


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Визуализация результата анализа тональности текста
С помощью среды R можно анализировать различные данные, получать результат в различном виде: графики, гистограммы, тепловые карты и т. д. Построение гистограмм и облака точек не является новой задачей, так как она уже рассматривалась в данном курсе.
Отличительной чертой будет являться не сама визуализации, а способ получения данных и способ работы с полученными данными, на основе которых мы будем строить уже известные нам гистограммы и облака точек.
Для начала рассмотрим терминологию.
Тональность — это эмоциональное отношение автора высказывания к некоторому объекту, выраженное в тексте. Анализ тональности текста – класс методов контент-анализа в компьютерной лингвистике, предназначенный для автоматизированного обнаружения в текстах эмоционально окрашенной лексики, а также для эмоциональной оценки отношения авторов к объектам, о которых идет речь в тексте.
Получать текст для анализа мы будем из социальной сети Twitter с помощью библиотек для R и Twitter API. Библиотека для работы с Twitter API в среде R называется twitteR и подключается с помощью команды «library('twitteR')».
Перед написанием скрипта на R необходимо провести подготовительную работу:
1. регистрация на портале разработчиков приложений для Твиттера (https://developer. /), получение секретных ключей для разработки;
api_key = "Ваш ключ API"
api_secret = "Ваш api_secret пароль"
access_token = "Ваш токен доступа"
access_token_secret = "Ваш пароль токена доступа"
Все ключи берутся все на том же портале, после регистрации приложения. Регистрация и получение ключей интуитивно понятны и просты и не требуют дополнительных пояснений.
2. создание или использование существующих словарей позитивных и негативных слов. Словарями являются обычные списки слов. Существующие словари можно легко найти в интернете.

Скрин словаря позитивных слов
После завершения подготовительных работ пишем скрипт на языке R, включающий в себя:
Подключение библиотек (twitteR, dplyr, stringr, ggplot2, tm, SnowballC, qdap); Введение ключей;api_key = "Ваш ключ API"
api_secret = "Ваш api_secret пароль"
access_token = "Ваш токен доступа"
access_token_secret = "Ваш пароль токена доступа"
Все ключи берутся все на том же портале разработчиков, после регистрации приложения. Регистрация и получение ключей интуитивно понятны и просты и не требуют дополнительных пояснений.
Авторизацию для получения доступа к Twitter API;setup_twitter_oauth(api_key, api_secret, access_token, access_token_secret)
Загрузку словарей из текстовых файлов;positive=scan('positive-words. txt',what='character',comment. char=';') negative=scan('negative-words. txt',what='character',comment. char=';')
Выполнение запроса на поиск постов на заданную тему;findfd="hollywood" #тема запроса
number=5000 #количество выгружаемых записей
tweet=searchTwitter(findfd, number)
Получение текста твитов;tweetT=lapply(tweet, function(t)t$getText())
head(tweetT,5) #результат выборки для первых 5 сообщений
# Функции очищения текста
# tolower() – приведение верхнего регистра к нижнему, выдает ошибку, встречая специальные символы
tryTolower = function(x){y = NA; try_error = tryCatch(tolower(x), error = function(e) e); if (!inherits(try_error, "error")) y = tolower(x); return(y)}
# clean – очищает твиты и разбивает на векторы слов
clean=function(t){ t=gsub('[[:punct:]]','',t); t=gsub('[[:cntrl:]]','',t); t=gsub('\\d+','',t); t=gsub('[[:digit:]]','',t); t=gsub('@\\w+','',t); t=gsub('http\\w+','',t); t=gsub("^\\s+|\\s+$","",t) t=gsub('“','',t); t=gsub('”','',t); t=gsub('*','',t); t=sapply(t, function(x) tryTolower(x)); t=str_split(t," "); t=unlist(t); return(t)}
# Очищение твитов и разбиение на слова
tweetclean=lapply(tweetT, function(x) clean(x))
head(tweetclean,5) #результат для первых 5 сообщений
Анализ твитов (поиск позитивных и негативных слов);
Скрипт построения гистограмм и облаков слов приводить не имеет смыла, так как он рассмотрен в основном курсе Анализа данных в среде R. Рассмотрим лишь результаты построения, не анализируя полученный результат.
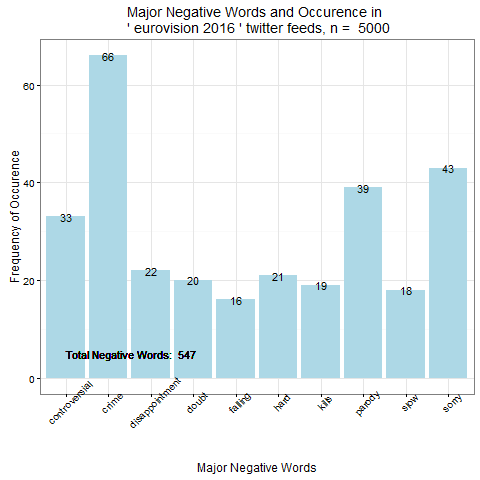
1. Евровидение 2016
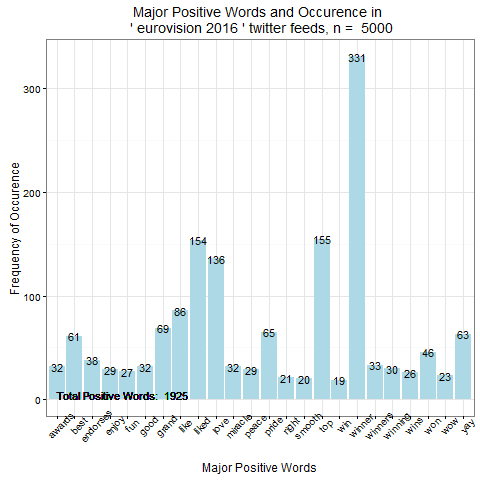
Облако позитивных слов по теме "eurovision 2016" |
Облако негативных слов по теме "eurovision 2016" |


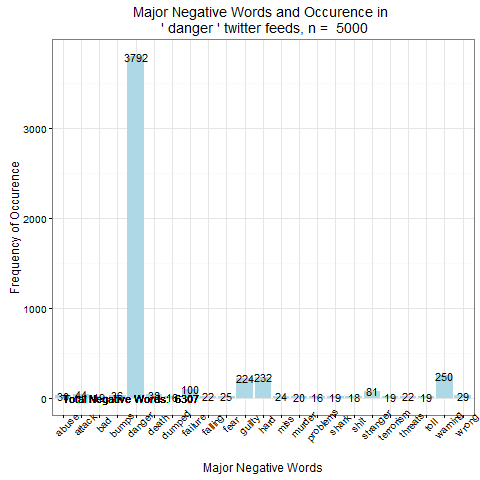
2. Danger – опасность
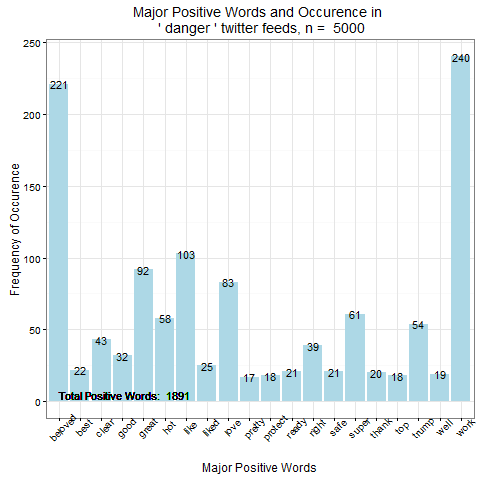
Облако позитивных слов по теме "danger" |
Облако негативных слов по теме "danger" |

Данный инструмент создан для анализа данных полученных за последние 7 дней из социальной сети Twitter, выгруженных в момент запуска скрипта. К сожалению, нет возможности выгружать более ранние данные или за любой другой промежуток времени из-за официальной политики Twitter.
Таким образом в качестве задания магистрантам можно предложить решить проблему анализа текста, полученного из файла. То есть необходимо изменить/усовершенствовать ту часть скрипта, которая отвечает за загрузку данных. Сделать это так, чтобы была возможность применить функции очистки и анализа текста без подключения к Twitter API, а при помощи загрузки из файла.
