
Многомерная визуализация
Одним из основных достоинств R служит удивительное разнообразие типов графиков, которые он может построить. R в этом смысле — один из рекордсменов. В базовом наборе есть несколько десятков типов графиков.
Базовые графики могут передавать более содержательную информацию с добавлением таких характеристик, как цвет, размер, а также с помощью использования такие операции, как масштабирование, агрегирование и интерактивность. Эти дополнения позволяют рассматривать более двух переменных одновременно. Преимущество этих дополнений заключается в том, что они особенно эффективны при отображении сложной информации в удобной для восприятия форме. Цель состоит в том, чтобы сделать информацию более понятной, а не просто представлять данные в более высоких измерениях (таких, как трехмерные графики, которые обычно оказываются неэффективными для визуализации).
Добавление дополнительных характеристик: цвет, размер, фигура, несколько панелей, и анимация
Для того, чтобы включить дополнительную характеристику в график, необходимо определить тип добавляемой переменной. Если нужно соотнести данные к определённой категории, то лучший способ представления такой категориальной информации – это использование различных цветов, фигур или нескольких панелей. Для визуализации дополнительной числовой информации можно использовать интенсивность цвета или размер. Временные данные могут быть добавлены в виде анимации.
Первое что надо сделать перед чтением данных — это убедиться, что текущая директория в R и та директория, где находятся данные одно и то же. Для этого в запущенной сессии R назначим и проверим рабочии? директории?:
setwd("C:/Users/aysilu/Documents/lecture_AD ")
getwd()
Далее следует проверить, а есть ли в текущей директории нужный файл:
> dir()
[1] "computers. csv"
Вот теперь можно и загрузить данные.
Подготовка данных для визуализации
Используем набор данных, описывающих конфигурации компьютеров. Информация была взята из репрозитория данных
http://archive. ics. uci. edu/ml/datasets/Computer+Hardware.
Рассмотрим данные.
Attribute Information:
1. vendor name: 30 - производитель
2. Model Name: many unique symbols - модель
3. MYCT: machine cycle time in nanoseconds (integer) - время машинного цикла
4. MMIN: minimum main memory in kilobytes (integer) - минимальный размер памяти
5. MMAX: maximum main memory in kilobytes (integer) - максимальный размер памяти
6. CACH: cache memory in kilobytes (integer) - кэш
7. CHMIN: minimum channels in units (integer) - минимальная пропускная способность
8. CHMAX: maximum channels in units (integer) – максимальная пропускная способность
9. PRP: published relative performance (integer) – заявленная производительность
10. ERP: estimated relative performance from the original article (integer) - вычисленная производительность
За чтение табличных текстовых данных из файла отвечает команда read. table():
computers <- read. table(file = "computers. csv", header = TRUE, sep = ",")
Перед чтением нужно знать в каком формате хранятся данные. То есть то, что у столбцов есть имена (head=TRUE) и разделителем является точка с запятой (sep=";").
Чтобы посмотреть содержимое файла не выходя из R, можно воспользоваться функцией file. show():
file. show("computers. csv")
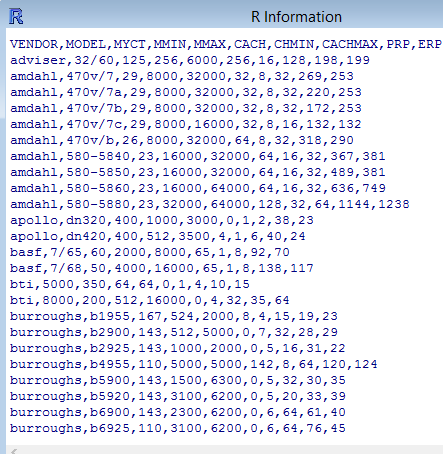
Со структурой этих данных можно ознакомиться при помощи стандартной команды str():
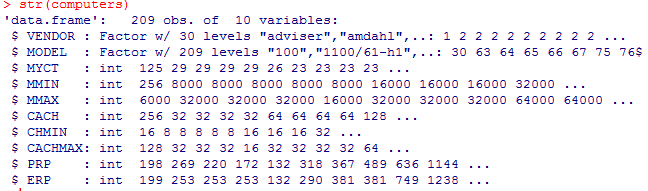
Многомерную визуализацию будем демонстрировать с помощью пакета ggplot2.
Установка пакета ggplot2
Для установки необходимо удостовериться в наличии последней версии R и подключении к сети Интернет.
Далее необходимо выполнить команду:
install. packages("ggplot2")
Перед использованием ggplot2 необходимо загрузить его при помощи команды:
library(ggplot2)
Построение графиков
Построим график рассеяния с помощью функции qplot():
x и y — значения на координатных осях, data-таблица с данными
qplot(x=MYCT, y=ERP, data= computers)
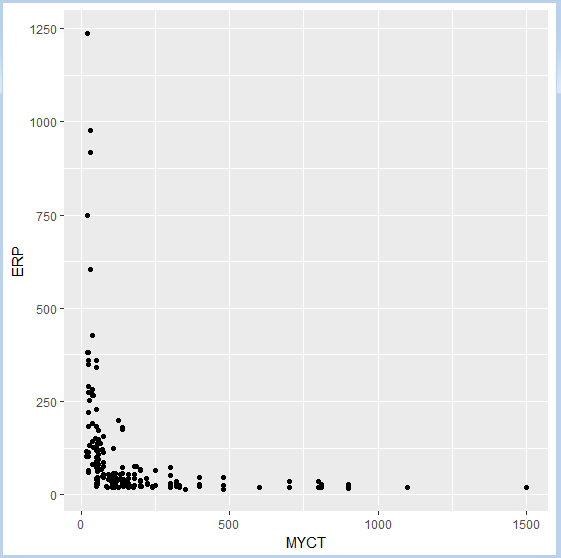
Рис.1. График рассеяния |
Обычно при работе с данными большого объема точки на диаграммах рассеяния накладываются друг на друга, что затрудняет выявление заключенных в данных закономерностей. Полезным приемом для облегчения восприятия таких графиков является использование полупрозрачного цвета. Этот прием можно реализовать при помощи аргумента alpha, который принимает значения от 0 (полная прозрачность) до 1 (полная непрозрачность).
qplot(MYCT, ERP, alpha = I(1/2), data = computers)
qplot(MYCT, ERP, alpha = I(1/8), data = computers)
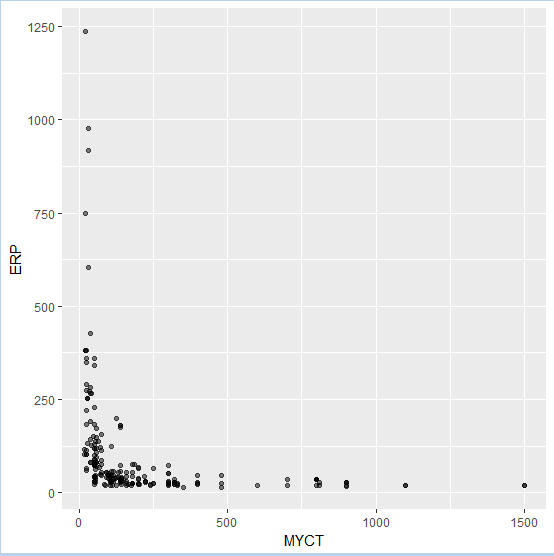
Рис.2. Изменение прозрачности точек на графике рассеяния |
К графику зависимости между двумя количественными переменными можно добавить информацию о третьей - качественной переменной, изменяя цвет точек (аргумент colour) или их форму (аргумент shape).
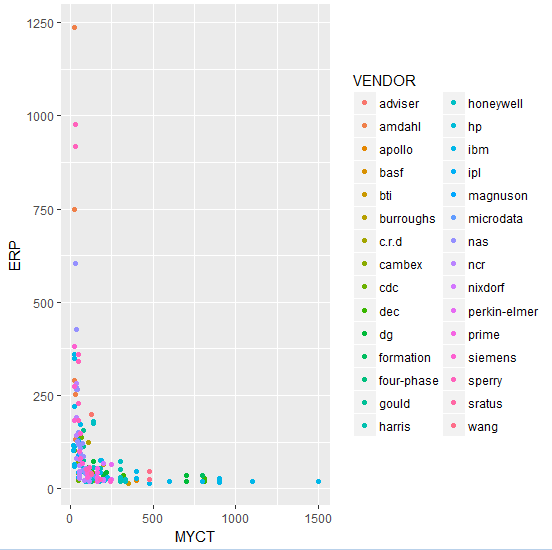
qplot(MYCT, ERP, data = computers, colour = VENDOR)
|
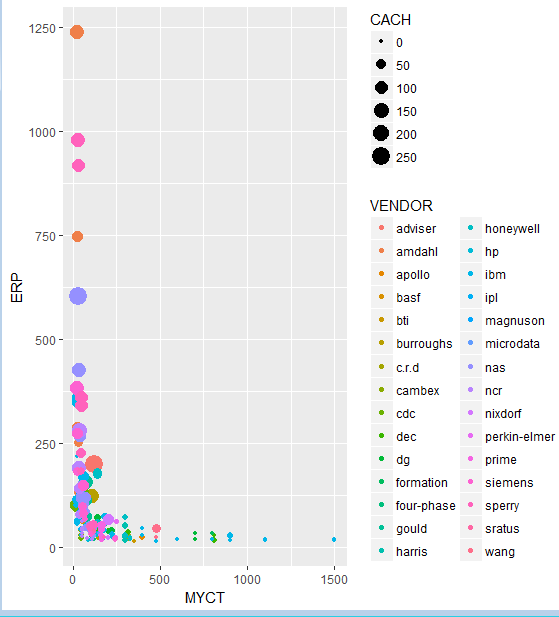
Рис.3 Изменение цвета точек на графике рассеяния Здесь мы указали для наших точек визуальное свойство “цвет”, основываясь на категориальной переменной VENDOR. Легенда добавляется автоматически. Выбранный нами объект принимает разные визуальные свойства: qplot(MYCT, ERP, data = computers, colour = VENDOR, size = CACH) |
|
Рис.4.Изменение цвета точек и размера точек на графике рассеяния |
Для создания столбиковых (= "столбчатых", реже "линейчатых"; англ. bar plots или bar charts) диаграмм в системе R служит функция barplot().
Стоит задача отобразить средние значения машинного цикла для вычисленной производительности, в виде столбиковой диаграммы. Эти средние значения можно быстро рассчитать для каждой группы при помощи функции tapply(). Результат вычислений сохраним в векторе Means:
comp<-computers[c(3,10)] выбираем необходимые столбцы
Means <- tapply(comp$MYCT, comp$ERP, mean)
barplot(Means, col = "steelblue",xlab = "ERP",ylab = "MYCT")
строим столбиковую диаграмму
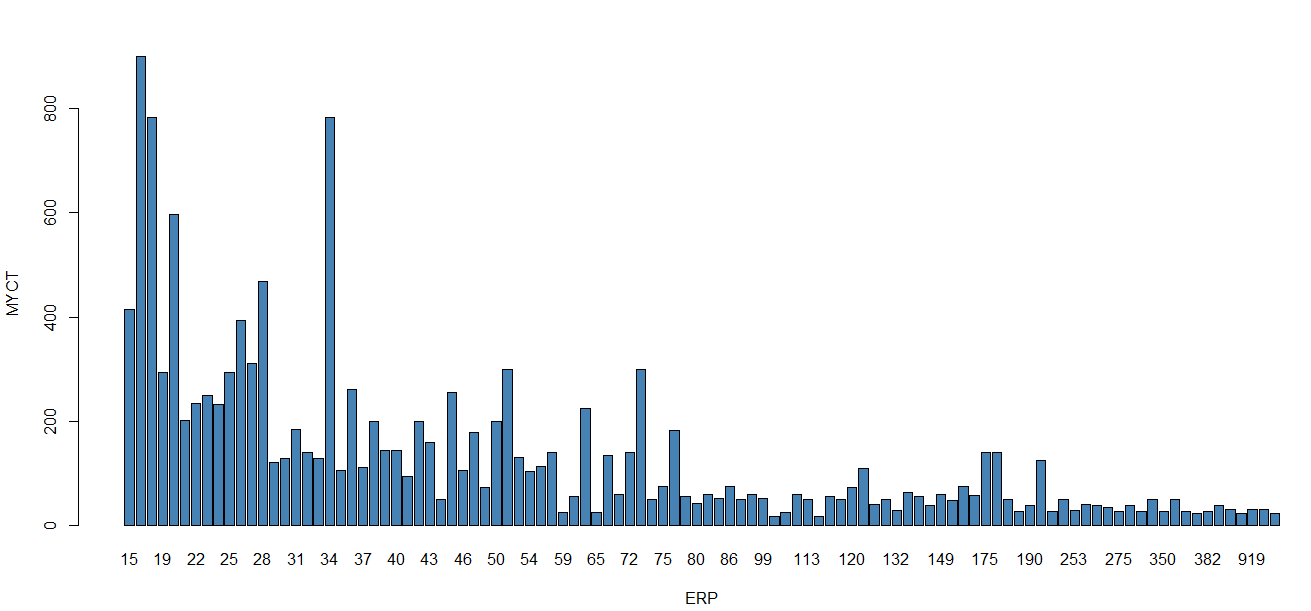
Рисунок 5. Столбиковая диаграмма |
Заметно, что чем выше машинный цикл, тем ниже вычисленная производительность.
Графические опции
Графика в R настраивается в очень широких пределах.
Один из способов настройки — это видоизменение графических опций, встроенных в R. Вот, к примеру, распространённая задача: нарисовать две гистограммы
одну под другой на одном рисунке. Чтобы это сделать, надо изменить исходные опции, а именно разделить пространство рисунка на две части, примерно так:
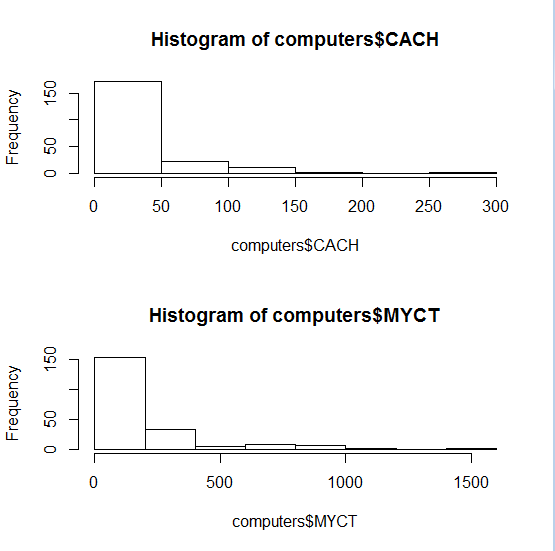
Рисунок 6. Гистограммы
# Создаётся eps-файл размером 6 на 6 дюймов
postscript("2hist. eps",width=6.0,height=6.0,
+ horizontal=FALSE, onefile=FALSE, paper="special")
#onefile - если true (по умолчанию) разрешает несколько фигур в одном файле.
# Изменяется одно из значений по умолчанию
old. par <- par(mfrow=c(2,1))
hist(computers$CACH)
hist(computers$MYCT)
# Восстанавливаем старое значение по умолчанию
par(old. par)
Ключевая команда здесь par() — изменяется один из её параметров, mfrow, который регулирует сколько изображений и как будет размещено на «листе». Значение mfrow по умолчанию — c(1,1), то есть один график по вертикали и один по горизонтали. Чтобы не печатать каждый раз команду par() без аргументов (для того чтобы выяснить умалчиваемые значения каждого из 71 параметра), мы «запомнили» старое значение в объекте old. par, а в конце вернули состояние к запомненному. То, что команда hist() строит гистограмму, очевидно из
названия.
Мы говорили, что цвет, форма, размер точек могут быть использованы для включения дополнительных категорий данных. Однако при условии, когда количество категорий большое, лучшей альтернативой является использование множества панелей. Создание множества панелей (также называется «подвязка») делается путем расслаивания наблюдений в соответствии с категориальной переменной и создания отдельного графика (того же типа) для каждой категории.
Специальный график, который использует точечные диаграммы с множеством панелей, называется диаграммой матрицы рассеивания. В ней все парные точечные диаграммы отображены на одном дисплее. Панели в матрице организованы так, что каждый столбец и каждая строка соответствуют одной переменной, таким образом, пересечения создают все возможные попарные точечные диаграммы. Диаграмма матрицы рассеивания полезна при неконтролируемом обучении для изучения ассоциаций между численными переменными, для обнаружения выбросов и определения кластеров
Построения матричных диаграмм рассеяния в R осуществляется с помощью функции pairs(), входящей в базовую версию R:
comp2<-computers[c(3:10)]
pairs(comp2)

Рис.7 Матричная диаграмма рассеяния
Функция pairs() имеет ряд аргументов для тонкой настройки графика. Например, для облегчения интерпретации характера связи между анализируемыми переменными мы можем добавить сглаживающую кривую к каждой диаграмме рассеяния, с помощью который хорошо виден общий тренд (аргумент panel со значением panel. smooth):
pairs(comp2,panel = panel. smooth)
|
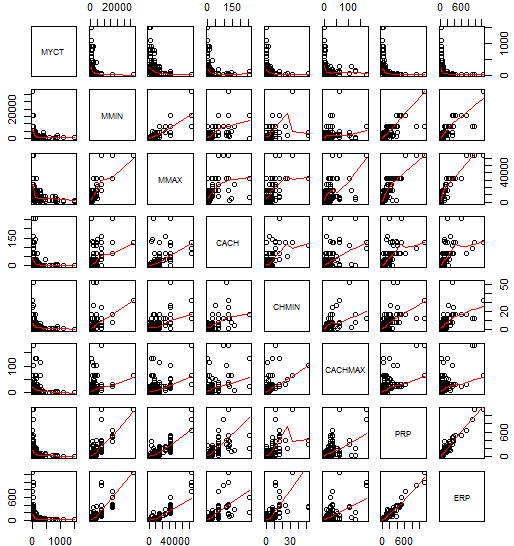
Рис.8 Добавление сглаживающей прямой в матричную диаграмму рассеяния Функция ggpairs() из пакета GGally также позволяет строить матричные диаграммы рассеяния: ggpairs(comp2)
Рис.9 Матричная диаграмма рассеяния с помощью пакета GGally На Рис.9 показан пример диаграммы матрицы рассеивания с ERP(или PRP) и шестью предикторами. Здесь под диагональю находятся точечные диаграммы. Имя переменной указывает на переменную оси y, например, все графики на нижней строке имеют ERP на оси y (что позволяет изучить индивидуальные связи вида результат – предиктор). Мы можем увидеть различные типы отношений разных форм (например, экспоненциальное соотношение между MYCT и ERP(или PRP) и линейное соотношение между ERP и PRP), которые могут указывать на необходимые трансформации. По диагонали, где задействована только одна переменная, изображено распределение частоты для этой переменной. Над диагональю расположены коэффициенты корреляции, соответствующие двум переменным. |

Также важной характеристикой при отображении данных является анимация, которая используется при добавлении временного измерения в график, то есть для того, чтобы показать, как информация изменяется со временем. Известный пример - анимированные диаграммы рассеяния Рослинга, показывающие, как менялось количество населения по годам
Для демонстрации временной переменной на графике используется анимация.
Также важной характеристикой при отображении данных является анимация
Наконец, пришли к тому, что добавление временной меры к диаграмме, с целью показать, как информация изменяется во времени, может быть достигнуто с помощью анимации. Известный пример – анимированные диаграммы рассеяния Рослинга, показывающие, как менялась мировая демография по годам. Однако, анимации такого типа неэффективны для исследования данных, поэтому чаще используются для «статического повествования».
https://plot. ly/~QingyangWang/1
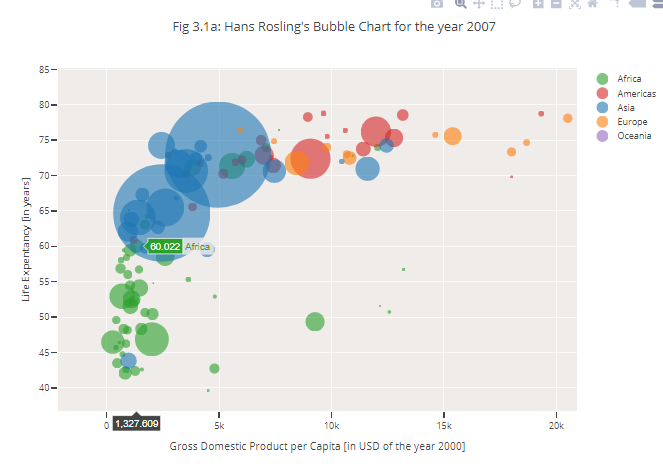
https://www. gapminder. org/tools/#_data_/_lastModified:1522161107440;&chart-type=map.
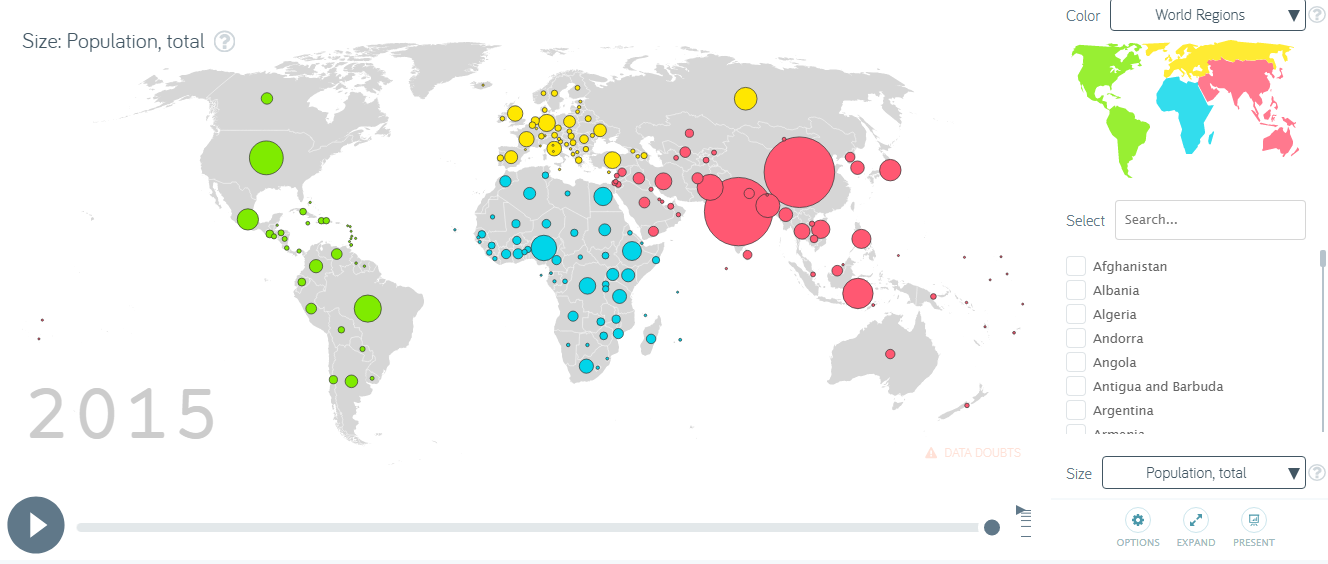
Рис. 10 Анимированная диаграмма рассеяния Рослинга |
Задания для выполнения:
Нарисовать график рассеяния с с помощью функции qplot(). Добавляйте различные характеристики (цвет, форма, размер и т. д.). Основная идея использования пакета ggplot2 такова: график создаётся слой за слоем и комбинируется так, чтобы получить желаемый вид графического отображения. Выполните пункт 1. с использованием пакета ggplot2, задавая разные составляющие графика и добавляя их друг к другу, используя оператор +. Дополнительную информацию можно найти по ссылке https://r-datascience. ru/ggplot2_guide/ Построить матричную диаграмму рассеяния с помощью функций pairs() и ggpairs() Зайти и зарегистрироваться на сайте https://plot. ly/ , самостоятельно рассмотреть различные виды графиков (в том числе анимированную диаграмму рассеяния Рослинга).Литературные источники:
«Data Mining for Business Analytics: Concepts, Techniques, and Applications in R», Galit Shmueli, Peter C. Bruce, Inbal Yahav, Nitin R. Patel, Kenneth C. Lichtendahl Jr. Wickham, Hadley. ggplot2: Elegant Graphics for Data Analysis. Dordrecht, Heibelberg, London, New York: Springer, 2009. https://r-datascience. ru/ggplot2_guide/Листинг
setwd("C:/Users/aysilu/Documents/lecture_AD ")
getwd()
dir()
computers <- read. table(file = "computers. csv", header = TRUE, sep = ",")
file. show("computers. csv")
str(computers)
qplot(x=MYCT, y=ERP, data=computers)
qplot(MYCT, ERP, alpha = I(1/2), data = computers)
qplot(MYCT, ERP, alpha = I(1/8), data = computers)
qplot(MYCT, ERP, data = computers, colour = VENDOR)
qplot(MYCT, ERP, data = computers, colour = VENDOR, size = CACH)
comp<-computers[c(3,10)]
Means <- tapply(comp$MYCT, comp$ERP, mean)
Means
barplot(Means, col = "steelblue",xlab = "ERP",ylab = "MYCT")
comp2<-computers[c(3:10)]
pairs(comp2)
pairs(comp2,panel = panel. smooth)
ggpairs(comp2)
postscript("2hist. eps",width=6.0,height=6.0,
+ horizontal=FALSE, onefile=FALSE, paper="special")
old. par <- par(mfrow=c(2,1))
hist(computers$CACH)
hist(computers$MYCT)
par(old. par)
