

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Творческая работа
Титул
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ 3
ДЕСКРИПТИВНЫЙ АНАЛИЗ ИСХОДНЫХ ДАННЫХ 5
РЕГРЕССИОННЫЙ АНАЛИЗ 9
ГИПОТЕЗА О СУЩЕСТВЕННОСТИ ПРИНАДЛЕЖНОСТИ К ПЕРВЫМ 10 СТРАНАМ ПО УРОВНЮ РЕЙТИНГА 13
ВВЕДЕНИЕ
Основанный на общемировом опросе операторов на местах, таких как международные экспедиторские компании и службы экспресс-доставки, Индекс эффективности логистики измеряет удобство логистических систем 155 стран. При определении индекса учитываются количественные и качественные показатели. Индекс эффективности логистики помогает построить профили удобства и «дружелюбности» системы логистики данных стран.
Данный индекс измеряет эффективность по всей цепочке поставок логистических услуг в стране и дает оценку с двух позиций: с национальной и с международной.
- Международный индекс эффективности логистики дает качественную оценку страны по шести компонентам на основании мнения торговых партнеров – экспертов в области логистики, работающих за пределами страны. Международный индекс эффективности логистики — это суммарный показатель эффективности работы сектора логистики, который объединяет данные о шести ключевых компонентах эффективности в единый комплексный показатель: эффективность работы таможенных органов, качество инфраструктуры, простота организации международных поставок товаров, компетентность и качество логистических услуг, возможность отслеживания грузов, соблюдение сроков поставок. Национальный индекс эффективности логистики дает качественную и количественную оценку страны, на основании мнений экспертов в области логистики, работающих в стране. Он включает в себя подробную информацию о логистической среде, ключевых логистических процессах, учреждениях, информацию о времени выполнения операций и о стоимости
Цель работы. Определить на основе уравнения множественной регрессии взаимосвязь между Индексом эффективности логистики LPI и показателями социально-экономического развития для развитых стран
Зависимая переменная - LPI (индекс эффективности логистики)
Факторы (брать с лагом 2 года, те для SII2015 брать факторы 2013г):
ВВП на душу населения в ППС (GDP per capita in PPS), Производительность труда (Labour productivity per person employed) Уровень занятости (Employment rate by age group 20-64) Коэффициент Джини (Gini coefficient) Интенсивность потребления энергии в экономике (Annual average energy intensity of an economy) Выбросы углекислого газа (CO2 emissions from gaseous fuel consumption (kt))ДЕСКРИПТИВНЫЙ АНАЛИЗ ИСХОДНЫХ ДАННЫХ
Анализ проводится для выборки из 160 стран, но лишь для тех, для которых найдены прочие статистические показатели.
Исходные данные импортируем в Eviews
Построим матрицу парных корреляций
Covariance Analysis: Ordinary | ||||||
Date: 12/25/16 Time: 20:10 | ||||||
Sample (adjusted): 2 157 | ||||||
Included observations: 56 after adjustments | ||||||
Balanced sample (listwise missing value deletion) | ||||||
Correlation | ||||||
Probability | SCORE | GINI | GDP | ENERG | EMP | CO2 |
SCORE | 1.000000 | |||||
----- | ||||||
GINI | -0.359520 | 1.000000 | ||||
0.0065 | ----- | |||||
GDP | 0.840651 | -0.387933 | 1.000000 | |||
0.0000 | 0.0031 | ----- | ||||
ENERG | -0.308231 | -0.361475 | -0.193298 | 1.000000 | ||
0.0208 | 0.0062 | 0.1535 | ----- | |||
EMP | 0.105262 | 0.203014 | 0.089653 | -0.034933 | 1.000000 | |
0.4401 | 0.1335 | 0.5111 | 0.7983 | ----- | ||
CO2 | -0.039545 | 0.095643 | 0.051008 | 0.151082 | -0.119736 | 1.000000 |
0.7723 | 0.4832 | 0.7089 | 0.2664 | 0.3794 | ----- | |
На основании матрицы корреляций отметим, что после исключения пропущенных значения в выборке осталось лишь 56 наблюдений, при этом среди рассматриваемых факторов у всех уровень корреляции не относительно низкий, за исключением показателя ВВП, который имеет прямую зависимость с рассматриваемым индексом.
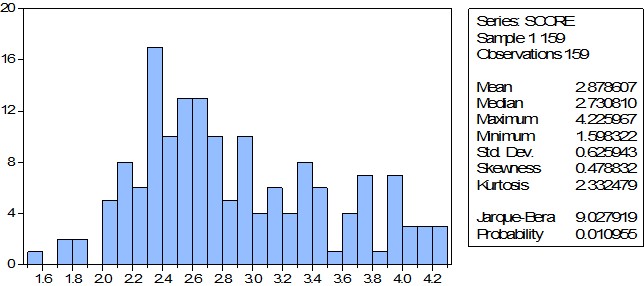
Построенная гистограмма и описательные статистики показывают, что распределение отличается от нормального, выборка однородна.
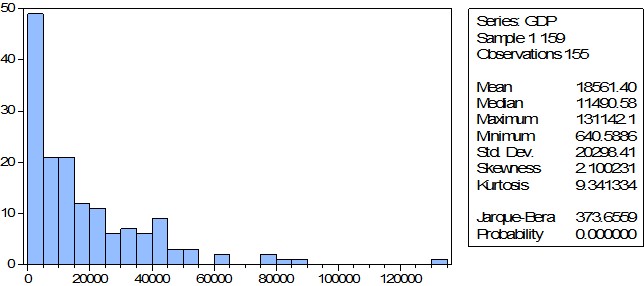
Гистограмма ВВП показывает значимое отличие от нормального распределения, при этом выборку стоит считать неоднородной, так как стандартное отклонение превышает среднее значение, ситуация в первую очередь связана с наличие выброса, то есть значением, существенно отличающимся от прочих.
Исключим его из рассмотрения.
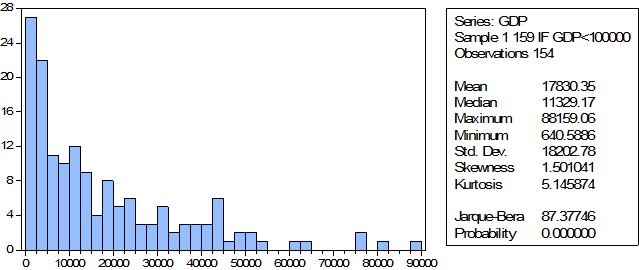
Данные получились более однородные, но в модели все еще присутствуют выбросы. Однако их исключение приведет к значительному сокращению выборки.
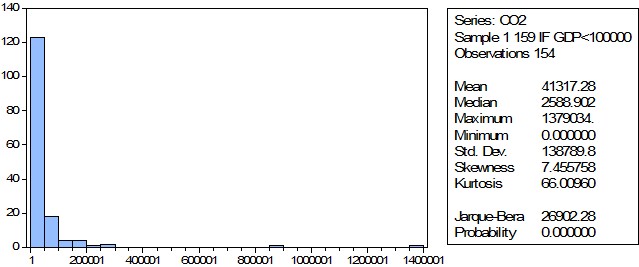
По построенной гистограмме, также можно судить о наличии выбросов.
Добавим фильтр.
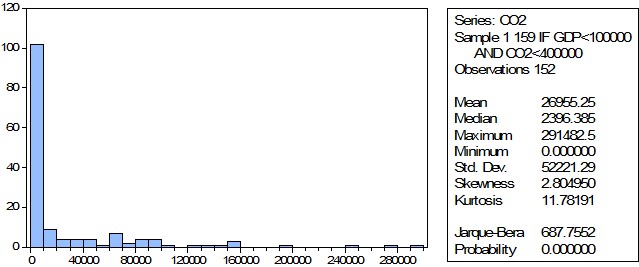
Полученная выборка более информативна
Снова построим матрицу корреляций
Covariance Analysis: Ordinary | ||||||
Date: 12/25/16 Time: 20:18 | ||||||
Sample (adjusted): 2 157 | ||||||
Included observations: 55 after adjustments | ||||||
Balanced sample (listwise missing value deletion) | ||||||
Correlation | ||||||
Probability | SCORE | GINI | GDP | ENERG | EMP | CO2 |
SCORE | 1.000000 | |||||
----- | ||||||
GINI | -0.349293 | 1.000000 | ||||
0.0090 | ----- | |||||
GDP | 0.850996 | -0.391773 | 1.000000 | |||
0.0000 | 0.0031 | ----- | ||||
ENERG | -0.290662 | -0.389841 | -0.198505 | 1.000000 | ||
0.0313 | 0.0033 | 0.1463 | ----- | |||
EMP | 0.088762 | 0.220563 | 0.091921 | -0.012721 | 1.000000 | |
0.5193 | 0.1056 | 0.5045 | 0.9266 | ----- | ||
CO2 | 0.315581 | -0.037530 | 0.129996 | -0.055754 | 0.006037 | 1.000000 |
0.0189 | 0.7856 | 0.3442 | 0.6860 | 0.9651 | ----- | |
Полученные коэффициенты имеют более высокий уровень значимости.
РЕГРЕССИОННЫЙ АНАЛИЗ
Построим модель по полному набору факторов, при этом необходимо отметить, что в исходных данных есть не все значения, они автоматически будут исключены.
Dependent Variable: SCORE | ||||
Method: Least Squares | ||||
Date: 12/25/16 Time: 20:19 | ||||
Sample: 1 159 IF GDP<100000 AND CO2<400000 | ||||
Included observations: 55 | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
GINI | -0.011011 | 0.006813 | -1.616214 | 0.1125 |
GDP | 2.47E-05 | 2.75E-06 | 8.980202 | 0.0000 |
ENERG | -0.035418 | 0.014772 | -2.397559 | 0.0204 |
EMP | 0.010783 | 0.015070 | 0.715506 | 0.4777 |
CO2 | 3.21E-06 | 1.03E-06 | 3.117629 | 0.0030 |
C | 3.075232 | 0.320429 | 9.597237 | 0.0000 |
R-squared | 0.792062 | Mean dependent var | 3.192212 | |
Adjusted R-squared | 0.770844 | S. D. dependent var | 0.584596 | |
S. E. of regression | 0.279848 | Akaike info criterion | 0.393525 | |
Sum squared resid | 3.837417 | Schwarz criterion | 0.612507 | |
Log likelihood | -4.821946 | Hannan-Quinn criter. | 0.478207 | |
F-statistic | 37.32945 | Durbin-Watson stat | 2.182339 | |
Prob(F-statistic) | 0.000000 | |||
На основании построенной модели можно сделать выводы о незначимости части факторов, в первую очередь – уровень занятости.
Проведем исключение всех незначимых факторов.
Dependent Variable: SCORE | ||||
Method: Least Squares | ||||
Date: 12/25/16 Time: 20:21 | ||||
Sample: 1 159 IF GDP<100000 AND CO2<400000 | ||||
Included observations: 152 | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
GDP | 2.20E-05 | 1.90E-06 | 11.59411 | 0.0000 |
CO2 | 2.69E-06 | 6.59E-07 | 4.083119 | 0.0001 |
C | 2.433762 | 0.047232 | 51.52731 | 0.0000 |
R-squared | 0.556389 | Mean dependent var | 2.893122 | |
Adjusted R-squared | 0.550435 | S. D. dependent var | 0.610194 | |
S. E. of regression | 0.409133 | Akaike info criterion | 1.069986 | |
Sum squared resid | 24.94108 | Schwarz criterion | 1.129668 | |
Log likelihood | -78.31897 | Hannan-Quinn criter. | 1.094231 | |
F-statistic | 93.44010 | Durbin-Watson stat | 1.812733 | |
Prob(F-statistic) | 0.000000 | |||
В построенной модели все факторы значимы, при этом модель имеет высокий уровень значимости по критерию Фишера.
Estimation Equation:
=========================
SCORE = C(1)*GDP + C(2)*CO2 + C(3)
Substituted Coefficients:
=========================
SCORE = 2.20183942745e-05*GDP + 2.69031598551e-06*CO2 + 2.43376167042
Проанализируем модель на выполнение условий.
В первую очередь построим график остатков
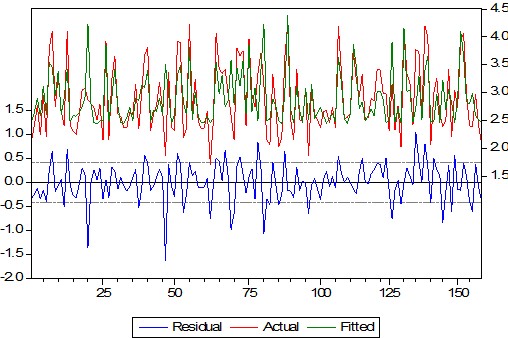
Остатки колеблются вокруг нулевого значения, поэтому можно утверждать, что остатки не смещены.
Проведем проверку на гетероскедастичность.
Heteroskedasticity Test: White | ||||
F-statistic | 5.700661 | Prob. F(5,146) | 0.0001 | |
Obs*R-squared | 24.82762 | Prob. Chi-Square(5) | 0.0002 | |
Scaled explained SS | 43.95099 | Prob. Chi-Square(5) | 0.0000 | |
Test Equation: | ||||
Dependent Variable: RESID^2 | ||||
Method: Least Squares | ||||
Date: 12/25/16 Time: 20:27 | ||||
Sample: 1 159 IF GDP<100000 AND CO2<400000 | ||||
Included observations: 152 | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 0.069288 | 0.043316 | 1.599577 | 0.1119 |
GDP | 4.69E-06 | 3.97E-06 | 1.182582 | 0.2389 |
GDP^2 | 4.95E-11 | 5.53E-11 | 0.895117 | 0.3722 |
GDP*CO2 | -4.95E-11 | 3.15E-11 | -1.571805 | 0.1182 |
CO2 | -3.13E-07 | 1.53E-06 | -0.204428 | 0.8383 |
CO2^2 | 7.15E-12 | 5.42E-12 | 1.317957 | 0.1896 |
R-squared | 0.163340 | Mean dependent var | 0.164086 | |
Adjusted R-squared | 0.134687 | S. D. dependent var | 0.316005 | |
S. E. of regression | 0.293955 | Akaike info criterion | 0.427893 | |
Sum squared resid | 12.61578 | Schwarz criterion | 0.547256 | |
Log likelihood | -26.51984 | Hannan-Quinn criter. | 0.476382 | |
F-statistic | 5.700661 | Durbin-Watson stat | 1.707822 | |
Prob(F-statistic) | 0.000078 | |||
В модели присутствует гетероскедастичность, то есть необходимо либо найти ее форму и избавиться от нее, либо учесть в робастных оценках, либо поменять функциональную форму модели.
Рассмотрим оценки в форме Уайта.
Dependent Variable: SCORE | ||||
Method: Least Squares | ||||
Date: 12/25/16 Time: 20:29 | ||||
Sample: 1 159 IF GDP<100000 AND CO2<400000 | ||||
Included observations: 152 | ||||
White heteroskedasticity-consistent standard errors & covariance | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
GDP | 2.20E-05 | 3.03E-06 | 7.266836 | 0.0000 |
CO2 | 2.69E-06 | 8.74E-07 | 3.078337 | 0.0025 |
C | 2.433762 | 0.043439 | 56.02671 | 0.0000 |
R-squared | 0.556389 | Mean dependent var | 2.893122 | |
Adjusted R-squared | 0.550435 | S. D. dependent var | 0.610194 | |
S. E. of regression | 0.409133 | Akaike info criterion | 1.069986 | |
Sum squared resid | 24.94108 | Schwarz criterion | 1.129668 | |
Log likelihood | -78.31897 | Hannan-Quinn criter. | 1.094231 | |
F-statistic | 93.44010 | Durbin-Watson stat | 1.812733 | |
Prob(F-statistic) | 0.000000 | |||
В полученной модели изменились только стандартные ошибки, так как при наличии гетероскедастичности оценки остаются несмещенными.
Проведем проверку на нелинейность модели.
Проведем для этого тест Рамсея
Ramsey RESET Test | ||||
Equation: EQ02 | ||||
Specification: SCORE GDP CO2 C | ||||
Omitted Variables: Powers of fitted values from 2 to 3 | ||||
Value | df | Probability | ||
F-statistic | 10.03507 | (2, 147) | 0.0001 | |
Likelihood ratio | 19.45314 | 2 | 0.0001 | |
F-test summary: | ||||
Sum of Sq. | df | Mean Squares | ||
Test SSR | 2.996173 | 2 | 1.498087 | |
Restricted SSR | 24.94108 | 149 | 0.167390 | |
Unrestricted SSR | 21.94491 | 147 | 0.149285 | |
Unrestricted SSR | 21.94491 | 147 | 0.149285 | |
LR test summary: | ||||
Value | df | |||
Restricted LogL | -78.31897 | 149 | ||
Unrestricted LogL | -68.59240 | 147 | ||
Unrestricted Test Equation: | ||||
Dependent Variable: SCORE | ||||
Method: Least Squares | ||||
Date: 12/25/16 Time: 20:31 | ||||
Sample: 1 159 IF GDP<100000 AND CO2<400000 | ||||
Included observations: 152 | ||||
White heteroskedasticity-consistent standard errors & covariance | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
GDP | -0.000217 | 0.000248 | -0.878115 | 0.3813 |
CO2 | -2.75E-05 | 3.06E-05 | -0.897732 | 0.3708 |
C | -14.42307 | 15.81326 | -0.912087 | 0.3632 |
FITTED^2 | 3.951528 | 3.585253 | 1.102162 | 0.2722 |
FITTED^3 | -0.459884 | 0.374128 | -1.229218 | 0.2210 |
R-squared | 0.609680 | Mean dependent var | 2.893122 | |
Adjusted R-squared | 0.599059 | S. D. dependent var | 0.610194 | |
S. E. of regression | 0.386374 | Akaike info criterion | 0.968321 | |
Sum squared resid | 21.94491 | Schwarz criterion | 1.067791 | |
Log likelihood | -68.59240 | Hannan-Quinn criter. | 1.008729 | |
F-statistic | 57.40361 | Durbin-Watson stat | 1.830656 | |
Prob(F-statistic) | 0.000000 | |||
Данный тест свидетельствует о предпочтении линейной формы модели.
ГИПОТЕЗА О СУЩЕСТВЕННОСТИ ПРИНАДЛЕЖНОСТИ К ПЕРВЫМ 10 СТРАНАМ ПО УРОВНЮ РЕЙТИНГА
Для этого введем фиктивную переменную, равную 1 для первых 10 стран и 0 для остальных.
Проведем тест на наличие структурных изменений.
Factor Breakpoint Test: TOP | |||
Null Hypothesis: No breaks at specified breakpoints | |||
Varying regressors: All equation variables | |||
Equation Sample: 1 159 IF GDP<100000 AND CO2<400000 | |||
F-statistic | 6.814229 | Prob. F(3,146) | 0.0002 |
Log likelihood ratio | 19.91875 | Prob. Chi-Square(3) | 0.0002 |
Wald Statistic | 331.7819 | Prob. Chi-Square(3) | 0.0000 |
Factor values: | TOP = 0 | ||
TOP = 1 | |||
В данном случае нулевая гипотеза значима, то есть никаких особенностей при извучении зависимотсти для стран первой десятки не существует
