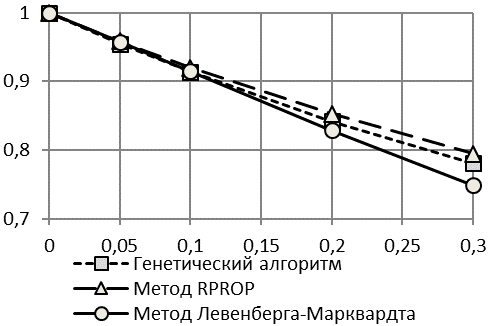
Заметим, что метод Левенберга-Марквардта значительно уступил по точности модели и прогноза двум другим методам, что демонстрируют результаты расчета. Тем не менее, точность прогноза, достигаемая всеми методами идентификации, остается высокой (в пределах 20%) даже при мощности шума в 30% от мощности полезного (модельного) сигнала.
Результаты алгоритма RPROP и генетического алгоритма практически совпадают по точности в обеих методиках, поэтому в дальнейшем не будем применять генетический алгоритм, как требующий больших временных затрат на расчеты.
а) |
б) |
Рис. 1. Зависимость R2 от Kn/s (а) и kT2 от Kn/s (б) при использовании первой методики расчета критериев точности | |
а) |
б) |
Рис. 2. Зависимость R2 от Kn/s (а) и kT2 от Kn/s (б) при использовании второй методики расчета критериев точности |
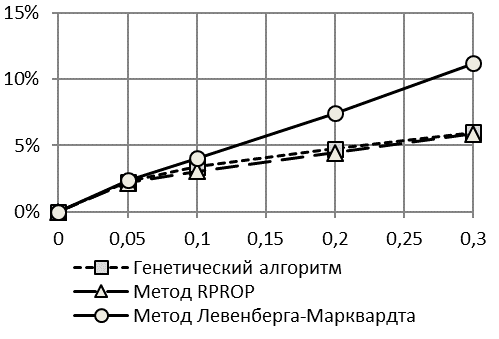
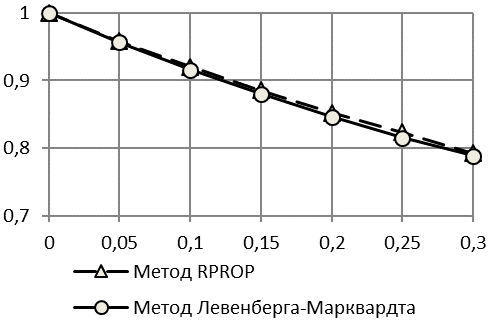
Проведем аналогичное исследование с теми же исходными данными параметров для модели с правой асимметрией двумя методами – Левенберга-Марквардта и RPROP.
Результаты оценки точности моделирования и прогнозирования для логистической модели Гомпертца с правой асимметрией представлены на рис. 3 и 4.
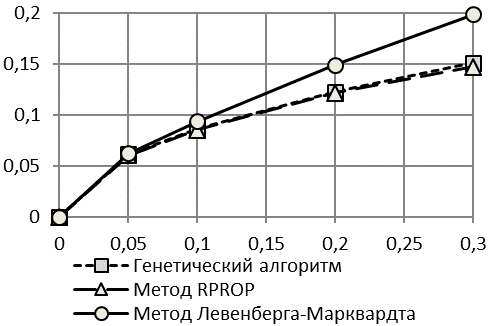
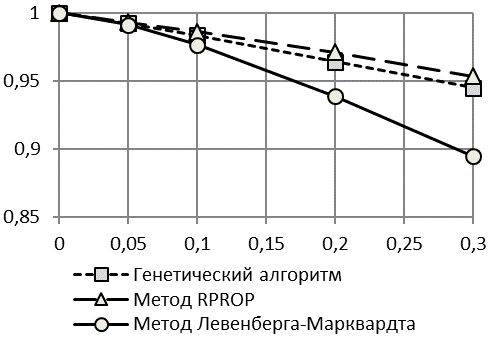
По первой методике оценки точности моделирования и прогнозирования двумя методами практически совпадают. По второй методике видно, что алгоритм RPROP дает несущественно более точные результаты по отысканию изначально заданной модели.
Таким образом, для идентификации асимметричной справа модели Гомпертца с растущим логистическим трендом возможно применение любого из двух методов.
а) |
б) |
Рис. 3. Зависимость R2 от Kn/s (а) и kT2 от Kn/s (б) при использовании первой методики расчета критериев точности | |
а) |
б) |
Рис. 4. Зависимость R2 от Kn/s (а) и kT2 от Kn/s (б) при использовании второй методики расчета критериев точности |
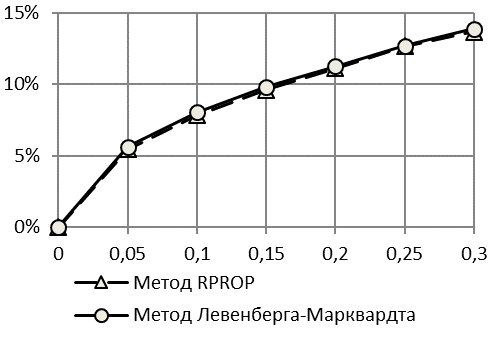
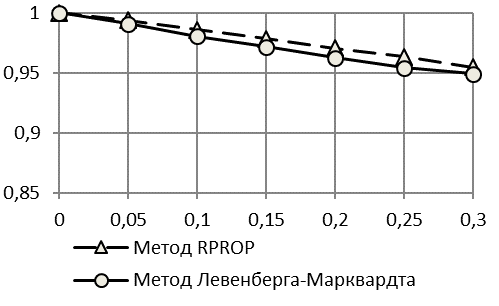
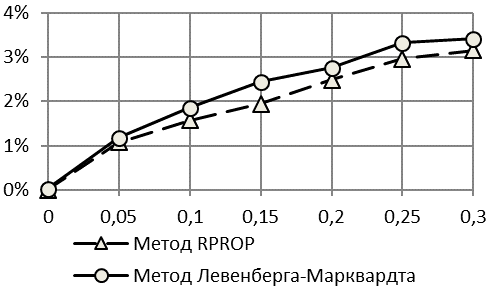
Интерес может представить и оценка точности идентификации падающей логистической кривой при ![]() , когда логистическая кривая будет стремиться не к уровню насыщения, а к уровню спада – нижней горизонтальной асимптоте.
, когда логистическая кривая будет стремиться не к уровню насыщения, а к уровню спада – нижней горизонтальной асимптоте.
Исходные данные повторяют исследование, проведенное для растущих функций Гомпертца, отличие состоит лишь в диапазоне изменение параметра ![]() : параметр изменяется от –0,8 до –0,2 с шагом 0,2.
: параметр изменяется от –0,8 до –0,2 с шагом 0,2.
В качестве критерия оценки точности прогноза, помимо второго коэффициента Тейла, примем и критерий .
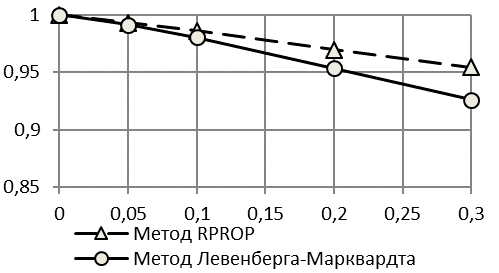
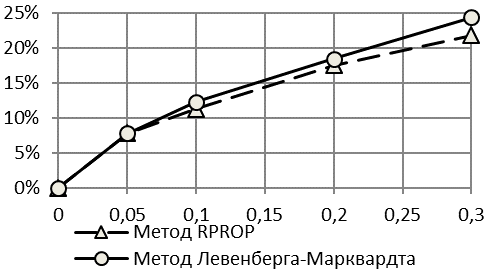
Из приведенных результатов для падающей логистической кривой с правой асимметрией (рис. 5, 6) видно, что точность прогнозирования для рядов с падающим логистическим трендом Гомпертца хуже, чем для рядов с растущим по критерию второго коэффициента Тейла. Недостаток критерия, который был выявлен на рядах со снижающейся тенденцией при наличии широкого диапазона изменения показателя от минимального к максимальному значению, устраняется применение критерия , который менее чувствителен к снижению тенденции ряда динамики.
а) |
б) |
в) | |
Рис. 5. Зависимость R2 (а), kT2 (б) и Z (в) от Kn/s для падающей логистической кривой при использовании первой методики расчета критериев точности | |
а) |
б) |
в) | |
Рис. 6. Зависимость R2 (а), kT2 (б) и Z (в) от Kn/s для падающей логистической кривой при использовании второй методики расчета критериев точности |
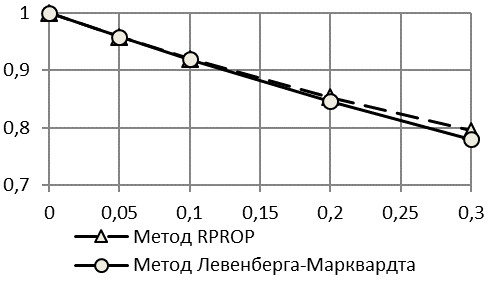
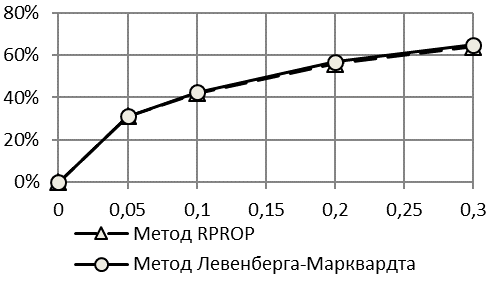
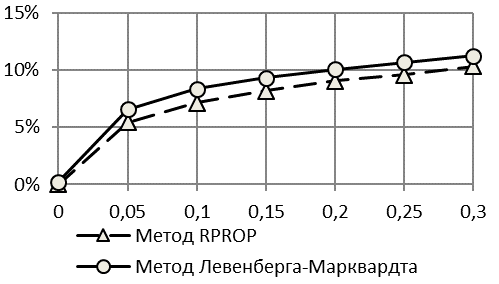
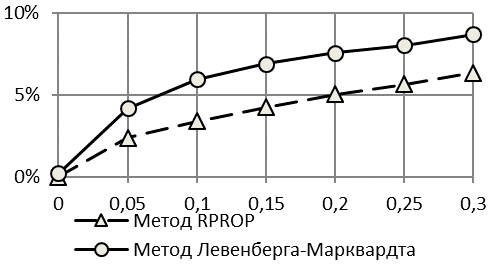
Интересен тот факт, что при использовании первой методики получаемый прогноз по критерию коэффициента Тейла является недостоверным – уже при шуме в 5% значения критерия точности прогнозирования намного превышают рекомендованный обычно уровень в 20%. Прогноз, соотнесенный с истинными (заданными) выборками, для всех методов является достоверным в пределах 20% соотношения шум-сигнал. По критерию качество прогнозирования остается высоким (ошибка менее 11%) даже при шуме в 30% полезного сигнала.
Методология оценки точности идентификации временных рядов позволяет также рассчитать доверительные интервалы для математического ожидания оценок, определить, накрывает ли доверительный интервал известное истинное значение параметра, а также рассчитать доверительный интервал для прогноза.
Для известного ряда статистических данных строится модель, рассчитываются оценки параметров, и вычисляется ряд остатков. Затем вычисляется эмпирический коэффициент шум-сигнал. Для полученных оценок параметров и рассчитанного коэффициента шум-сигнал генерируются тестовые выборки, вычисляются точечные оценки точности оценок параметров модели. Затем можно перейти от точечных оценок точности к интервальным, т. е. рассчитать доверительные интервалы для оценок параметров модели с доверительной вероятностью ![]() :
:
![]() ,
,
где ![]() – квантиль распределения Стьюдента, n – объем выборки,
– квантиль распределения Стьюдента, n – объем выборки, ![]() - математическое ожидание и среднеквадратическое отклонение параметра
- математическое ожидание и среднеквадратическое отклонение параметра ![]() .
.
Расчет доверительного интервала прогноза осуществляется следующим образом [3]:
![]() ,
,
где ![]() – число параметров модели,
– число параметров модели, ![]() – средняя квадратическая ошибка, l – горизонт прогноза.
– средняя квадратическая ошибка, l – горизонт прогноза.
Рассмотрим в качестве примера реальной социальной логистической динамики ожидаемую продолжительность жизни в Нидерландах с 1860 по 2010гг. (данные учитываются каждые 5 лет, всего 31 наблюдение). Данная выборка была разделена на рабочую и прогнозную части. В рабочую часть были включены 23 наблюдения, а в прогнозную – 8 наблюдений.
Применим для данной выборки методику оценки достигаемой методами идентификации точности с использованием генерации стохастической компоненты.
По рабочей части выборки с помощью алгоритма RPROP была построена модель Гомпертца с левой асимметрией:
![]() ,
,
при этом получены следующие критерии точности моделирования и прогнозирования: ![]() (
(![]() рассчитан по прогнозной части выборки).
рассчитан по прогнозной части выборки).
Эмпирический коэффициент шум-сигнал составил 1,45%. Заметим, что в большинстве приводимых в известной литературе примерах и в исследованиях, проведенных автором, мощность стохастической компоненты не превысила 10%.
С параметрами полученной модели Гомпертца и рассчитанным коэффициентом шум-сигнал было сгенерировано 1000 выборок по описанной методике, которые были идентифицированы с помощью алгоритма RPROP. Результаты расчетов представлены в табл. 2. В скобках указана методика, по которой рассчитывались критерии точности.
Можно перейти от точечных оценок точности к интервальным: рассчитаем доверительные интервалы для оценок параметров модели с доверительной вероятностью ![]() (таблица 3).
(таблица 3).
Таблица 2
Результаты оценки параметров модели Гомпертца по тестовым выборкам
Параметр | C | A0 | ? | k0 | R2 (1) | R2 (2) | kT2 (1) | kT2 (2) |
Истинное значение | 36,266 | 44,734 | 0,148 | 11,048 | 0,986 | 0,418% | ||
Мат. ожидание | 35,999 | 45,608 | 0,149 | 11,084 | 0,931 | 0,998 | 2,037% | 1,265% |
СКО | 1,639 | 5,348 | 0,024 | 0,625 | 0,229 | 0,001 | 0,796% | 0,937% |
Таблица 3
Расчет доверительного интервала для математического ожидания оценок параметров модели Гомпертца
Параметр | C | A0 | ? | k0 |
Нижняя граница интервала | 35,290 | 43,296 | 0,139 | 10,814 |
Истинное значение | 36,266 | 44,734 | 0,148 | 11,048 |
Мат. ожидание | 35,999 | 45,608 | 0,149 | 11,084 |
Верхняя граница интервала | 36,708 | 47,920 | 0,159 | 11,354 |
На рис. 7 представлен результат моделирования и расчет доверительного интервала прогноза:
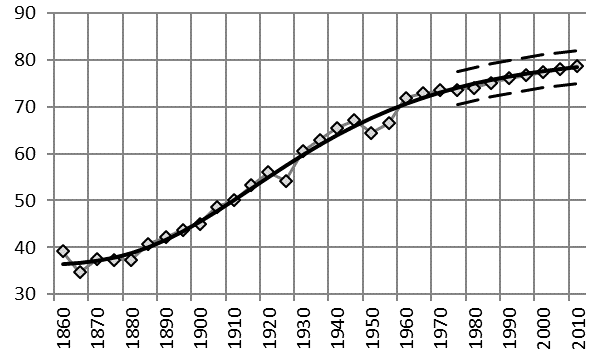
Рис. 7. Моделирование ожидаемой продолжительности жизни в Нидерландах, лет
Видим, что прогнозные значения продолжительности жизни в Нидерландах оказались внутри доверительного интервала, что говорит о высокой точности моделирования и прогнозирования.
Предложенная методика исследования точности идентификации временных рядов может быть расширена и на другие модели логистических и иных видов трендов для тестирования выбранных методов в широком диапазоне сочетаний параметров и мощности помехи, а также получения точечных и интервальных оценок точности.
Литература
Grubler, A. Diffusion of technologies and social behavior [Текст] / A. Grubler, N. Nakicenovic (eds). – Springer Verlag and International Institute for Applied Systems Analysis. – Berlin and New York, 1991. – 605 с. Айвазян, статистика. Основы эконометрики [Текст]. / – М.: ЮНИТИ-ДАНА, 2001. – 432 с. Четыркин, методы прогнозирования. [Текст] – М., Статистика, 1977. – 198 с. Семёнычев, идентификация рядов динамики: структуры, модели, эволюция: монография [Текст]. / , . – Самара: изд-во «СамНЦ РАН», 2011. – 364 с. Эконометрика [Текст] / под ред. . – М.: Финансы и статистика, 2005. – 575 с. Загоруйко, методы анализа данных и знаний [Текст]. / – Новосибирск: ИМ СО РАН, 1999. – 270 с. Осовский, С. Нейронные сети для обработки информации [Текст] / Пер. с польского . – М.: Финансы и статистика, 2002. – 344с. Wikipedia, the free encyclopedia: Genetic algorithm. [Электронный ресурс]. Режим доступа: http://en. wikipedia. org/wiki/Genetic_algorithm. Библиотека алгоритмов ALGLIB. Алгоритм Левенберга-Марквардта. [Электронный ресурс]. Режим доступа: http://alglib. sources. ru.Поступило в редакцию 16.04.2013
